Hoge beschikbaarheid is een hoog percentage van de tijd dat het systeem werkt en reageert volgens de zakelijke behoeften. Voor productiedatabasesystemen heeft het doorgaans de hoogste prioriteit om deze dicht bij 100% te houden. We bouwen databaseclusters om alle single point of failure te elimineren. Als een instantie niet meer beschikbaar is, moet een ander knooppunt de werklast kunnen overnemen en van daaruit verder kunnen gaan. In een perfecte wereld zou een databasecluster al onze problemen met de systeembeschikbaarheid oplossen. Helaas, hoewel alles er op papier goed uitziet, is de realiteit vaak anders. Dus waar kan het fout gaan?
Transactionele databasesystemen worden geleverd met geavanceerde opslagengines. Door gegevens consistent te houden over meerdere knooppunten, wordt deze taak veel moeilijker. Clustering introduceert een aantal nieuwe variabelen die sterk afhankelijk zijn van het netwerk en de onderliggende infrastructuur. Het is niet ongebruikelijk dat een zelfstandige database-instantie die goed werkte op een enkel knooppunt, plotseling slecht presteert in een clusteromgeving.
Onder het aantal dingen dat de beschikbaarheid van clusters kan beïnvloeden, spelen latentieproblemen een cruciale rol. Wat is echter de latentie? Is het alleen gerelateerd aan het netwerk?
De term "latentie" verwijst in feite naar verschillende soorten vertragingen bij de verwerking van gegevens. Het is hoe lang het duurt voordat een stukje informatie van het ene podium naar het andere gaat.
In deze blogpost zullen we kijken naar de twee belangrijkste high-availability-oplossingen voor MySQL en MariaDB, en hoe ze elk kunnen worden beïnvloed door latentieproblemen.
Aan het einde van het artikel bekijken we moderne load balancers en bespreken we hoe ze u kunnen helpen bij het oplossen van bepaalde soorten latentieproblemen.
In een vorig artikel schreef mijn collega Krzysztof Książek over "Omgaan met onbetrouwbare netwerken bij het maken van een HA-oplossing voor MySQL of MariaDB". U vindt tips die u kunnen helpen bij het ontwerpen van uw productieklare HA-architectuur en om enkele van de hier beschreven problemen te voorkomen.
Master-Slave-replicatie voor hoge beschikbaarheid.
MySQL master-slave-replicatie is waarschijnlijk het meest populaire databaseclustertype ter wereld. Een van de belangrijkste dingen die u wilt bewaken terwijl u uw master-slave-replicatiecluster uitvoert, is de slave-vertraging. Afhankelijk van uw toepassingsvereisten en de manier waarop u uw database gebruikt, kan de replicatielatentie (slave-lag) bepalen of de gegevens kunnen worden gelezen vanaf het slave-knooppunt of niet. Gegevens vastgelegd op master maar nog niet beschikbaar op een asynchrone slave betekent dat de slave een oudere status heeft. Als het niet goed is om van een slave te lezen, moet je naar de master gaan, en dat kan de prestaties van de applicatie beïnvloeden. In het ergste geval kan uw systeem niet alle werkbelasting op een master aan.
Slavelag en verouderde gegevens
Om de status van de master-slave-replicatie te controleren, moet u beginnen met het onderstaande commando:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Met behulp van de bovenstaande informatie kunt u bepalen hoe goed de algehele replicatielatentie is. Hoe lager de waarde die u ziet in "Seconds_Behind_Master", hoe beter de gegevensoverdrachtsnelheid voor replicatie.
