Het runnen van een Galera-cluster in een hybride cloud moet bestaan uit ten minste twee verschillende geografische locaties, die hosts in de on-premises of privécloud verbinden met die in de openbare cloud. Of u nu onbreekbare private cloud- of openbare cloudplatforms gebruikt, Disaster Recovery (DR) is inderdaad een belangrijk punt. Dit gaat niet over het kopiëren van uw gegevens naar een back-upsite en deze kunnen herstellen, dit gaat over bedrijfscontinuïteit en hoe snel u services kunt herstellen wanneer zich een ramp voordoet.
In deze blogpost gaan we in op verschillende manieren om uw Galera-clusters te ontwerpen voor fouttolerantie in een hybride cloudomgeving.
Actief-Actieve Setup
Galera Cluster zou moeten draaien met een oneven aantal nodes in een cluster, en begint gewoonlijk met 3 nodes. Dit komt omdat Galera Cluster het quorum gebruikt om automatisch de primaire component te bepalen, waar een meerderheid van de verbonden knooppunten het cluster tegelijk zou moeten kunnen bedienen, in het geval van clusterpartitionering.
Voor een actief-actief setup hybride cloud setup, heeft Galera minimaal 3 verschillende sites nodig, die een Galera Cluster vormen over WAN. Over het algemeen heeft u een derde site nodig om als arbiter op te treden, voor het quorum te stemmen en de "primaire component" te behouden als een van de sites onbereikbaar is. Dit kan worden ingesteld als minimaal een cluster met 3 knooppunten op 3 verschillende sites (1 knooppunt per site), vergelijkbaar met het volgende diagram:
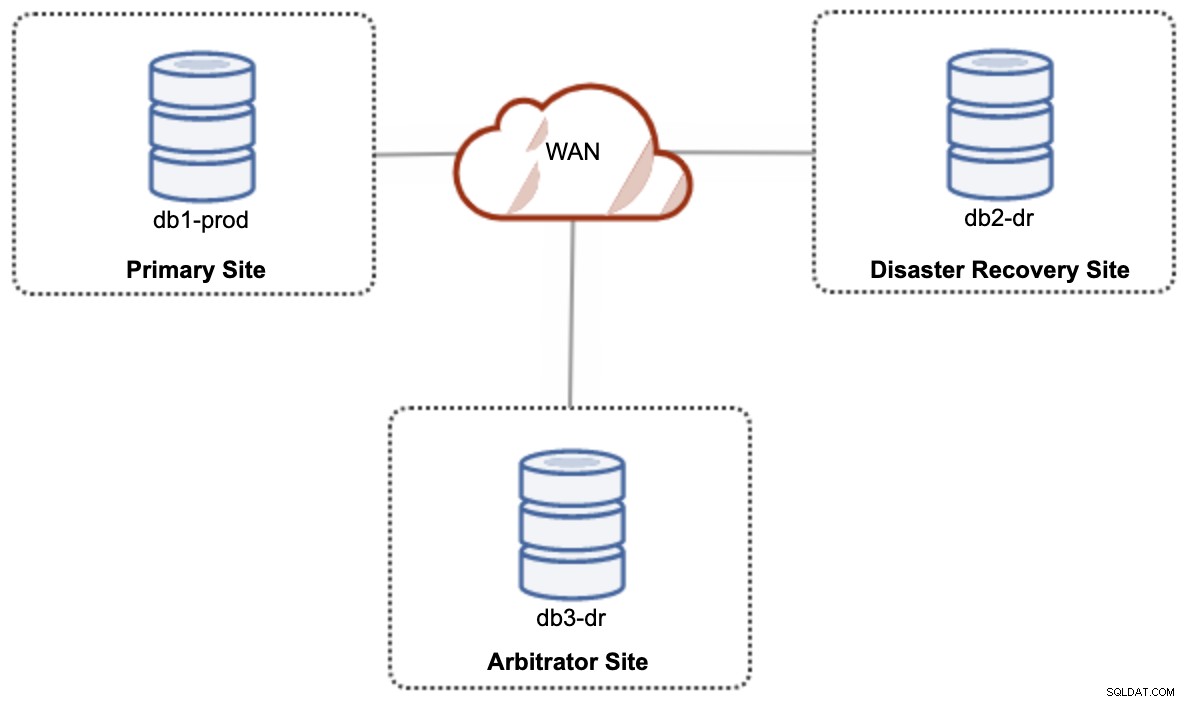
Voor prestatie- en betrouwbaarheidsdoeleinden wordt echter aanbevolen om een 7 -knooppuntcluster, zoals weergegeven in het volgende diagram:
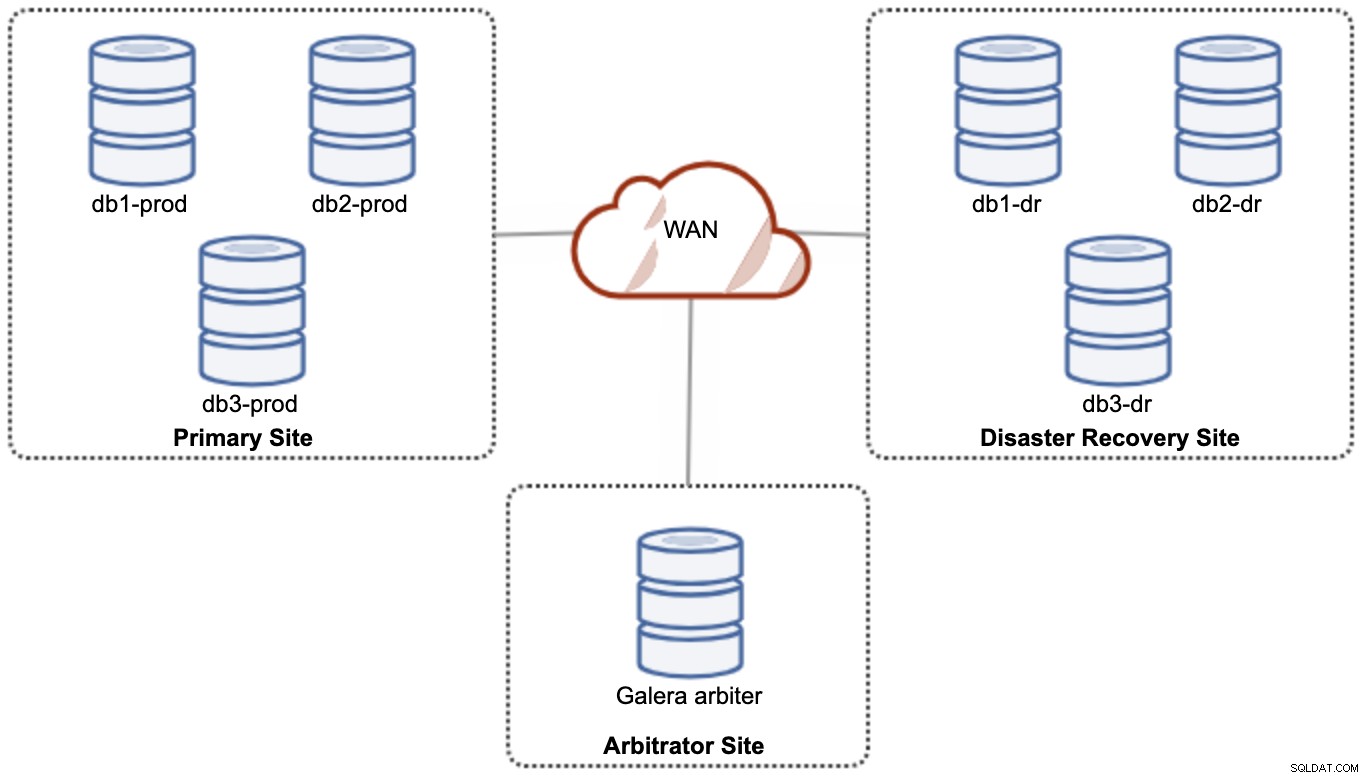
Dit wordt beschouwd als de beste topologie om een active-active setup te ondersteunen, waarbij de DR-site vrijwel onmiddellijk beschikbaar zou moeten zijn, zonder enige tussenkomst. Beide sites kunnen op elk moment lees-/schrijfbewerkingen ontvangen, op voorwaarde dat het cluster zich in het quorum bevindt.
