In een eerdere zelfstudie, "Gegevensbestanden samenvoegen met Statistica, deel 1", introduceerden we het gebruik van Statistica voor het samenvoegen van spreadsheets. We hebben de modus voor het samenvoegen van aaneenschakelingen besproken. In deze tutorial zullen we twee andere modi bespreken:het gebruik van case-namen en variabelenamen. Deze tutorial heeft de volgende secties:
- Casenamen gebruiken om gegevensbestanden samen te voegen
- Variabelenamen gebruiken om gegevensbestanden samen te voegen
- Conclusie
Casenamen gebruiken om gegevensbestanden samen te voegen
Vervolgens zullen we gegevensbestanden (spreadsheets) samenvoegen door de rijen te matchen (ook wel cases genoemd) ). Als de rijen dezelfde naam hebben, worden de gegevens in de rijen uit de twee gegevensbestanden samengevoegd. De voorbeeldgegevensbestanden die we in het vorige artikel hebben gebruikt, bevatten geen casenaam. De naam van de zaak wordt opgegeven in kolom 1, de kolom vóór de gegevenskolommen. Gebruik dezelfde gegevens als voor het aaneenschakelen van gegevensbestanden en voeg de casenamen toe (log1 naar log6 ) naar rijen in de wlslog1.sta spreadsheet, zoals weergegeven in afbeelding 1.
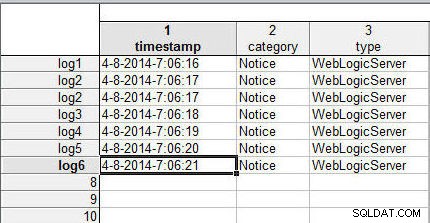
Figuur 1: Spreadsheet wlslog1
Voeg op dezelfde manier hoofdletternamen toe (log1 naar log6 ) aan elke rij in wlslog2.sta , zoals weergegeven in afbeelding 2.
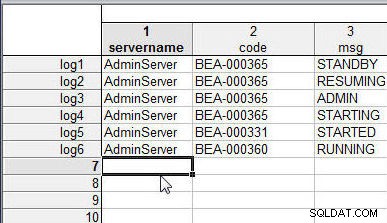
Figuur 2: Spreadsheet wlslog2
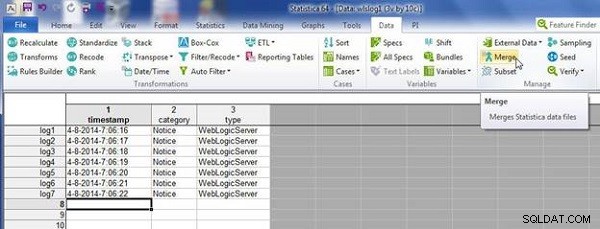
Selecteer Gegevens>Samenvoegen en, in Samenvoegopties , selecteer Modus als Overeenkomen met casenamen , zoals weergegeven in Afbeelding 3. Klik op OK .
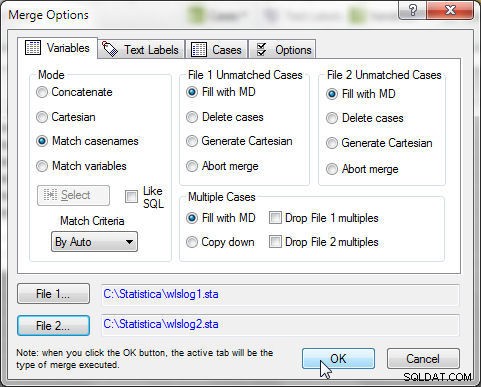
Figuur 3: wlslog1 en wlslog2 samenvoegen
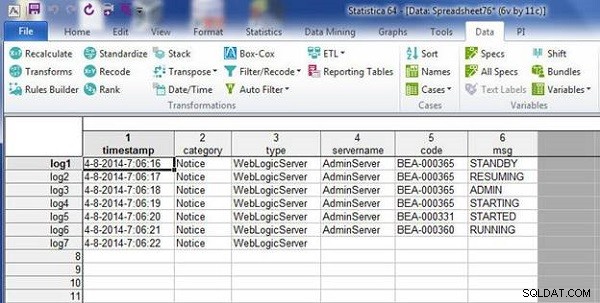
De gegevens in de wlslog1.sta spreadsheet wordt samengevoegd met de gegevens in de wlslog2.sta spreadsheet, zoals weergegeven in de resulterende spreadsheet in figuur 4.
