In dit artikel ga ik uitleggen hoe je een tabel verplaatst van de primaire bestandsgroep naar de secundaire bestandsgroep. Laten we eerst eens kijken wat gegevensbestand, bestandsgroep en type bestandsgroepen zijn.
Databasebestanden en bestandsgroepen
Wanneer SQL Server op een server is geïnstalleerd, wordt een primair gegevensbestand en een logbestand gemaakt om gegevens op te slaan. Het primaire gegevensbestand slaat gegevens en database-objecten op, zoals tabellen, index, opgeslagen procedures, enz. In logbestanden wordt informatie opgeslagen die nodig is om transacties te herstellen. Gegevensbestanden kunnen in bestandsgroepen worden samengevoegd.
SQL Server heeft drie soorten bestanden
- Primair bestand :Het wordt gemaakt wanneer de SQL-server wordt geïnstalleerd en bevat de metagegevens en informatie van de database. Gebruikersgegevens, objecten kunnen worden opgeslagen op de primaire gegevensbestanden. Het primaire bestand heeft de extensie .mdf.
- Secundair bestand :Secundaire bestanden worden door de gebruiker gedefinieerd. Ze slaan gebruikersgegevens op, objecten die door een gebruiker zijn gemaakt. Ze hebben de extensie .ndf.
- Transactielogboekbestand s:De T-Logs-bestanden registreren alle transacties die zijn uitgevoerd om de database te herstellen. De logbestandextensie in .ldf.
Zoals ik hierboven al zei, kunnen gegevensbestanden worden gegroepeerd in een bestandsgroep. Terwijl SQL Server wordt geïnstalleerd, wordt de primaire bestandsgroep gemaakt die een primair gegevensbestand heeft. Secundaire bestandsgroepen zijn door de gebruiker gedefinieerd. Ze hebben secundaire gegevensbestanden. Wanneer we een nieuwe database maken, kunnen we secundaire databestanden en bestandsgroepen maken. Het toevoegen van secundaire gegevensbestanden helpt de prestaties te verbeteren. Het kan op verschillende schijfstations of afzonderlijke schijfpartities worden gemaakt, wat de IO-wachttijd en lees-schrijflatentie vermindert.
Het wordt aanbevolen om tabellen en indexen in aparte bestandsgroepen te houden. Ook het bewaren van grote tabellen in aparte bestanden verbetert de prestaties.
Er zijn drie soorten bestandsgroepen:
- Rij bestandsgroep :Rijbestandsgroep, ook bekend als Primaire bestandsgroep, bevat een primair gegevensbestand. SQL-object, gegevens, systeemtabellen worden toegewezen aan de primaire bestandsgroep.
- Voor geheugen geoptimaliseerde bestandsgroep :Voor geheugen geoptimaliseerde bestandsgroep bevat voor geheugen geoptimaliseerde tabellen en gegevens. Om in-memory OLTP in te schakelen, moeten we een voor geheugen geoptimaliseerde bestandsgroep maken.
- FileStream :Bestandsstroom-bestandsgroep bevat bestandsstroomgegevens zoals afbeeldingen, documenten, uitvoerbare bestanden enz. De primaire bestandsgroep kan geen bestandsstroomgegevens bevatten, we moeten een FileStream-bestandsgroep maken. Het bevat de FileStream-gegevens.
Demo instellen
In deze demo heb ik "DemoDatabase" gemaakt op de SQL Server 2017-instantie. De tabbladen "Records" en "PatientData" zijn gemaakt in de database. De primaire sleutel "PK_CIDX_Records_ID" is gemaakt in de tabel "Records" en de geclusterde index "CIDX_PatientData_ID" is gemaakt in de tabel "PatientData". In deze demo zal ik de tabellen "Records" en "PatientData" verplaatsen van de primaire bestandsgroep naar de secundaire bestandsgroep.
Hiervoor moeten we het volgende doen:
- Maak een secundaire bestandsgroep.
- Voeg gegevensbestanden toe aan de secundaire bestandsgroep.