Het is echter erg kostbaar om 3 sites en 7 databaseknooppunten te hebben (het 7e knooppunt kan worden vervangen door een garbd omdat het zeer onwaarschijnlijk is dat het wordt gebruikt om gegevens naar de clients/applicaties te sturen). Dit is over het algemeen geen populaire implementatie aan het begin van het project vanwege de hoge initiële kosten en de gevoeligheid van de communicatie en replicatie van de Galera-groep voor netwerklatentie.
Active-Passive Setup
In een actief-passieve configuratie zijn ten minste twee sites vereist en is er slechts één site tegelijk actief, ook wel de primaire site genoemd, en de knooppunten op de secundaire site repliceren alleen gegevens die afkomstig zijn van de primaire server/cluster. Voor Galera Cluster kunnen we ofwel MySQL-asynchrone replicatie gebruiken (master-slave-replicatie) of we kunnen ook Galera's vrijwel synchrone replicatie gebruiken met enige afstemming om de schrijfset-replicatie af te zwakken om als asynchrone replicatie te fungeren.
De secundaire site moet worden beschermd tegen onbedoeld schrijven, met behulp van de alleen-lezen-vlag, toepassingsfirewall, reverse proxy of andere middelen, aangezien de gegevensstroom altijd van de primaire naar de secundaire site komt, tenzij een failover heeft de secundaire site geïnitieerd en gepromoot als de primaire.
Asynchrone replicatie gebruiken
Een goede zaak van asynchrone replicatie is dat de replicatie geen invloed heeft op de bronserver/cluster, maar het mag achterblijven op de master. Deze opstelling maakt de primaire en DR-site onafhankelijk van elkaar, losjes verbonden met asynchrone replicatie. Dit kan worden ingesteld als minimaal een cluster met 4 knooppunten op 2 verschillende sites, vergelijkbaar met het volgende diagram:
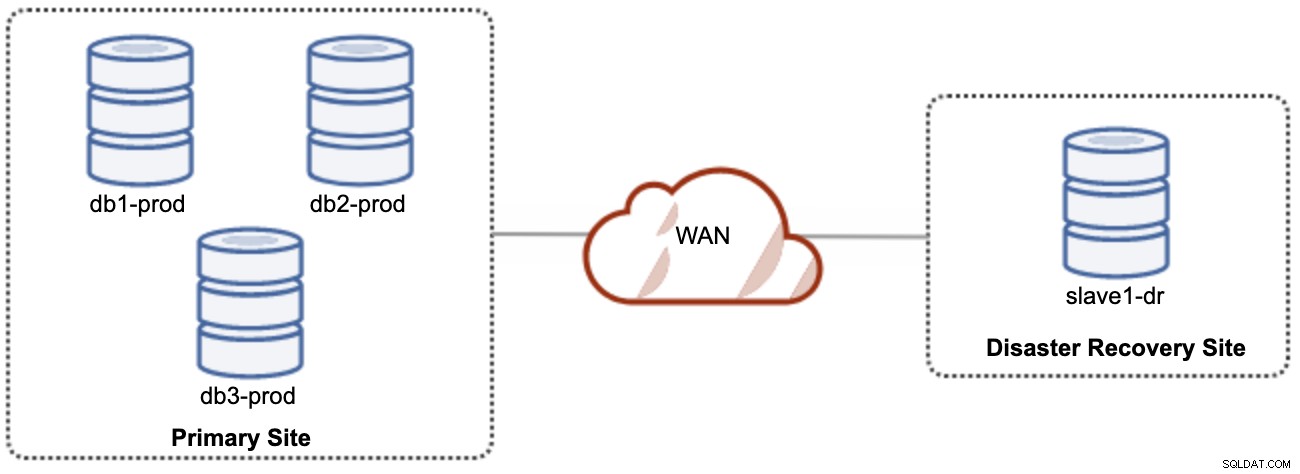
Een van de Galera-knooppunten in de DR-site zal een slaaf zijn, die repliceert vanaf een van de Galera-knooppunten (master) op de primaire site. Beide sites moeten binaire logboeken met GTID produceren en log_slave_updates zijn ingeschakeld - de updates die afkomstig zijn van de asynchrone replicatiestroom worden toegepast op de andere knooppunten in het cluster. Voor productiegebruik raden we echter aan om twee sets clusters op beide locaties te hebben, zoals weergegeven in het volgende diagram:
