Hoge beschikbaarheid is tegenwoordig een must, aangezien de meeste organisaties het niet kunnen toestaan dat hun gegevens verloren gaan. Hoge beschikbaarheid komt echter altijd met een prijskaartje (dat sterk kan variëren). Alle setups die bijna onmiddellijke actie vereisen, vereisen doorgaans een dure omgeving die precies de productie-instellingen weerspiegelt. Maar er zijn andere opties die minder duur kunnen zijn. Deze zorgen misschien niet voor een onmiddellijke overschakeling naar een cluster voor herstel na noodgevallen, maar ze zorgen wel voor bedrijfscontinuïteit (en kosten het budget niet).
Een voorbeeld van dit type installatie is een "koude-stand-by" DR-omgeving. Hiermee kunt u uw uitgaven verlagen terwijl u toch een nieuwe omgeving op een externe locatie kunt opzetten als de ramp toeslaat. In deze blogpost laten we zien hoe je zo'n opstelling kunt maken.
De eerste installatie
Laten we aannemen dat we een redelijk standaard Master/Slave MySQL-replicatie-installatie hebben in ons eigen datacenter. Het is een zeer beschikbare installatie met ProxySQL en Keepalive voor virtuele IP-verwerking. Het grootste risico is dat het datacenter onbeschikbaar wordt. Het is een kleine DC, misschien is het maar één ISP zonder BGP. En in deze situatie gaan we ervan uit dat als het uren zou duren om de database terug te brengen, het goed is zolang het mogelijk is om het terug te brengen.
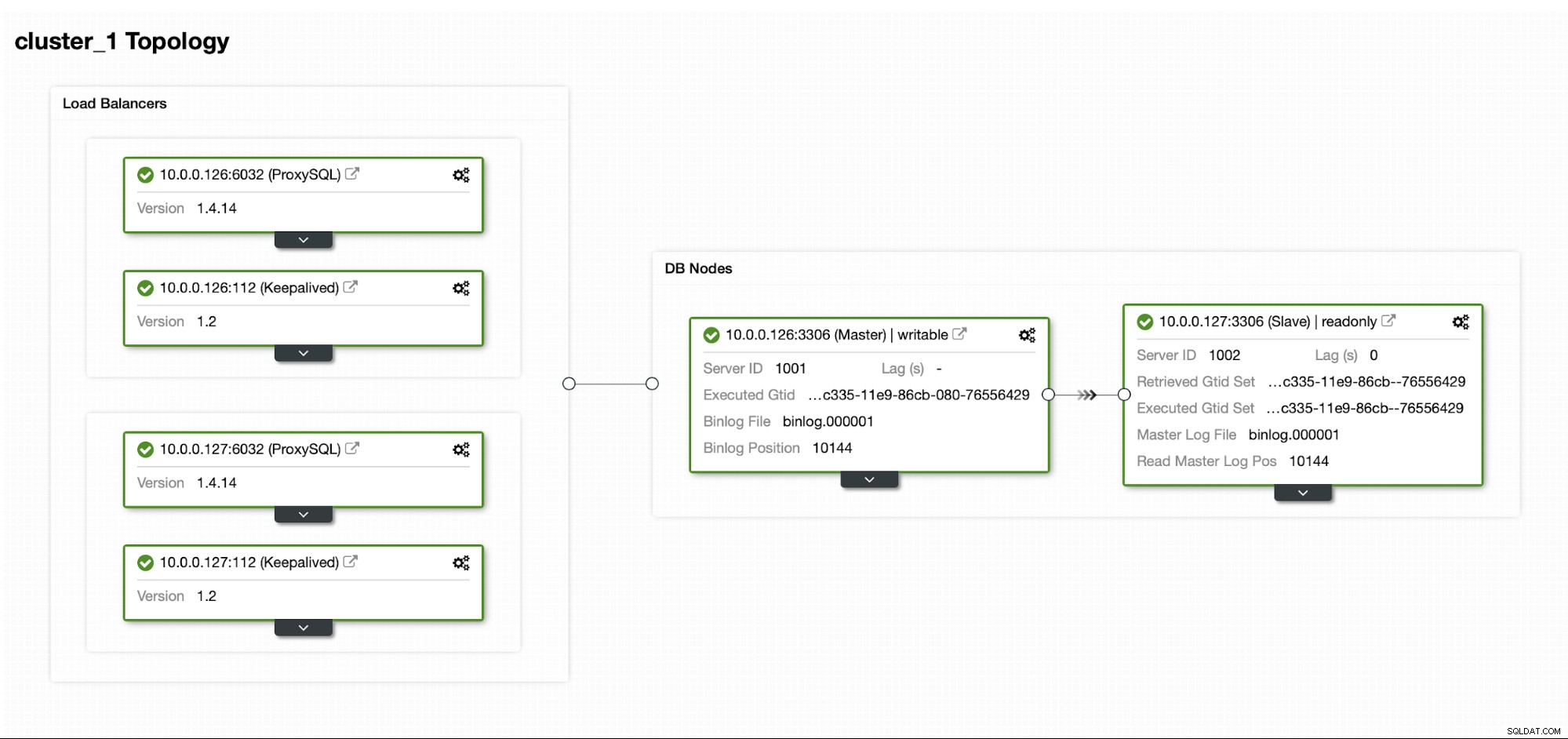
Voor de implementatie van dit cluster hebben we ClusterControl gebruikt, dat u gratis kunt downloaden. Voor onze DR-omgeving zullen we EC2 gebruiken (maar het kan ook een andere cloudprovider zijn.)