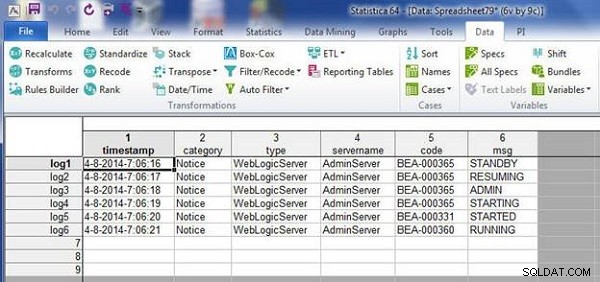
Figuur 4: Samengevoegd bestand
Bij het samenvoegen door casenamen te matchen, moet elk van de samen te voegen gegevensbestanden casenamen bevatten, anders wordt de fout weergegeven in afbeelding 5 weergegeven.
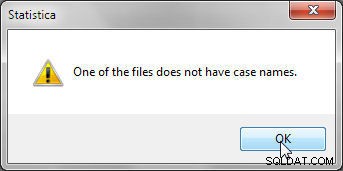
Figuur 5: Casenamen zijn vereist bij het samenvoegen door casenamen te matchen
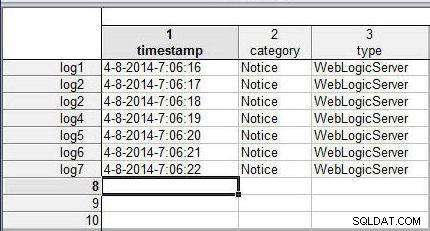
De ene spreadsheet heeft mogelijk meer cases (of rijen) dan de andere. Voeg bijvoorbeeld een 7-rij toe aan wlslog1.sta (zie figuur 6). Klik op Samenvoegen om de spreadsheets samen te voegen.
Figuur 6: Samenvoegen met een 7e rij in wlslog1.sta
Samenvoegen door casenamen te matchen met wlslog2.sta , wat hetzelfde is als voorheen met 6 casussen (rijen), zoals weergegeven in Afbeelding 28. De spreadsheets die moeten worden samengevoegd, hebben ongeëvenaarde casussen (de ene spreadsheet heeft meer casussen dan de andere). Niet-overeenkomende gevallen worden samengevoegd door standaard ontbrekende gegevens op te vullen, wat inhoudt dat de gegevenswaarden leeg zijn. De resulterende spreadsheet bevat lege ontbrekende gegevens voor niet-overeenkomende gevallen, zoals weergegeven in Afbeelding 7.
Figuur 7: Resulterende spreadsheet heeft lege ontbrekende gegevens
Samenvoegopties biedt enkele opties voor Niet-overeenkomende gevallen anders dan vullen met ontbrekende gegevens. Gebruik een spreadsheet om te demonstreren, wlslog1.sta , met een extra rij en ook een dubbele zaaknaam (log2 ), zoals weergegeven in Afbeelding 8.
Figuur 8: Spreadsheet met dubbele naam voor hoofdletters
De niet-overeenkomende gevallen kunnen worden verwijderd door Aanvragen verwijderen te selecteren in Bestand 1 Niet-overeenkomende gevallen , zoals weergegeven in figuur 9. Meerdere gevallen worden opgelost door "Drop File 1 multiples" te selecteren. Met Samenvoegmodus als Overeenkomen met casenamen , klik op OK .
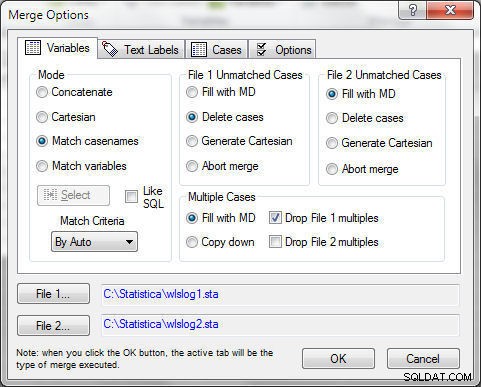
Figuur 9: File 1 Unmatched Cases>Verwijder cases
In de resulterende spreadsheet zijn beide problemen opgelost. Het niet-overeenkomende geval wordt verwijderd en het dubbele geval wordt verwijderd, zoals weergegeven in Afbeelding 10.
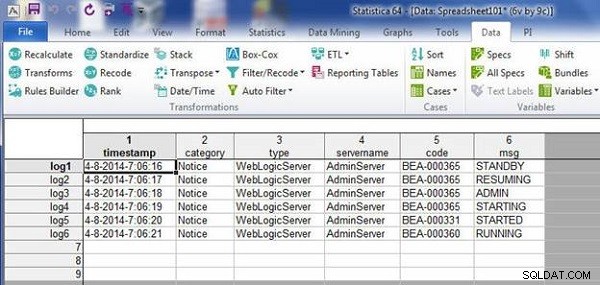
Figuur 10: Resulterende spreadsheet met ongeëvenaarde case verwijderd en de dubbele case verwijderd
Variabelenamen gebruiken om gegevensbestanden samen te voegen
Vervolgens zullen we spreadsheets samenvoegen door variabelenamen te matchen. Begin met twee spreadsheets, wlslog1.sta en wlslog2.sta , elk met de kolomnamen getoond in Afbeelding 11.