- Verplaats de tabel naar de secundaire bestandsgroep door de geclusterde index met de primaire sleutelbeperking te verplaatsen.
- Verplaats de tabellen naar de secundaire bestandsgroep door de geclusterde index te verplaatsen zonder de primaire sleutel.
Secundaire bestandsgroep maken
Een secundaire bestandsgroep kan worden gemaakt met T-SQL OF met behulp van de wizard Bestand toevoegen van SQL Server Management Studio. Om een bestandsgroep toe te voegen met behulp van SSMS, opent u SSMS en selecteert u een database waarin een bestandsgroep moet worden aangemaakt. Klik met de rechtermuisknop op de database en selecteer "Eigenschappen ”>> selecteer “Bestandsgroepen ” en klik op “Bestandsgroep toevoegen ” zoals weergegeven in de volgende afbeelding:
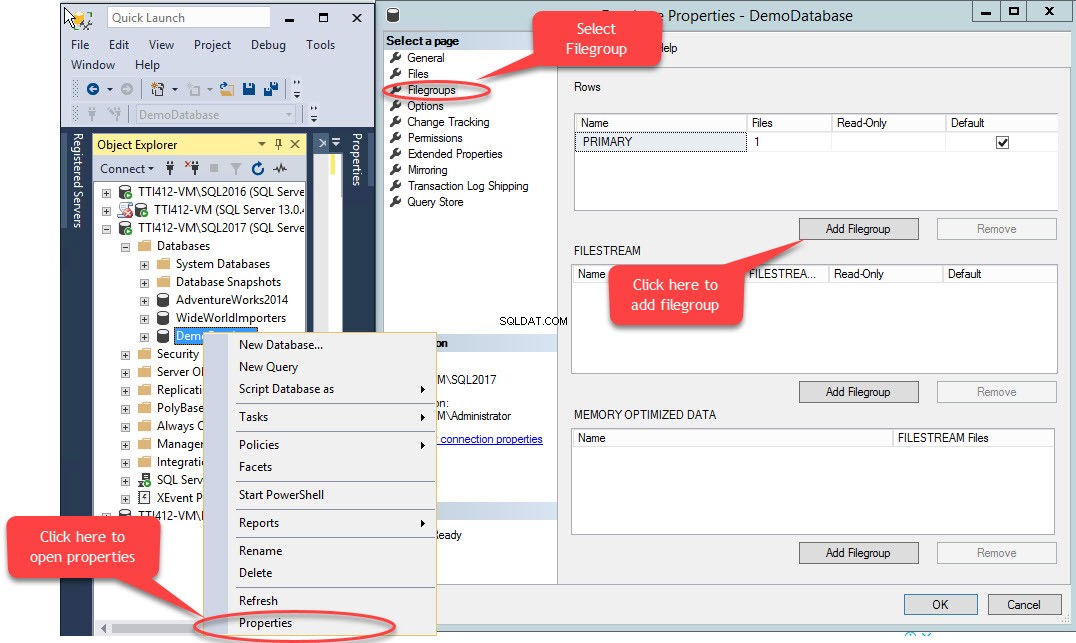
