SQL-CASE? Een fluitje van een cent!
Echt?
Pas als je 3 lastige problemen tegenkomt die runtime-fouten en trage prestaties kunnen veroorzaken.
Als u de ondertitels probeert te scannen om te zien wat de problemen zijn, kan ik u dat niet kwalijk nemen. Lezers, waaronder ik, zijn ongeduldig.
Ik vertrouw erop dat u de basisprincipes van SQL CASE al kent, dus ik zal u niet vervelen met lange introducties. Laten we dieper ingaan op wat er onder de motorkap gebeurt.
1. SQL CASE evalueert niet altijd sequentieel
Expressies in de Microsoft SQL CASE-instructie worden meestal sequentieel of van links naar rechts geëvalueerd. Het is echter een ander verhaal wanneer u het gebruikt met geaggregeerde functies. Laten we een voorbeeld geven:
-- aggregate function evaluated first and generated an error
DECLARE @value INT = 0;
SELECT CASE WHEN @value = 0 THEN 1 ELSE MAX(1/@value) END;
De bovenstaande code ziet er normaal uit. Als ik je vraag wat het resultaat is van die uitspraken, zul je waarschijnlijk zeggen 1. Visuele inspectie vertelt ons dat omdat @waarde is ingesteld op 0. Als de @waarde 0 is, is het resultaat 1.
Maar dat is hier niet het geval. Bekijk het echte resultaat van SQL Server Management Studio:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
Maar waarom?
Wanneer voorwaardelijke expressies gebruik maken van statistische functies zoals MAX() in SQL CASE, wordt deze eerst geëvalueerd. Dus MAX(1/@waarde) veroorzaakt de fout bij deling door nul omdat @waarde nul is.
Deze situatie is lastiger wanneer deze verborgen is. Ik zal het later uitleggen.
2. Eenvoudige SQL CASE-expressie evalueert meerdere keren
Dus wat?
Goede vraag. De waarheid is dat er helemaal geen problemen zijn als je letterlijke of eenvoudige uitdrukkingen gebruikt. Maar als je subquery's als voorwaardelijke expressie gebruikt, krijg je een grote verrassing.
Voordat u het onderstaande voorbeeld probeert, wilt u misschien een kopie van de database vanaf hier herstellen. We zullen het gebruiken voor de rest van de voorbeelden.
Overweeg nu deze zeer eenvoudige vraag:
SELECT TOP 1 manufacturerID FROM SportsCars
Het is heel eenvoudig, toch? Het retourneert 1 rij met 1 kolom met gegevens. De STATISTICS IO onthult minimale logische uitlezingen.
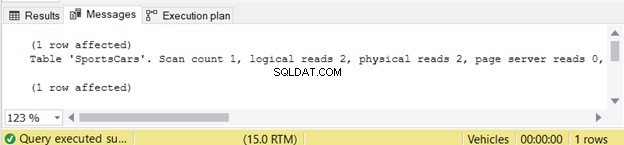
Snelle opmerking :Voor niet-ingewijden maakt het hebben van hogere logische waarden een query traag. Lees dit voor meer details.
Het uitvoeringsplan onthult ook een eenvoudig proces:
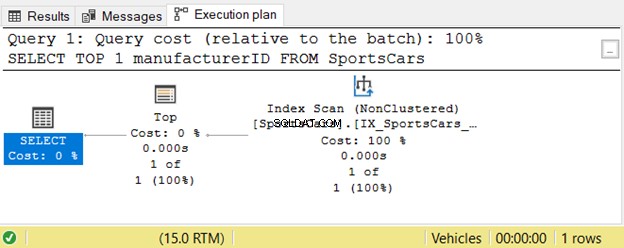
Laten we die query nu als subquery in een CASE-expressie plaatsen:
-- Using a subquery in a SQL CASE
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE (SELECT TOP 1 manufacturerID FROM SportsCars)
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Analyse
Kruis je vingers, want dit gaat de logische lezingen vier keer wegblazen.
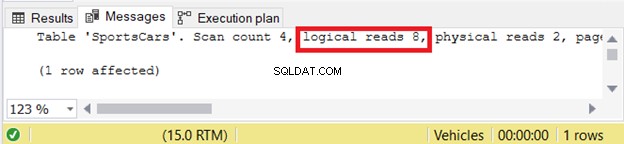
Verrassing! Vergeleken met figuur 1 met slechts 2 logische uitlezingen, is dit 4 keer hoger. De zoekopdracht is dus 4 keer langzamer. Hoe kon dat gebeuren? We hebben de subquery maar één keer gezien.