De uitdaging
Het belangrijkste probleem waarmee we te maken hebben, is hoe we ervoor moeten zorgen dat we nieuwe gegevens hebben om onze database in de rampherstelomgeving te herstellen? Natuurlijk zouden we idealiter een replicatieslave in EC2 hebben... maar dan moeten we ervoor betalen. Als we krap in het budget zitten, kunnen we dat proberen te omzeilen met back-ups. Dit is niet de perfecte oplossing, omdat we in het ergste geval nooit alle gegevens kunnen herstellen.
Met "het worstcasescenario" bedoelen we een situatie waarin we geen toegang hebben tot de originele databaseservers. Als we ze zouden kunnen bereiken, zouden er geen gegevens verloren zijn gegaan.
De oplossing
We gaan ClusterControl gebruiken om een back-upschema in te stellen om de kans te verkleinen dat de gegevens verloren gaan. We zullen ook de ClusterControl-functie gebruiken om back-ups naar de cloud te uploaden. Mocht het datacenter niet beschikbaar zijn, dan kunnen we hopen dat de door ons gekozen cloudprovider wel bereikbaar is.
Het back-upschema instellen in ClusterControl
Eerst moeten we ClusterControl configureren met onze cloudreferenties.
We kunnen dit doen door "Integraties" te gebruiken in het menu aan de linkerkant.
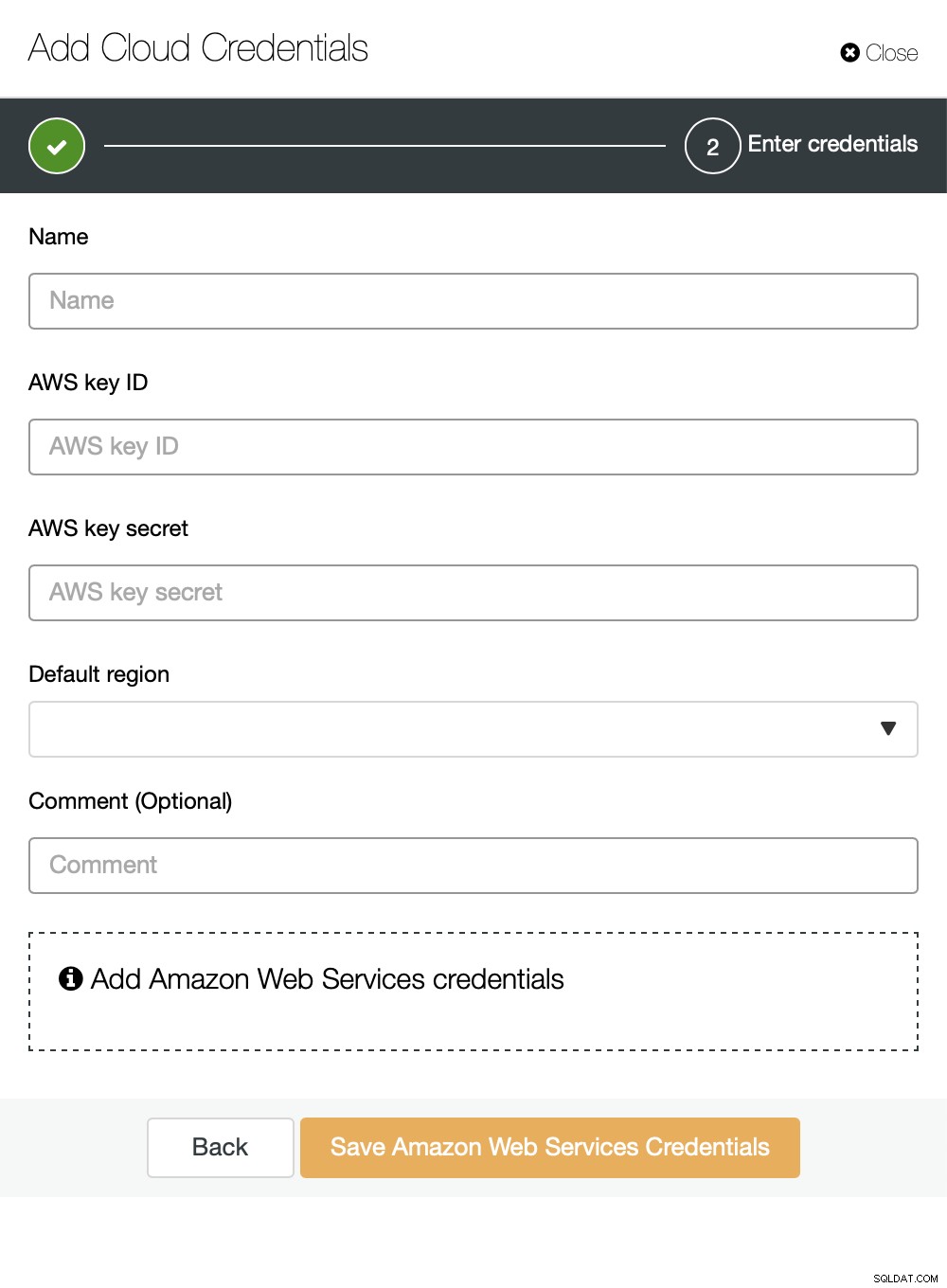
U kunt Amazon Web Services, Google Cloud of Microsoft Azure als de cloud kiezen waarnaar u wilt dat ClusterControl back-ups uploadt naar. We gaan door met AWS waar ClusterControl S3 zal gebruiken om back-ups op te slaan.