Wanneer we klikken op de "Bestandsgroep toevoegen ” knop, zal een rij worden toegevoegd in de “Rijen " rooster. In de "Rijen ”-raster, geef de juiste bestandsgroepnaam op in de “Naam ” kolom. Bestandsgroep is niet alleen-lezen of standaard; bewaar daarom de Alleen-lezen en Standaard selectievakjes gewist voor nieuwe bestandsgroep. Zie de volgende afbeelding:
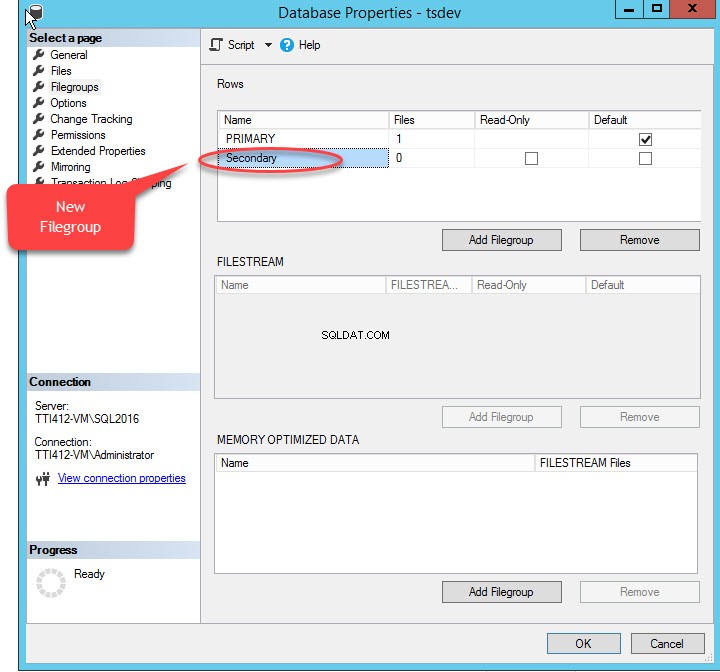
Klik op OK om het dialoogvenster te sluiten.
Voer het volgende script uit om een bestandsgroep te maken met behulp van een T-SQL-script.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Bestanden toevoegen aan bestandsgroep
Om bestanden in een bestandsgroep toe te voegen, opent u de database-eigenschappen, selecteert u "bestanden" en klikt u op "Toevoegen". Zoals weergegeven in de volgende afbeelding:
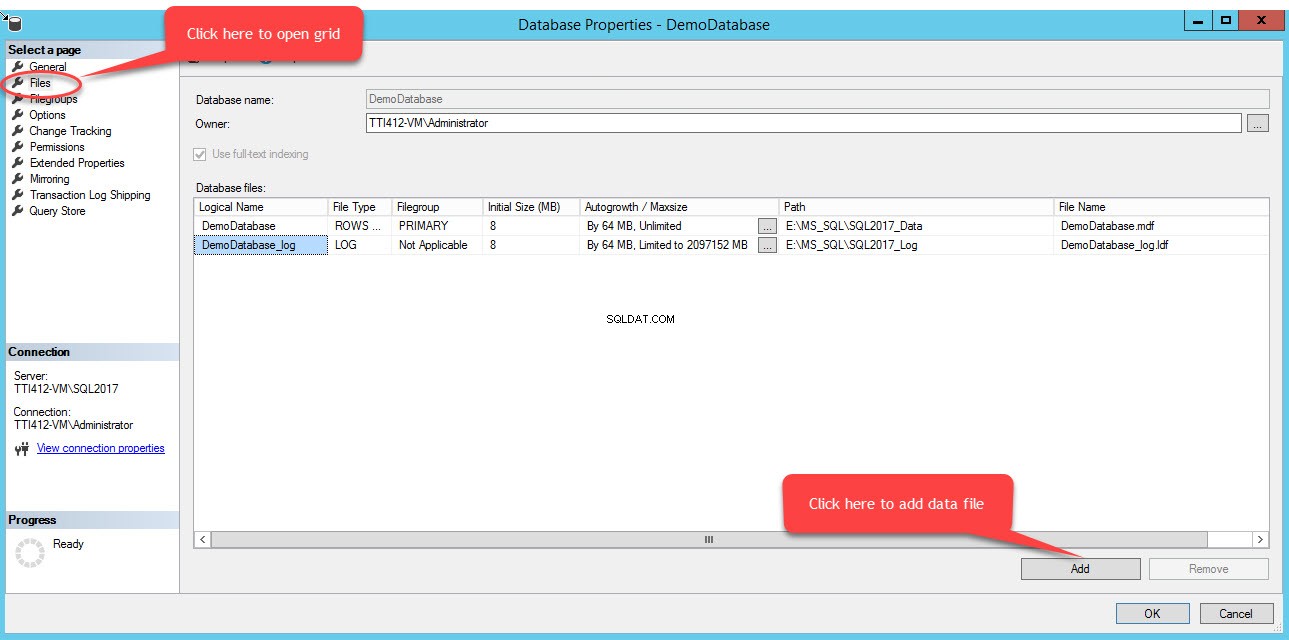
Er wordt een lege rij toegevoegd in de Databasebestanden rasterweergave. Geef in de rasterweergave de juiste logische naam op in de Logische naam kolom, selecteer