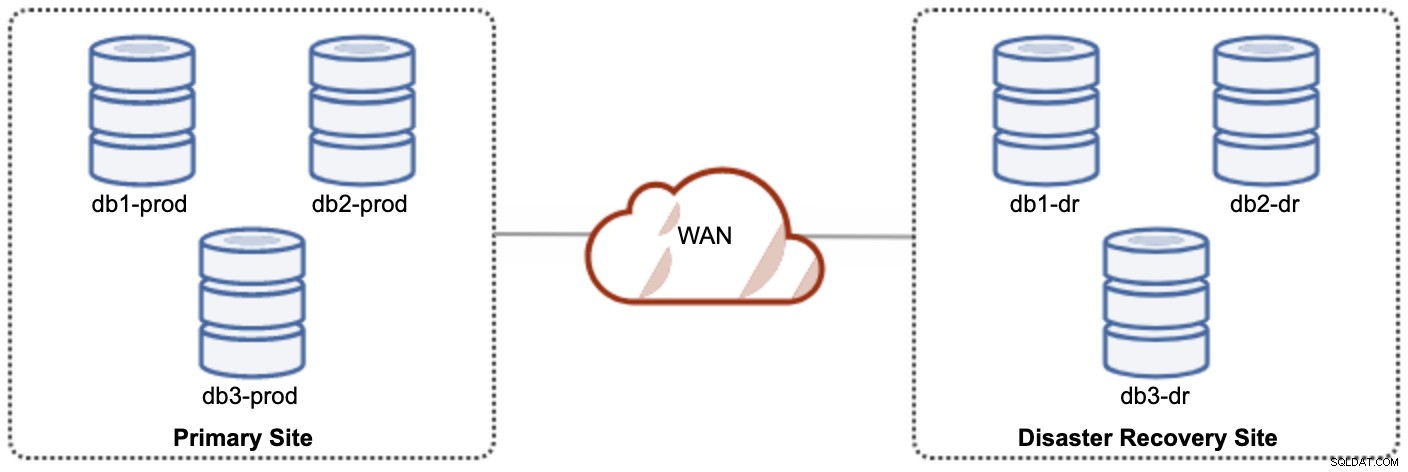
Door twee afzonderlijke clusters te hebben, zijn ze losjes gekoppeld en hebben ze geen invloed op elkaar, b.v. een clusterfout op de primaire site heeft geen invloed op de DR-site. Wat de prestaties betreft, heeft de WAN-latentie geen invloed op updates op het actieve cluster. Deze worden asynchroon naar de back-upsite verzonden. Het DR-cluster kan mogelijk draaien op kleinere instanties in een openbare cloudomgeving, zolang ze het primaire cluster kunnen bijhouden. De instanties kunnen indien nodig worden geüpgraded. Toepassingen moeten schrijfbewerkingen naar de primaire site verzenden en de secundaire site moet worden ingesteld om in de alleen-lezen modus te worden uitgevoerd. De site voor noodherstel kan worden gebruikt voor andere doeleinden, zoals databaseback-up, back-up van binaire logbestanden en rapportage of verwerking van analytische query's (OLAP).
Het nadeel is dat er een kans is op gegevensverlies tijdens failover/fallback als de slave achterblijft. Daarom wordt aanbevolen om semi-synchrone replicatie in te schakelen om het risico op gegevensverlies te verkleinen. Merk op dat het gebruik van semi-synchrone replicatie nog steeds geen sterke garanties biedt tegen gegevensverlies, in vergelijking met Galera's vrijwel synchrone replicatie. Lees deze MySQL-handleiding aandachtig door, bijvoorbeeld deze zinnen:
"Als bij semisynchrone replicatie de bron crasht en een failover naar een replica wordt uitgevoerd, mag de defecte bron niet opnieuw worden gebruikt als de replicatiebron en moet deze worden weggegooid. Er kunnen transacties zijn die niet erkend door enige replica, die daarom niet zijn vastgelegd vóór de failover."
Het failover-proces is vrij eenvoudig. Om de site voor noodherstel te promoten, schakelt u eenvoudig de alleen-lezen-vlag uit en begint u de toepassing naar de databaseknooppunten op de DR-site te leiden. De terugvalstrategie is echter een beetje lastig, en het vereist enige expertise in het ensceneren van de gegevens op beide sites, het omschakelen van de master/slave-rol van een cluster en het omleiden van de slave-replicatiestroom naar de tegenovergestelde richting.