We moeten dan de sleutel-ID en het sleutelgeheim doorgeven, kies de standaardregio en kies een naam voor deze set inloggegevens.
Zodra dit is gebeurd, kunnen we de inloggegevens zien die we zojuist hebben toegevoegd ClusterControl.
Nu gaan we verder met het opzetten van een back-upschema.
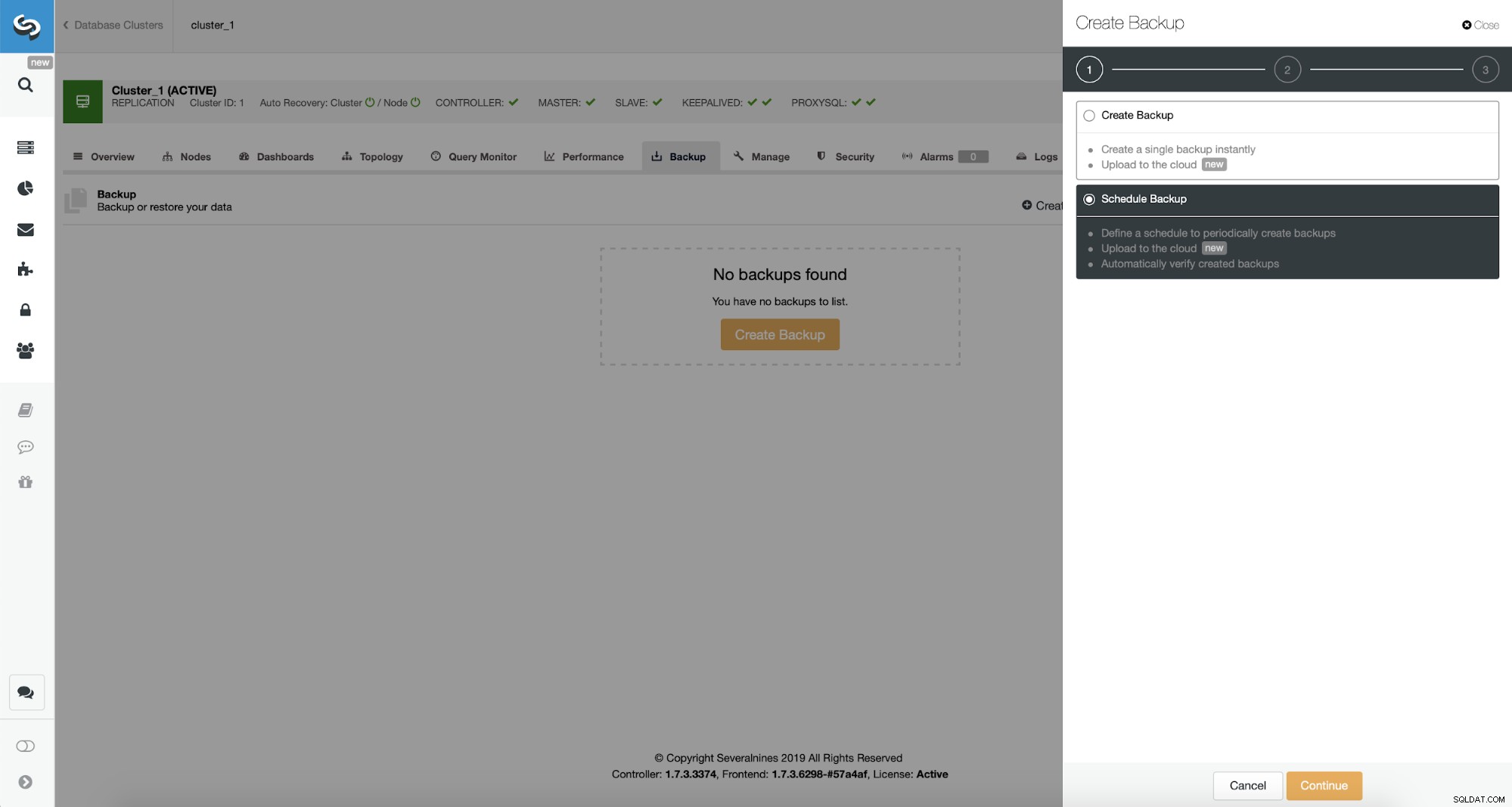
ClusterControl stelt u in staat om direct een back-up te maken of deze in te plannen. We gaan voor de tweede optie. Wat we willen is een volgend schema maken:
- Volledige back-up gemaakt eenmaal per dag
- Incrementele back-ups die elke 10 minuten worden gemaakt.
