De functies OVER en PARTITION BY zijn beide functies die worden gebruikt om een resultaatset volgens gespecificeerde criteria te delen.
Dit artikel legt uit hoe deze twee functies samen kunnen worden gebruikt om gepartitioneerde gegevens op zeer specifieke manieren op te halen.
Voorbereiding van enkele voorbeeldgegevens
Om onze voorbeeldquery's uit te voeren, maken we eerst een database met de naam "studentdb".
Voer de volgende opdracht uit in uw queryvenster:
CREATE DATABASE schooldb;
Vervolgens moeten we de "student" -tabel maken in de "studentdb" -database. De studententabel heeft vijf kolommen:id, naam, leeftijd, geslacht en totaalscore.
Zorg zoals altijd voor een goede back-up voordat u met een nieuwe code gaat experimenteren. Raadpleeg dit artikel over het maken van back-ups van SQL Server-databases als u het niet zeker weet.
Voer de volgende query uit om de studententabel te maken.
USE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
) Ten slotte moeten we wat dummy-gegevens in de database invoegen om mee te werken.
USE schooldb
INSERT INTO student
VALUES ('Jolly', 'Female', 20, 500),
('Jon', 'Male', 22, 545),
('Sara', 'Female', 25, 600),
('Laura', 'Female', 18, 400),
('Alan', 'Male', 20, 500),
('Kate', 'Female', 22, 500),
('Joseph', 'Male', 18, 643),
('Mice', 'Male', 23, 543),
('Wise', 'Male', 21, 499),
('Elis', 'Female', 27, 400); We zijn nu klaar om aan een probleem te werken en te zien wie we Over en Partition By kunnen gebruiken om het op te lossen.
Probleem
We hebben 10 records in de studententabel en we willen de naam, id en geslacht voor alle studenten weergeven, en daarnaast willen we ook het totale aantal studenten weergeven dat tot elk geslacht behoort, de gemiddelde leeftijd van de studenten van elk geslacht en de som van de waarden in de kolom total_score voor elk geslacht.
De resultatenset waarnaar we op zoek zijn, ziet er als volgt uit:
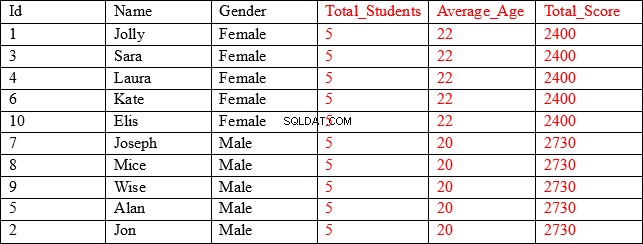
Zoals u kunt zien, bevatten de eerste drie kolommen (weergegeven in zwart) individuele waarden voor elke record, terwijl de laatste drie kolommen (weergegeven in rood) geaggregeerde waarden bevatten, gegroepeerd op de geslachtskolom. In de kolom Gemiddelde_leeftijd geven de eerste vijf rijen bijvoorbeeld de gemiddelde leeftijd en de totale score weer van alle records waarbij het geslacht Vrouwelijk is.
Onze resultatenset bevat geaggregeerde resultaten die zijn samengevoegd met niet-geaggregeerde kolommen.
Om de geaggregeerde resultaten op te halen, gegroepeerd op een bepaalde kolom, kunnen we zoals gewoonlijk de GROUP BY-clausule gebruiken.
USE schooldb SELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Laten we eens kijken hoe we Total_Students, Average_Age en Total_Score van de studenten kunnen ophalen, gegroepeerd op geslacht.
U ziet de volgende resultaten:

Laten we dit nu uitbreiden en 'id' en 'name' toevoegen (de niet-geaggregeerde kolommen in de SELECT-instructie) en kijken of we ons gewenste resultaat kunnen krijgen.
USE schooldb SELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Wanneer u de bovenstaande query uitvoert, ziet u een fout:

De fout zegt dat de id-kolom van de studententabel ongeldig is in de SELECT-instructie omdat we de GROUP BY-component in de query gebruiken.
Dit betekent dat we een aggregatiefunctie op de id-kolom moeten toepassen of dat we deze in de GROUP BY-clausule moeten gebruiken. Kortom, dit schema lost ons probleem niet op.
Oplossing met JOIN-instructie
Een oplossing hiervoor zou zijn om de JOIN-instructie te gebruiken om de kolommen met geaggregeerde resultaten samen te voegen met kolommen die niet-geaggregeerde resultaten bevatten.
Om dit te doen, heb je een subquery nodig die geslacht, Total_Students, Average_Age en de Total_Score van de studenten op basis van geslacht ophaalt. Deze resultaten kunnen vervolgens worden samengevoegd met de resultaten die zijn verkregen uit de subquery met de buitenste SELECT-instructie. Dit wordt toegepast op de geslachtskolom van de subquery die het geaggregeerde resultaat bevat en de geslachtskolom van de studententabel. De buitenste SELECT-instructie zou niet-geaggregeerde kolommen bevatten, d.w.z. 'id' en 'name', zoals hieronder.
USE schooldb SELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_Score FROM student INNER JOIN (SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_Score FROM student GROUP BY gender) AS Aggregation on Aggregation.gender = student.gender
De bovenstaande vraag geeft u het gewenste resultaat, maar is niet de optimale oplossing. We moesten een JOIN-statement en een subquery gebruiken, wat de complexiteit van het script verhoogt. Dit is geen elegante of efficiënte oplossing.
Een betere benadering is om de clausules OVER en PARTITION BY in combinatie te gebruiken.
Oplossing met OVER en PARTITION BY
Als u de clausules OVER en PARTITION BY wilt gebruiken, hoeft u alleen maar de kolom op te geven waarmee u uw geaggregeerde resultaten wilt partitioneren. Dit kan het beste worden uitgelegd aan de hand van een voorbeeld.
Laten we eens kijken hoe we ons resultaat bereiken met OVER en PARTITION BY.
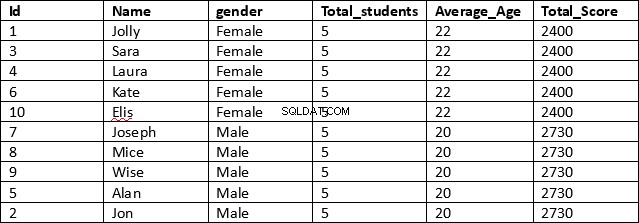
USE schooldb SELECT id, name, gender, COUNT(gender) OVER (PARTITION BY gender) AS Total_students, AVG(age) OVER (PARTITION BY gender) AS Average_Age, SUM(total_score) OVER (PARTITION BY gender) AS Total_Score FROM student
Dit is een veel efficiënter resultaat. In de eerste regel van het script worden de kolommen id, naam en geslacht opgehaald. Deze kolommen bevatten geen geaggregeerde resultaten.
Vervolgens specificeren we voor de kolommen die geaggregeerde resultaten bevatten eenvoudig de geaggregeerde functie, gevolgd door de OVER-component en vervolgens specificeren we binnen de haakjes de PARTITION BY-component gevolgd door de naam van de kolom waarvan we willen dat onze resultaten worden gepartitioneerd zoals weergegeven hieronder.
Referenties
- Microsoft – De OVER-clausule begrijpen
- Midnight DBA – Inleiding tot OVER en PARTITIE DOOR
- StackOverflow – Verschil tussen PARTITIE BY en GROUP BY