Rijgegevens van hetBestandstype vervolgkeuzelijst, selecteer secundair uit de Bestandsgroep vervolgkeuzelijst, stel de initiële grootte van het bestand in bij Initial Size kolommen, stel automatische groei en maximale grootte in in de Autogrowth/Maxsize kolom, geef de fysieke locatie van het secundaire gegevensbestand op in het Pad kolom en geef de juiste bestandsnaam op in de Bestandsnaam kolom. Zie de volgende afbeelding:
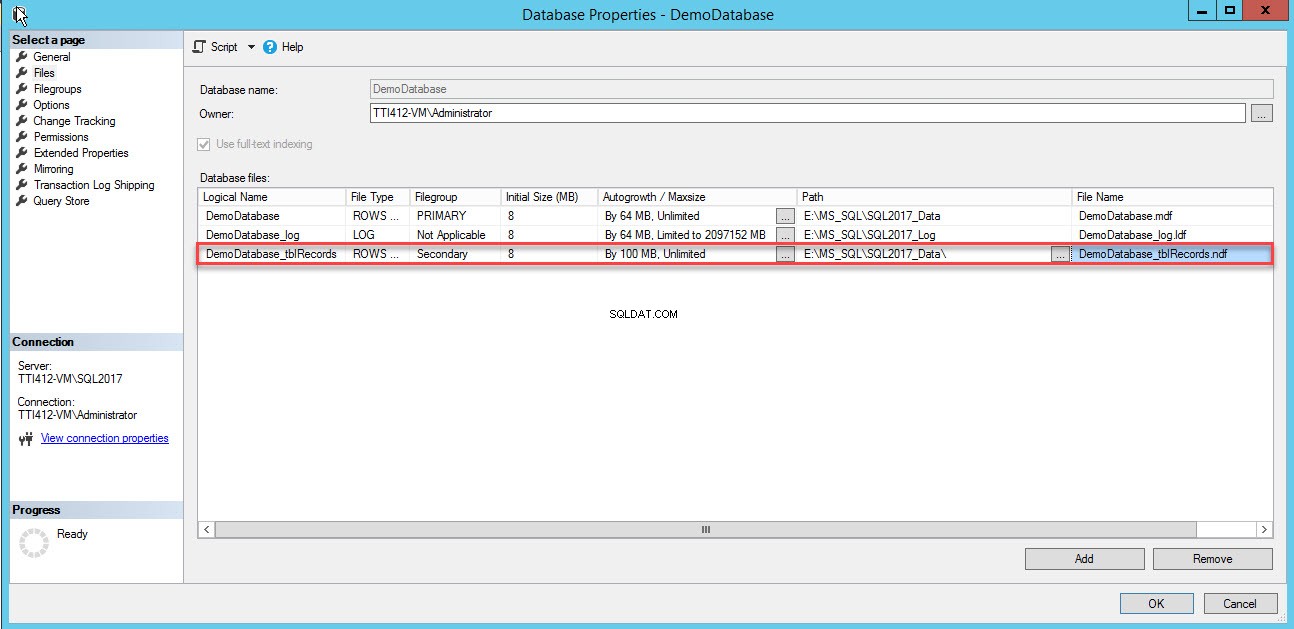
Gebruik het volgende T-SQL-script om een secundair gegevensbestand te maken.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
Het secundaire gegevensbestand is gemaakt. Zie de volgende afbeelding:
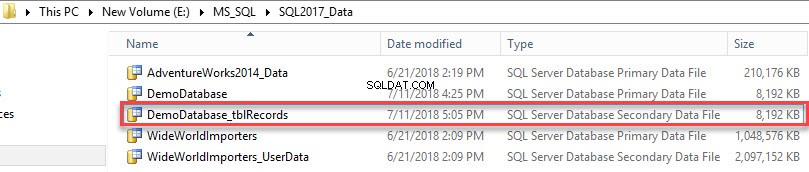
Voer de volgende query uit om een lijst met bestandsgroepen te bekijken die in de database zijn gemaakt.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Hieronder is een uitvoer van de vraag.