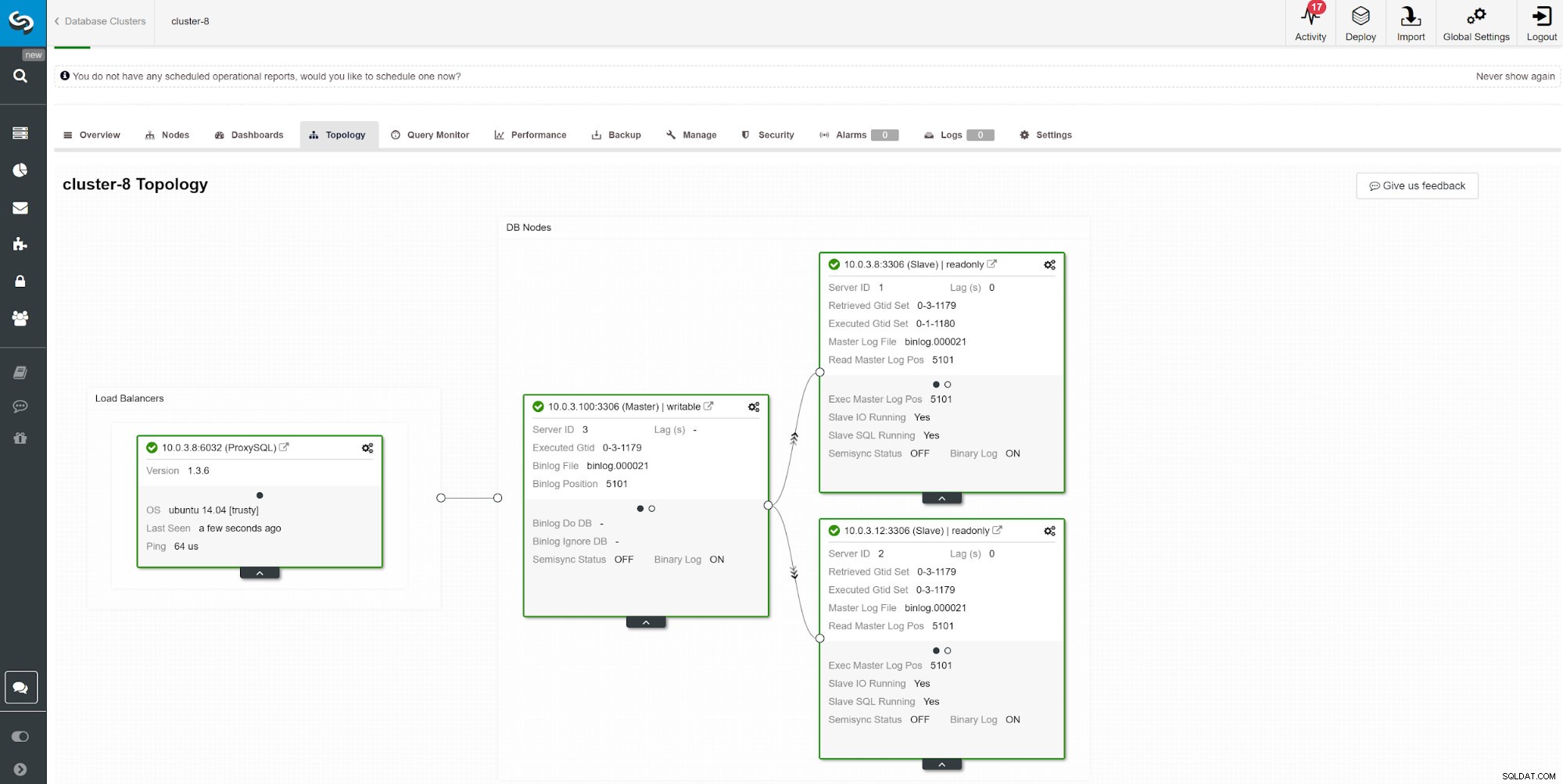 Een andere manier om slaafvertraging te controleren, is door ClusterControl-replicatiebewaking te gebruiken. In deze schermafbeelding kunnen we de replicatiestatus van asymchoronous Master-Slave (2x) Cluster met ProxySQL zien.
Een andere manier om slaafvertraging te controleren, is door ClusterControl-replicatiebewaking te gebruiken. In deze schermafbeelding kunnen we de replicatiestatus van asymchoronous Master-Slave (2x) Cluster met ProxySQL zien. Er zijn een aantal dingen die de replicatietijd kunnen beïnvloeden. Het meest voor de hand liggend is de netwerkdoorvoer en hoeveel gegevens u kunt overbrengen. MySQL wordt geleverd met meerdere configuratie-opties om het replicatieproces te optimaliseren. De essentiële replicatiegerelateerde parameters zijn:
- Parallel toepassen
- Logisch klokalgoritme
- Compressie
- Selectieve master-slave-replicatie
- Replicatiemodus
Parallel toepassen
Het is niet ongebruikelijk om replicatie-afstemming te starten met het inschakelen van parallelle procestoepassing. De reden daarvoor is dat MySQL standaard wordt gebruikt met sequentiële binaire logtoepassing, en een typische databaseserver wordt geleverd met verschillende CPU's om te gebruiken.
Om sequentiële logboektoepassing te omzeilen, bieden zowel MariaDB als MySQL parallelle replicatie. De implementatie kan per leverancier en versie verschillen. bijv. MySQL 5.6 biedt parallelle replicatie zolang een schema de query's scheidt, terwijl MariaDB (vanaf versie 10.0) en MySQL 5.7 beide parallelle replicatie over schema's kunnen afhandelen. Verschillende leveranciers en versies hebben hun beperkingen en functies, dus controleer altijd de documentatie.