Maar dat is niet het einde van het verhaal. Bekijk het uitvoeringsplan:
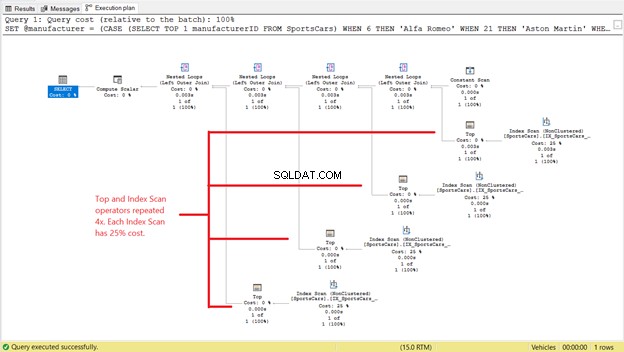
We zien 4 instanties van de Top- en Index Scan-operators in Afbeelding 4. Als elke Top en Index Scan 2 logische uitlezingen verbruikt, verklaart dat waarom de logische uitlezingen 8 werden in Afbeelding 3. En aangezien elke Top en Index Scan 25% kost , het vertelt ons ook dat ze hetzelfde zijn.
Maar daar houdt het niet op. De eigenschappen van de operator Scalar berekenen laten zien hoe het hele statement wordt behandeld.
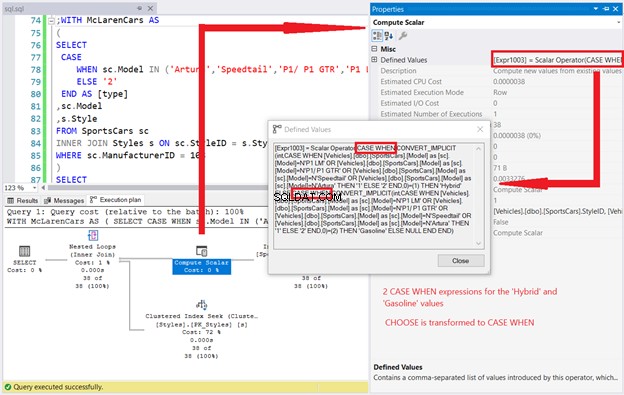
We zien 4 CASE WHEN-expressies afkomstig van de Compute Scalar-operator Defined Values. Het lijkt erop dat onze eenvoudige CASE-expressie een gezochte CASE-expressie is geworden, zoals deze:
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 6 THEN 'Alfa Romeo'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 21 THEN 'Aston Martin'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 64 THEN 'Ferrari'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Laten we samenvatten. Er waren 2 logische uitlezingen voor elke Top- en Index Scan-operator. Dit vermenigvuldigd met 4 maakt 8 logische uitlezingen. We zagen ook 4 CASE WHEN-expressies in de Compute Scalar-operator.
Uiteindelijk werd de subquery in de eenvoudige CASE-expressie 4 keer geëvalueerd. Dit zal uw zoekopdracht vertragen.
Hoe u meerdere evaluaties van een subquery in een eenvoudige CASE-expressie kunt vermijden
Om een prestatieprobleem als meerdere CASE-instructie in SQL te voorkomen, moeten we de query herschrijven.
Plaats eerst het resultaat van de subquery in een variabele. Gebruik die variabele vervolgens in de voorwaarde van de eenvoudige SQL Server CASE-expressie, als volgt:
DECLARE @manufacturer NVARCHAR(50)
DECLARE @ManufacturerID INT -- create a new variable
-- store the result of the subquery in a variable
SET @ManufacturerID = (SELECT TOP 1 manufacturerID FROM SportsCars)
-- use the new variable in the simple CASE expression
SET @manufacturer = (CASE @ManufacturerID
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Is dit een goede oplossing? Laten we eens kijken naar de logische waarden in STATISTICS IO:

We zien lagere logische uitlezingen van de gewijzigde query. Het verwijderen van de subquery en het toewijzen van het resultaat aan een variabele is veel beter. Hoe zit het met het uitvoeringsplan? Zie het hieronder.