Bestaande tabel overzetten van primaire bestandsgroep naar secundaire bestandsgroep
We kunnen een bestaande tabel naar een andere bestandsgroep verplaatsen door de geclusterde index naar een andere bestandsgroep te verplaatsen. Zoals we weten, heeft een bladknooppunt van de geclusterde index actuele gegevens; vandaar dat het verplaatsen van een geclusterde index de hele tabel naar een andere bestandsgroep kan verplaatsen. Het verplaatsen van de index heeft een beperking:als de index een primaire sleutel of een unieke beperking is, kunt u de index niet verplaatsen met SQL Server Management Studio. Om die indexen te verplaatsen, moeten we de create index . gebruiken statement en met de DROP_Existing=ON optie.
Geclusterde index verplaatsen met primaire sleutelbeperking.
De primaire sleutel dwingt unieke waarden af en maakt daarom de unieke geclusterde index. De sleutelkolom is PRN. Om het in de secundaire bestandsgroep te maken, stelt u de DROP_EXISTING=ON . in optie en de bestandsgroep moet secundair zijn. Voer het volgende script uit.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Nadat de opdracht met succes is uitgevoerd, controleert u of de index is gemaakt in de secundaire bestandsgroep. Klik hiervoor met de rechtermuisknop op de Opslag optie