Het uitvoeren van query's via parallelle slave-threads kan uw replicatiestroom versnellen als u veel schrijft. Als u dat echter niet bent, kunt u het beste vasthouden aan de traditionele single-threaded replicatie. Om parallelle verwerking in te schakelen, wijzigt u de slave_parallel_workers in het aantal CPU-threads dat u bij het proces wilt betrekken. Het wordt aanbevolen om de waarde lager te houden dan het aantal beschikbare CPU-threads.
Parallelle replicatie werkt het beste met de groeps-commits. Voer de volgende query uit om te controleren of er groepstoezeggingen plaatsvinden.
show global status like 'binlog_%commits';Hoe groter de verhouding tussen deze twee waarden, hoe beter.
Logische klok
De slave_parallel_type=LOGICAL_CLOCK is een implementatie van een Lamport-klokalgoritme. Bij gebruik van een multithreaded slave specificeert deze variabele de methode die wordt gebruikt om te beslissen welke transacties parallel mogen worden uitgevoerd op de slave. De variabele heeft geen effect op slaves waarvoor multithreading niet is ingeschakeld, dus zorg ervoor dat slave_parallel_workers hoger dan 0 is ingesteld.
MariaDB-gebruikers moeten ook de optimistische modus controleren die in versie 10.1.3 is geïntroduceerd, omdat deze ook betere resultaten kan opleveren.
GTID
MariaDB wordt geleverd met een eigen implementatie van GTID. De volgorde van MariaDB bestaat uit een domein, server en transactie. Domeinen maken replicatie van meerdere bronnen met een duidelijke ID mogelijk. Er kunnen verschillende domein-ID's worden gebruikt om het gedeelte van de gegevens dat niet in orde is (parallel) te repliceren. Zolang het goed is voor uw toepassing, kan dit de replicatielatentie verminderen.
De vergelijkbare techniek is van toepassing op MySQL 5.7, die ook de multisource-master en onafhankelijke replicatiekanalen kan gebruiken.
Compressie
CPU-kracht wordt in de loop van de tijd goedkoper, dus het gebruik ervan voor binlog-compressie kan een goede optie zijn voor veel database-omgevingen. De parameter slave_compressed_protocol vertelt MySQL om compressie te gebruiken als zowel master als slave dit ondersteunen. Deze parameter is standaard uitgeschakeld.
Vanaf MariaDB 10.2.3 kunnen geselecteerde gebeurtenissen in het binaire logboek optioneel worden gecomprimeerd om de netwerkoverdrachten op te slaan.
Replicatie-indelingen
MySQL biedt verschillende replicatiemodi. Door het juiste replicatieformaat te kiezen, wordt de tijd die nodig is om gegevens tussen de clusterknooppunten door te geven tot een minimum beperkt.
Multimaster-replicatie voor hoge beschikbaarheid
Sommige applicaties kunnen het zich niet veroorloven om op verouderde gegevens te werken.
In dergelijke gevallen wilt u mogelijk consistentie tussen de knooppunten afdwingen met synchrone replicatie. Gegevens synchroon houden vereist een extra plug-in en voor sommigen is Galera Cluster de beste oplossing op de markt.
Galera-cluster wordt geleverd met wsrep API die verantwoordelijk is voor het verzenden van transacties naar alle knooppunten en het uitvoeren ervan volgens een clusterbrede volgorde. Dit blokkeert de uitvoering van volgende query's totdat het knooppunt alle schrijfsets uit de applier-wachtrij heeft toegepast. Hoewel het een goede oplossing is voor consistentie, kunt u enkele architecturale beperkingen tegenkomen. De veelvoorkomende latentieproblemen kunnen te maken hebben met:
- Het langzaamste knooppunt in het cluster
- Horizontale schaal- en schrijfbewerkingen
- Gelokaliseerde clusters
- Hoge ping
- Transactiegrootte
Het langzaamste knooppunt in het cluster
Door het ontwerp kunnen de schrijfprestaties van het cluster niet hoger zijn dan de prestaties van het langzaamste knooppunt in het cluster. Begin uw clusterbeoordeling door de machinebronnen te controleren en de configuratiebestanden te controleren om er zeker van te zijn dat ze allemaal op dezelfde prestatie-instellingen draaien.
Parallisatie
Parallelle threads garanderen geen betere prestaties, maar kunnen de synchronisatie van nieuwe knooppunten met het cluster versnellen. De status wsrep_cert_deps_distance vertelt ons de mogelijke mate van parallellisatie. Het is de waarde van de gemiddelde afstand tussen de hoogste en laagste seqno-waarden die mogelijk parallel kan worden toegepast. U kunt de statusvariabele wsrep_cert_deps_distance gebruiken om het maximale aantal mogelijke slave-threads te bepalen.