Galera-replicatie gebruiken
Voor actief-passieve instellingen kunnen we de meerderheid van de knooppunten op de primaire site plaatsen, terwijl de minderheid van de knooppunten zich op de noodherstelsite bevinden, zoals weergegeven in de volgende schermafbeelding voor een 3- knooppunt Galera-cluster:
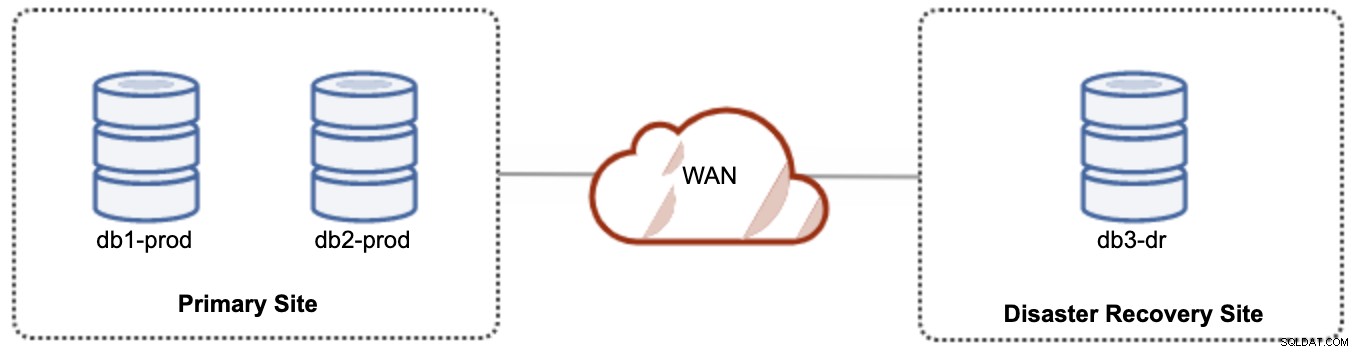
Als de primaire site niet beschikbaar is, mislukt het cluster omdat het buiten het quorum is. Het Galera-knooppunt op de site voor noodherstel (db3-dr) moet handmatig worden opgestart als een primaire component met één knooppunt. Zodra de primaire site weer beschikbaar is, moeten beide knooppunten op de primaire site (db1-prod en db2-prod) zich opnieuw aansluiten bij galera3 om te worden gesynchroniseerd. Het hebben van een behoorlijk grote gcache zou het risico op SST via WAN moeten helpen verminderen. Deze architectuur is eenvoudig in te stellen en te beheren en zeer kosteneffectief.
Failover is handmatig, omdat de beheerder het enkele knooppunt als het primaire onderdeel moet promoten (bootstrap db3-dr of gebruik set pc.bootstrap=1 in de parameter wsrep_provider_options. In de tussentijd zou er downtime zijn Prestaties kunnen een probleem zijn, aangezien de DR-site met een kleiner aantal knooppunten wordt uitgevoerd (aangezien de DR-site altijd de minderheid is) om de volledige belasting uit te voeren. Het is wellicht mogelijk om uit te schalen met meer knooppunten na het overschakelen naar de DR-site, maar pas op voor de extra belasting.
Merk op dat Galera Cluster gevoelig is voor het netwerk vanwege het vrijwel synchrone karakter. Hoe verder de Galera-knooppunten zich in een bepaald cluster bevinden, hoe hoger de latentie en de schrijfcapaciteit om de schrijfsets te distribueren en te certificeren. Als de connectiviteit niet stabiel is, kan clusterpartitionering ook gemakkelijk plaatsvinden, wat clustersynchronisatie op de joiner-knooppunten kan activeren. In sommige gevallen kan dit instabiliteit in het cluster veroorzaken. Dit vereist een beetje afstemming op Galera-parameters, zoals te zien is in deze blogpost, Een hybride infrastructuuromgeving implementeren voor Percona XtraDB-cluster.
Laatste gedachten
Galera Cluster is een geweldige technologie die op verschillende manieren kan worden ingezet:één cluster verspreid over meerdere sites, meerdere clusters die synchroon worden gehouden via asynchrone replicatie, een combinatie van synchrone en asynchrone replicatie, enzovoort. De daadwerkelijke oplossing wordt bepaald door factoren zoals WAN-latentie, eventuele versus sterke gegevensconsistentie en budget.