in de Indexeigenschappen dialoog venster. Vouw de DemoDatabase . uit om indexeigenschappen te openen database>> uitbreiden Tabellen>> uitbreiden Indexen . Klik met de rechtermuisknop op PK_CIDX_Records_ID , zoals weergegeven in de volgende afbeelding:
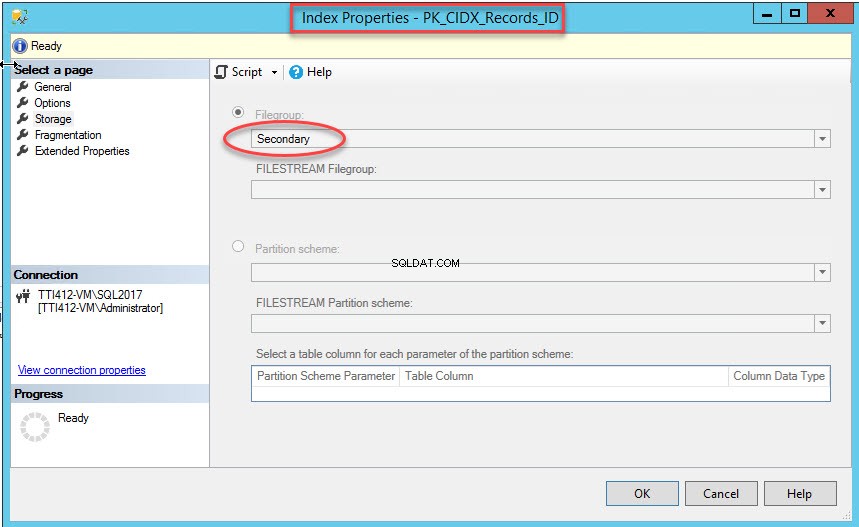
Zoals ik al zei, zodra de geclusterde index naar een secundaire bestandsgroep wordt verplaatst, wordt de tabel naar de secundaire bestandsgroep verplaatst. Om het te verifiëren, klikt u met de rechtermuisknop op de Opslag optie in deTabeleigenschappen dialoog venster. Vouw de DemoDatabase . uit om indexeigenschappen te openen database>> uitbreiden Tabel s>> klik met de rechtermuisknop op Records, en selecteer opslag, zoals weergegeven in de volgende afbeelding:
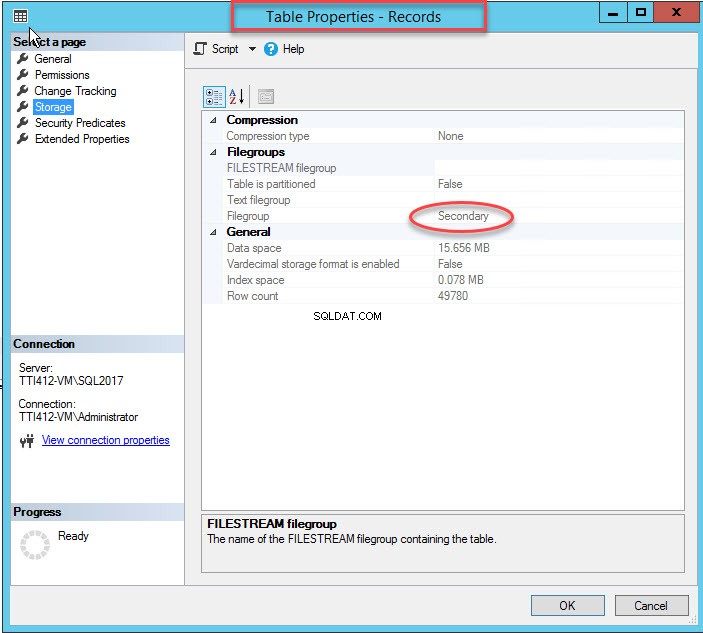
Geclusterde index verplaatsen zonder primaire sleutel
We kunnen geclusterde index verplaatsen zonder primaire sleutel met behulp van SQL Server Management Studio. Vouw hiervoor de DemoDatabase . uit database>> uitbreiden Tabellen>> uitbreiden Index s>> klik met de rechtermuisknop op de CIDX_PatientData_ID index en selecteer Eigenschappen, zoals weergegeven in de volgende afbeelding:
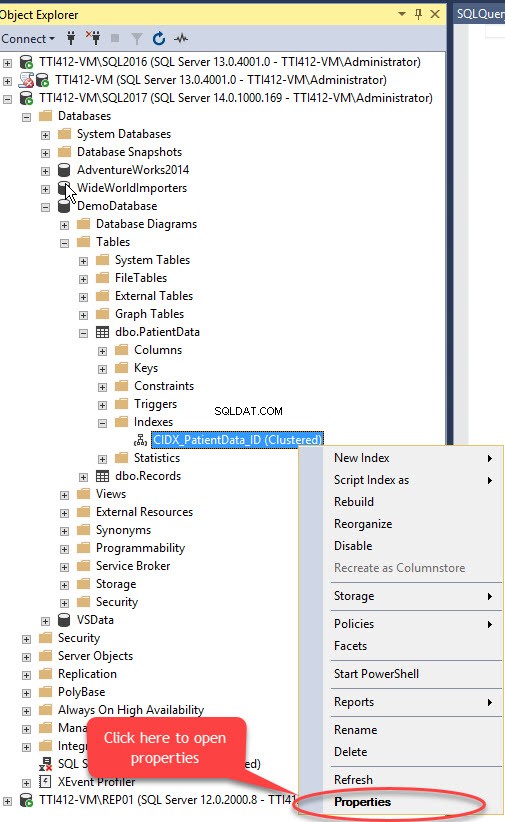