Het idee hier is als volgt. In het ergste geval verliezen we slechts 10 minuten van het verkeer. Als het datacenter van buitenaf niet meer beschikbaar is, maar het intern zou werken, kunnen we proberen gegevensverlies te voorkomen door 10 minuten te wachten, de laatste incrementele back-up op een laptop te kopiëren en dan kunnen we het handmatig naar onze DR-database sturen met zelfs telefoontethering en een mobiele verbinding om ISP-storingen te omzeilen. Als we de gegevens een tijdje niet uit het oude datacenter kunnen krijgen, is dit bedoeld om het aantal transacties te minimaliseren dat we handmatig moeten samenvoegen in de DR-database.
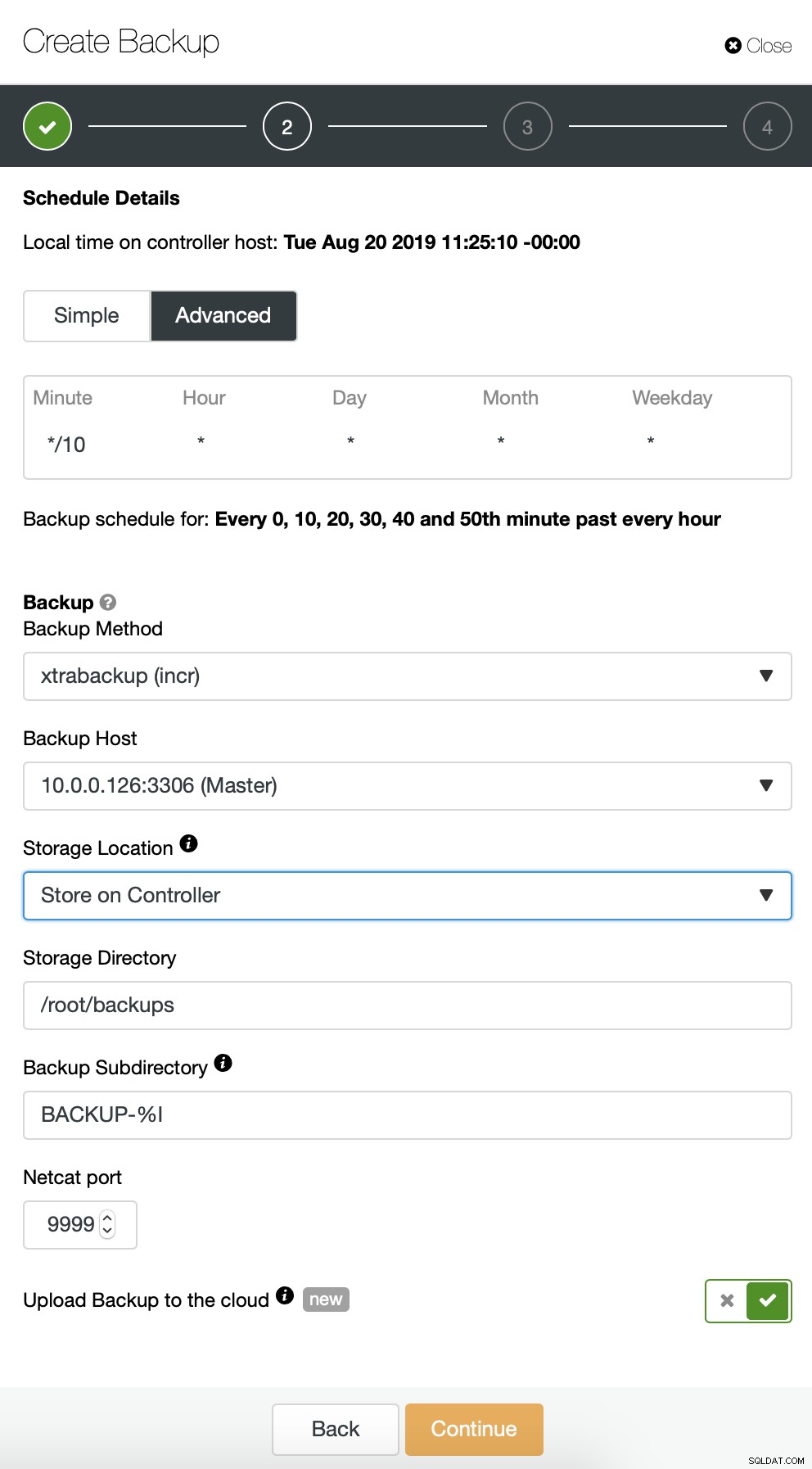
We beginnen met een volledige back-up die dagelijks om 2:00 uur zal plaatsvinden. We zullen de master gebruiken om de back-up van te maken, we zullen deze opslaan op de controller onder de map /root/backups/. We zullen ook de optie "Upload back-up naar de cloud" inschakelen.