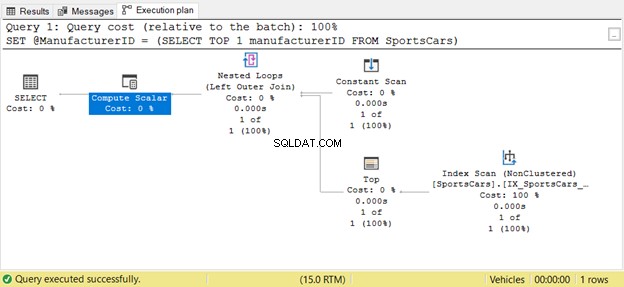
De Top en Index Scan-operator verscheen slechts één keer, niet vier keer. Geweldig!
Afhaalmaaltijden :Gebruik geen subquery als voorwaarde in de CASE-expressie. Als u een waarde moet ophalen, plaatst u eerst het resultaat van de subquery in een variabele. Gebruik die variabele vervolgens in de CASE-expressie.
3. Deze 3 ingebouwde functies transformeren in het geheim naar SQL CASE
Er is een geheim en de SQL Server CASE-instructie heeft er iets mee te maken. Als je niet weet hoe deze 3 functies zich gedragen, weet je niet dat je een fout begaat die we eerder probeerden te vermijden in de punten #1 en #2. Hier zijn ze:
- IIF
- COALESCE
- KIES
Laten we ze een voor een bekijken.
IIF
Ik gebruikte Immediate IF, of IIF, in Visual Basic en Visual Basic for Applications. Dit is ook gelijk aan de ternaire operator van C#:
Deze functie die een voorwaarde krijgt, retourneert 1 van de 2 argumenten op basis van het resultaat van de voorwaarde. En deze functie is ook beschikbaar in T-SQL. CASE-instructie in de WHERE-component kan worden gebruikt in de SELECT-instructie
Maar het is gewoon een suikerlaagje van een langere CASE-uitdrukking. Hoe weten we? Laten we een voorbeeld bekijken.
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'McLaren Senna', 'Yes', 'No');Het resultaat van deze zoekopdracht is 'Nee'. Bekijk echter het Uitvoeringsplan samen met de eigenschappen van Compute Scalar.
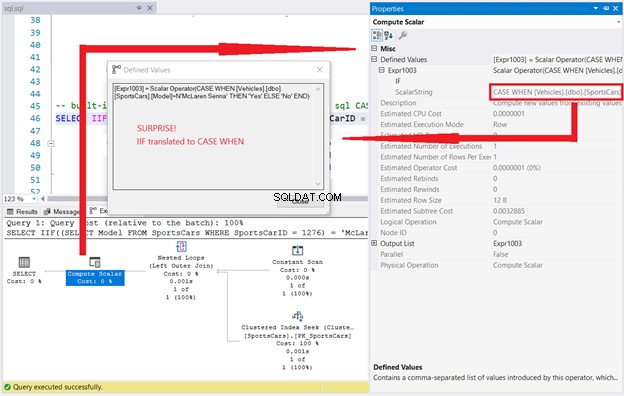
Aangezien IIF CASE WHEN is, wat denk je dat er zal gebeuren als je zoiets uitvoert?
DECLARE @averageCost MONEY = 1000000.00;
DECLARE @noOfPayments TINYINT = 0; -- intentional to force the error
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'SF90 Spider', 83333.33,MIN(@averageCost / @noOfPayments));
Dit resulteert in een Delen door Nul-fout als @noOfPayments 0 is. Hetzelfde gebeurde eerder bij punt #1.
Je vraagt je misschien af waardoor deze fout wordt veroorzaakt, omdat de bovenstaande query zal resulteren in TRUE en 83333.33 zou moeten retourneren. Controleer punt #1 opnieuw.
Dus als je met een dergelijke fout vastzit bij het gebruik van IIF, is SQL CASE de boosdoener.
COALESCE
COALESCE is ook een snelkoppeling naar een SQL CASE-expressie. Het evalueert de lijst met waarden en retourneert de eerste niet-null-waarde. In het vorige artikel over COALESCE heb ik een voorbeeld gepresenteerd dat een subquery twee keer evalueert. Maar ik gebruikte een andere methode om de SQL CASE in het uitvoeringsplan te onthullen. Hier is nog een voorbeeld dat dezelfde technieken gebruikt.
SELECT
COALESCE(m.Manufacturer + ' ','') + sc.Model AS Car
FROM SportsCars sc
LEFT JOIN Manufacturers m ON sc.ManufacturerID = m.ManufacturerID
Laten we eens kijken naar het uitvoeringsplan en de Scalaire gedefinieerde waarden berekenen.