De Indexeigenschappen dialoogvenster wordt geopend. Selecteer in het dialoogvenster Opslag, en klik in het venster Opslag op de Bestandsgroep vervolgkeuzelijst, selecteer de Secundaire bestandsgroep en klik op OK, zoals weergegeven in de volgende afbeelding:
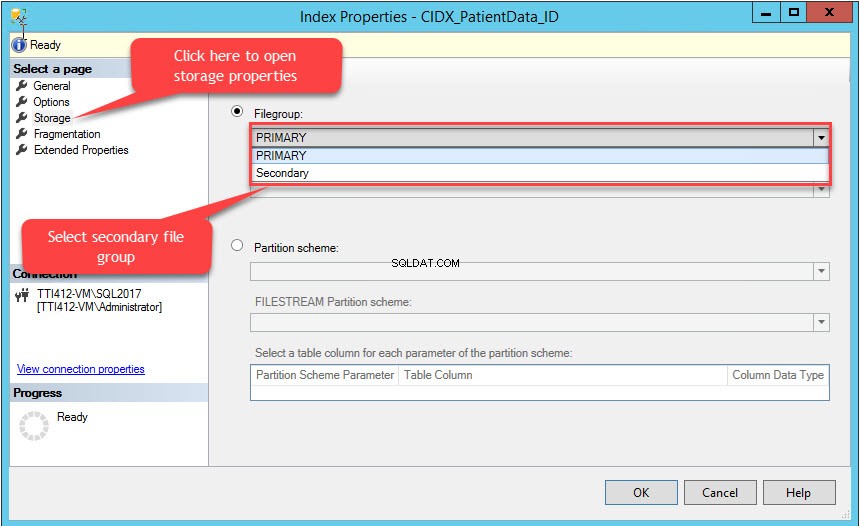
Als u de indexbestandsgroep wijzigt, wordt de volledige index opnieuw gemaakt. Zodra de index opnieuw is gemaakt, opent u Tabeleigenschappen en selecteer een opslag.
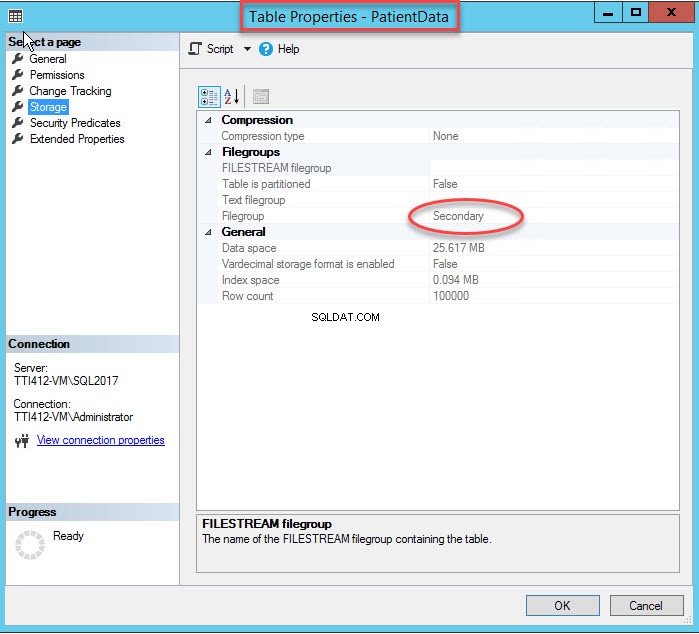
Zoals je kunt zien in de bovenstaande afbeelding, samen met het verplaatsen van de CIDX_PatientData_ID geclusterde index naar de secundaire bestandsgroep, dePatiëntgegevens tabel wordt ook verplaatst naar de Secundaire bestandsgroep.
Door de volgende query uit te voeren, kunt u de lijst met objecten vinden die in verschillende bestandsgroepen zijn gemaakt:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Hieronder staat de uitvoer van de vraag:
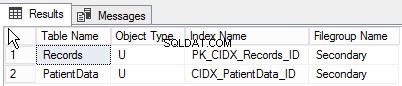
Samenvatting
In dit artikel heb ik uitgelegd
-
- Basisprincipes van gegevensbestanden en bestandsgroepen.
- Hoe maak je een secundaire bestandsgroep aan en voeg je een secundair databestand toe.
- Verplaats de tabel naar de secundaire bestandsgroep door te verplaatsen:
- Primaire sleutel.
- Geclusterde index.