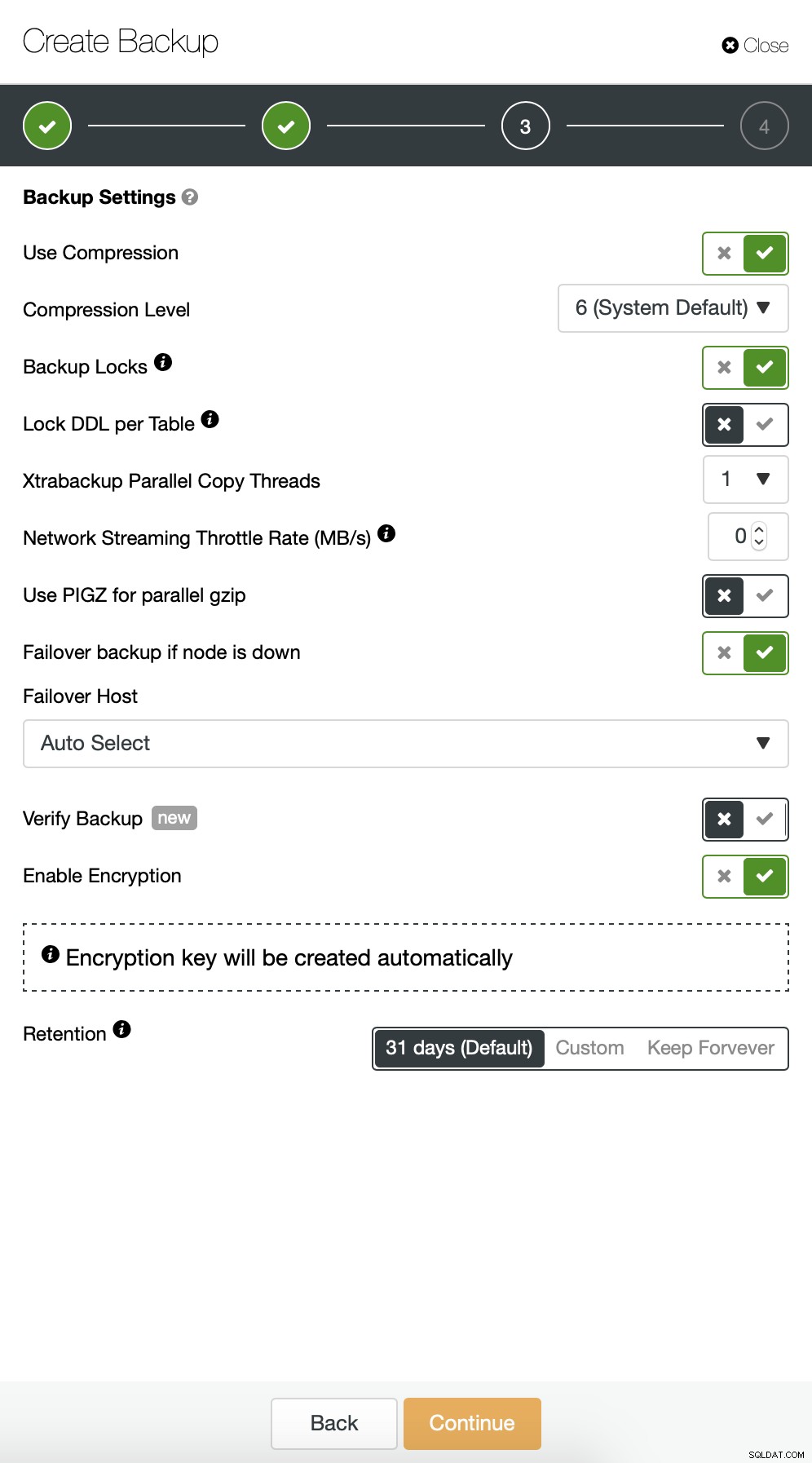
Vervolgens willen we enkele wijzigingen aanbrengen in de standaardconfiguratie. We hebben besloten om te gaan met automatisch geselecteerde failover-host (in het geval dat onze master niet beschikbaar zou zijn, zal ClusterControl elk ander beschikbaar knooppunt gebruiken). We wilden ook codering inschakelen, omdat we onze back-ups via het netwerk zullen verzenden.