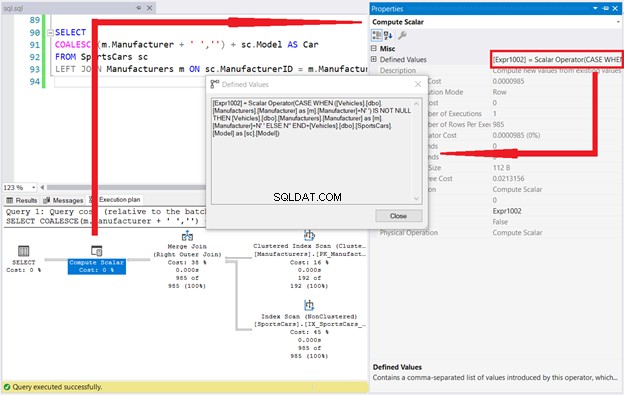
SQL CASE is in orde. Het sleutelwoord COALESCE staat nergens in het venster Defined Values. Dit bewijst het geheim achter deze functie.
Maar dat is niet alles. Hoe vaak heb je [Voertuigen].[dbo].[Styles].[Style] gezien in het venster Gedefinieerde waarden? TWEEMAAL! Dit komt overeen met de officiële Microsoft-documentatie. Stel je voor dat een van de argumenten in COALESCE een subquery is. Verdubbel vervolgens de logische uitlezingen en krijg ook de langzamere uitvoering.
KIES
KIES tot slot. Dit is vergelijkbaar met de MS Access CHOOSE-functie. Het retourneert 1 waarde uit een lijst met waarden op basis van een indexpositie. Het fungeert ook als een index in een array.
Laten we eens kijken of we de transformatie met een voorbeeld in een SQL CASE kunnen graven. Bekijk de onderstaande code:
;WITH McLarenCars AS
(
SELECT
CASE
WHEN sc.Model IN ('Artura','Speedtail','P1/ P1 GTR','P1 LM') THEN '1'
ELSE '2'
END AS [type]
,sc.Model
,s.Style
FROM SportsCars sc
INNER JOIN Styles s ON sc.StyleID = s.StyleID
WHERE sc.ManufacturerID = 108
)
SELECT
Model
,Style
,CHOOSE([Type],'Hybrid','Gasoline') AS [type]
FROM McLarenCars
Daar is ons CHOOSE-voorbeeld. Laten we nu eens kijken naar het Uitvoeringsplan en de Berekende Scalaire Gedefinieerde Waarden:
Ziet u het trefwoord KIEZEN in het venster Defined Values in Afbeelding 10? Hoe zit het met CASE WHEN?
Net als de vorige voorbeelden, is deze CHOOSE-functie slechts een suikerlaagje voor een langere CASE-expressie. En aangezien de zoekopdracht 2 items heeft voor KIEZEN, kwamen de CASE WHEN-sleutelwoorden twee keer voor. Zie het venster Gedefinieerde waarden ingesloten in een rood vak.
We hebben hier echter meerdere CASE WHEN in SQL. Dat komt door de CASE-expressie in de inner query van de CTE. Als je goed kijkt, verschijnt dat deel van de innerlijke vraag ook twee keer.
Afhaalmaaltijden
Nu de geheimen bekend zijn, wat hebben we geleerd?
- SQL CASE gedraagt zich anders wanneer geaggregeerde functies worden gebruikt. Wees voorzichtig bij het doorgeven van argumenten aan aggregatiefuncties zoals MIN, MAX of COUNT.
- Een eenvoudige CASE-expressie wordt meerdere keren geëvalueerd. Merk het op en vermijd het doorgeven van een subquery. Hoewel het syntactisch correct is, zal het slecht presteren.
- IIF, CHOOSE en COALESCE hebben vuile geheimen. Houd er rekening mee voordat u waarden aan die functies doorgeeft. Het zal transformeren in een SQL CASE. Afhankelijk van de waarden veroorzaakt u ofwel een fout of een prestatiestraf.
Ik hoop dat deze andere kijk op SQL CASE nuttig voor je is geweest. Als dat zo is, vinden je ontwikkelaarsvrienden het misschien ook leuk. Deel het alsjeblieft op je favoriete sociale mediaplatforms. En laat ons weten wat je ervan vindt in het gedeelte Opmerkingen.