Horizontale schaling
Door meer knooppunten in het cluster toe te voegen, hebben we minder punten die kunnen mislukken; de informatie moet echter over meerdere instanties gaan totdat deze is vastgelegd, wat de responstijden vermenigvuldigt. Als u schaalbare schrijfbewerkingen nodig hebt, overweeg dan een architectuur op basis van sharding. Een goede oplossing kan een Spider-opslagengine zijn.
Om de informatie die tussen de clusterknooppunten wordt gedeeld te verminderen, kunt u in sommige gevallen overwegen om één schrijver tegelijk te gebruiken. Het is relatief eenvoudig te implementeren tijdens het gebruik van een load balancer. Als je dit handmatig doet, zorg er dan voor dat je een procedure hebt om de DNS-waarde te wijzigen wanneer je writer-node uitvalt.
Gelokaliseerde clusters
Hoewel Galera Cluster synchroon is, is het mogelijk om een Galera Cluster in datacenters te implementeren. Synchrone replicatie zoals MySQL Cluster (NDB) implementeert een commit in twee fasen, waarbij berichten naar alle knooppunten in een cluster worden verzonden in een 'prepare'-fase, en een andere set berichten wordt verzonden in een 'commit'-fase. Deze aanpak is meestal niet geschikt voor geografisch ongelijksoortige knooppunten, vanwege de vertragingen bij het verzenden van berichten tussen knooppunten.
Hoge ping
Galera Cluster met de standaardinstellingen kan de hoge netwerklatentie niet goed aan. Als je een netwerk hebt met een node die een hoge pingtijd laat zien, overweeg dan om de parameters evs.send_window en evs.user_send_window te wijzigen. Deze variabelen definiëren het maximale aantal datapakketten dat tegelijkertijd wordt gerepliceerd. Voor WAN-configuraties kan de variabele worden ingesteld op een aanzienlijk hogere waarde dan de standaardwaarde van 2. Het is gebruikelijk om deze in te stellen op 512. Deze parameters maken deel uit van wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Transactiegrootte
Een van de dingen waar u rekening mee moet houden bij het uitvoeren van Galera Cluster, is de omvang van de transactie. Het vinden van de balans tussen transactieomvang, performance en Galera-certificeringsproces is iets dat u in uw aanvraag moet inschatten. Meer informatie hierover vindt u in het artikel Hoe de prestaties van Galera Cluster voor MySQL of MariaDB te verbeteren door Ashraf Sharif.
Load Balancer Causale Consistentie Leest
Zelfs met het minimale risico op gegevenslatentieproblemen, kan standaard MySQL asynchrone replicatie geen consistentie garanderen. Het is nog steeds mogelijk dat de gegevens nog niet naar slave zijn gerepliceerd terwijl uw toepassing deze vanaf daar leest. Synchrone replicatie kan dit probleem oplossen, maar het heeft architectuurbeperkingen en past mogelijk niet bij uw toepassingsvereisten (bijvoorbeeld intensieve bulkschrijfbewerkingen). Dus hoe het te overwinnen?
De eerste stap om het lezen van verouderde gegevens te voorkomen, is de toepassing bewust te maken van replicatievertraging. Het is meestal geprogrammeerd in applicatiecode. Gelukkig zijn er moderne load balancers voor databases met de ondersteuning van adaptieve queryrouting op basis van GTID-tracking. De meest populaire zijn ProxySQL en Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader stelt ProxySQL in staat om in realtime te weten welke GTID is uitgevoerd op elke MySQL-server, slaves en master zelf. Hierdoor weet ProxySQL onmiddellijk op welke server de query kan worden uitgevoerd wanneer een client een read uitvoert die causaal consistente reads moet bieden. Als om welke reden dan ook de schrijfbewerkingen nog niet op een slave zijn uitgevoerd, weet ProxySQL dat de schrijver op de master is uitgevoerd en stuurt de read daarheen.
Maxschaal 2,3
MariaDB introduceerde casual reads in Maxscale 2.3.0. De manier waarop het werkt, is vergelijkbaar met ProxySQL 2.0. Als causal_reads zijn ingeschakeld, worden alle daaropvolgende leesbewerkingen op slave-servers uitgevoerd op een manier die voorkomt dat replicatievertraging de resultaten beïnvloedt. Als de slave de master niet binnen de geconfigureerde tijd heeft ingehaald, wordt de query opnieuw uitgevoerd op de master.