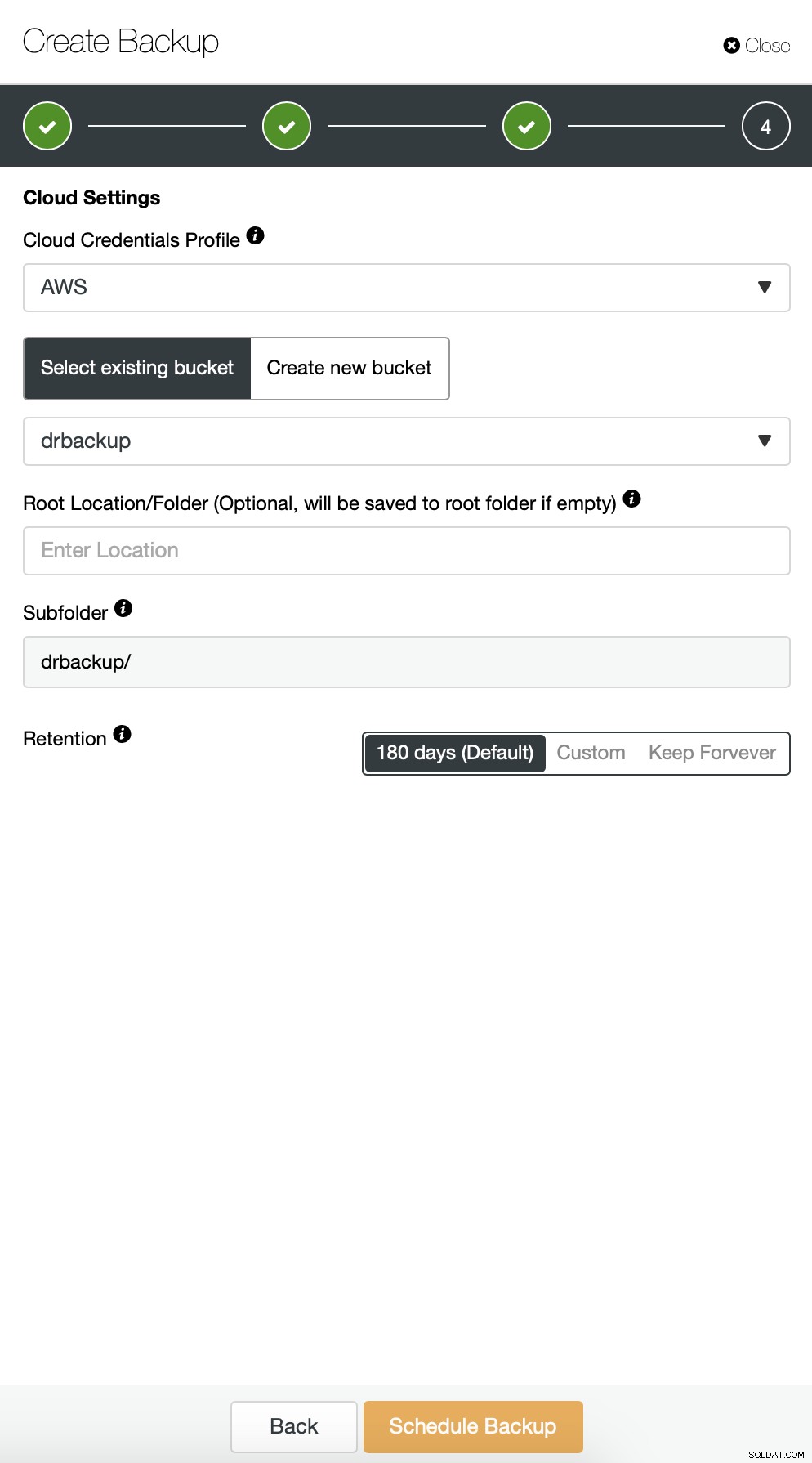
Vervolgens moeten we de inloggegevens kiezen, een bestaande S3-bucket selecteren of een nieuwe indien nodig.
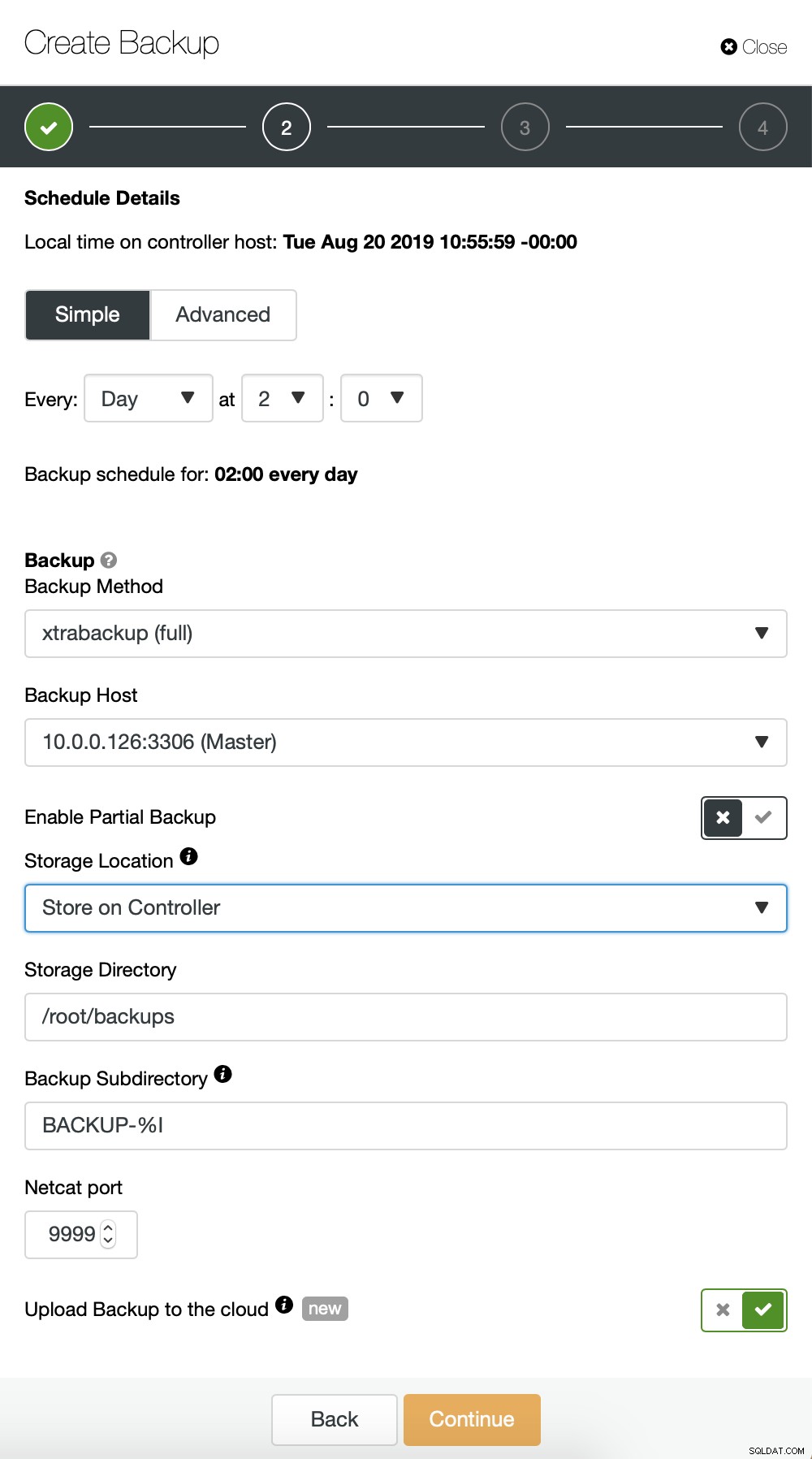
We herhalen in feite het proces voor de incrementele back-up, die we deze keer gebruikten het dialoogvenster "Geavanceerd" om de back-ups elke 10 minuten uit te voeren.
De rest van de instellingen is vergelijkbaar, we kunnen ook de S3-bucket hergebruiken.
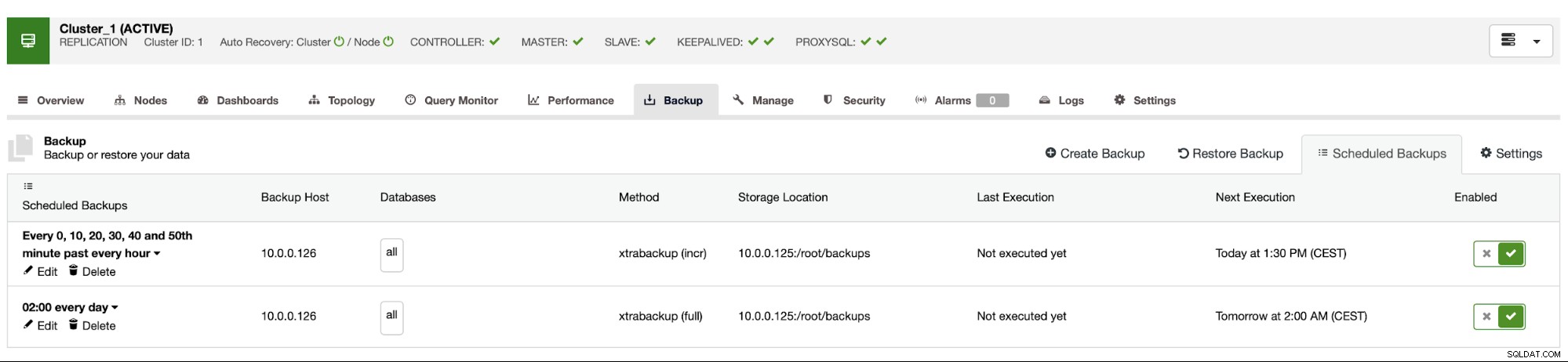
Het back-upschema ziet er uit zoals hierboven. We hoeven de volledige back-up niet handmatig te starten, ClusterControl zal een incrementele back-up uitvoeren zoals gepland en als het detecteert dat er geen volledige back-up beschikbaar is, zal het een volledige back-up uitvoeren in plaats van de incrementele.
Met een dergelijke configuratie kunnen we gerust stellen dat we de gegevens op elk extern systeem kunnen herstellen met een granulariteit van 10 minuten.
Handmatig back-upherstel
Als het gebeurt dat u de back-up op de noodherstelinstantie moet herstellen, moet u een aantal stappen ondernemen. We raden u ten zeerste aan om dit proces van tijd tot tijd te testen, zodat u zeker weet dat het correct werkt en u bekwaam bent in het uitvoeren ervan.
Eerst moeten we de AWS-opdrachtregeltool op onze doelserver installeren:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userVervolgens moeten we het configureren met de juiste inloggegevens:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonWe kunnen nu testen of we toegang hebben tot de gegevens in onze S3-bucket:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Nu moeten we de gegevens downloaden. We zullen een map maken voor de back-ups - onthoud dat we de hele back-upset moeten downloaden - beginnend bij een volledige back-up tot de laatste incrementele die we willen toepassen.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Er zijn nu twee opties. We kunnen back-ups één voor één downloaden:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256We kunnen ook, vooral als je een strak rotatieschema hebt, alle inhoud van de bucket synchroniseren met wat we lokaal op de server hebben:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Zoals je je herinnert, zijn de back-ups versleuteld. We hebben een coderingssleutel nodig die is opgeslagen in ClusterControl. Zorg ervoor dat de kopie ergens veilig is opgeslagen, buiten het hoofddatacenter. Als u het niet kunt bereiken, kunt u back-ups niet decoderen. De sleutel is te vinden in de ClusterControl-configuratie:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Het is gecodeerd met base64, dus we moeten het eerst decoderen en in het bestand opslaan voordat we kunnen beginnen met het decoderen van de back-up:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> pas
Nu kunnen we dit bestand opnieuw gebruiken om back-ups te decoderen. Laten we voor nu zeggen dat we een volledige en twee incrementele back-ups zullen maken.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/We hebben de gegevens gedecodeerd, nu moeten we doorgaan met het instellen van onze MySQL-server. Idealiter zou dit exact dezelfde versie moeten zijn als op de productiesystemen. We gebruiken Percona Server voor MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Niets ingewikkelds, alleen normale installatie. Als het eenmaal klaar en klaar is, moeten we het stoppen en de inhoud van de gegevensmap verwijderen.
service mysql stop
rm -rf /var/lib/mysql/*Om de back-up te herstellen hebben we Xtrabackup nodig - een tool die CC gebruikt om deze te maken (tenminste voor Perona en Oracle MySQL gebruikt MariaDB MariaBackup). Het is belangrijk dat deze tool in dezelfde versie wordt geïnstalleerd als op de productieservers:
apt install percona-xtrabackup-24Dat is alles wat we moeten voorbereiden. Nu kunnen we beginnen met het herstellen van de back-up. Bij incrementele back-ups is het belangrijk om in gedachten te houden dat u deze moet voorbereiden en toepassen bovenop de basisback-up. Er moet ook een basisback-up worden voorbereid. Het is cruciaal om de optie 'voorbereiden met'--apply-log-only' uit te voeren om te voorkomen dat xtrabackup de rollback-fase uitvoert. Anders kunt u de volgende incrementele back-up niet toepassen.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/In de laatste opdracht hebben we xtrabackup toegestaan om niet-voltooide transacties terug te draaien - we zullen daarna geen incrementele back-ups meer toepassen. Nu is het tijd om de gegevensmap te vullen met de back-up, de MySQL te starten en te kijken of alles werkt zoals verwacht:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Zoals je kunt zien, is alles goed. MySQL startte correct op en we hadden er toegang toe (en de gegevens zijn er!) We zijn erin geslaagd om onze database weer up-and-running te brengen op een aparte locatie. De totale benodigde tijd hangt strikt af van de grootte van de gegevens - we moesten gegevens downloaden van S3, deze decoderen en decomprimeren en tenslotte de back-up voorbereiden. Toch is dit een zeer goedkope optie (u hoeft alleen voor S3-gegevens te betalen) die u een optie biedt voor bedrijfscontinuïteit als zich een ramp voordoet.