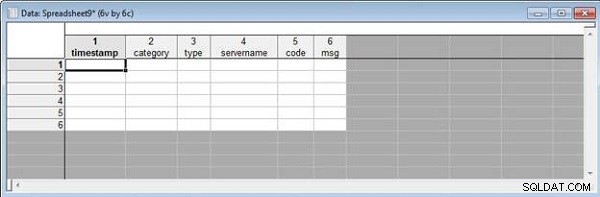
Figuur 11: Kolommen Namen in wlslog1 en wlslog2
Voeg de volgende gegevens toe aan wlslog1.sta .
4-8-2014-7:06:16,Notice,WebLogicServer,AdminServer,BEA-000365, STANDBY 4-8-2014-7:06:17,Notice,WebLogicServer,AdminServer,BEA-000365, RESUMING 4-8-2014-7:06:18,Notice,WebLogicServer,AdminServer,BEA-000365, ADMIN
De wlslog1.sta spreadsheet wordt weergegeven in Afbeelding 12.
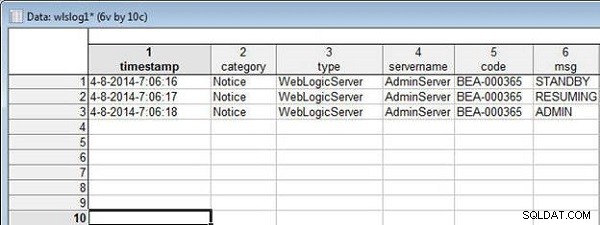
Figuur 12: Spreadsheet wlslog1.sta
Voeg de volgende gegevens toe aan wlslog2.sta .
4-8-2014-7:06:20,Notice,WebLogicServer,AdminServer,BEA-000331, STARTING 4-8-2014-7:06:21,Notice,WebLogicServer,AdminServer,BEA-000365, STARTED 4-8-2014-7:06:22,Notice,WebLogicServer,AdminServer,BEA-000360, RUNNING
De wlslog2.sta wordt weergegeven in Afbeelding 13. Selecteer Data>Samenvoegen zoals voorheen.
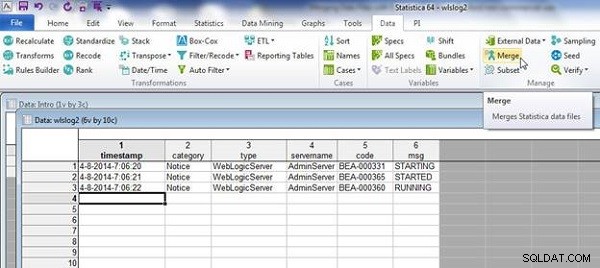
Figuur 13: Spreadsheet wlslog2.sta
In Samenvoegopties , selecteer Modus als Overeenkomstvariabelen , zoals weergegeven in Afbeelding 14. Selecteer Bestand 1 als wlslog1.sta en Bestand 2 als wlslog2.sta . De volgorde is belangrijk omdat de spreadsheet die onderaan de andere moet worden toegevoegd, Bestand 2 moet zijn . Houd u aan de Overeenkomstcriteria als Door automatisch , die automatisch de meest geschikte samenvoegcriteria kiest. De andere opties voor Match Criteria zijn Op tekst , dat gegevens vergelijkt door tekst te vergelijken; en Op numeriek , waarmee gegevens worden vergeleken door de numerieke waarden te vergelijken. Klik vervolgens op Selecteren om de variabelen te selecteren die overeenkomen.
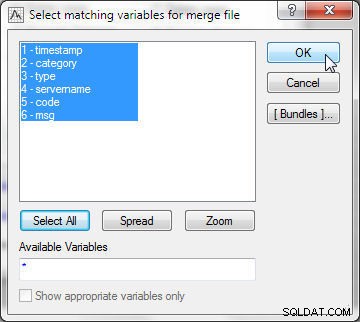
Figuur 14: Samenvoegmodus als matchvariabelen
Selecteer eerst overeenkomende variabelen voor het huidige bestand (bestand 1). Klik op Alles selecteren en klik op OK, zoals weergegeven in Afbeelding 15.
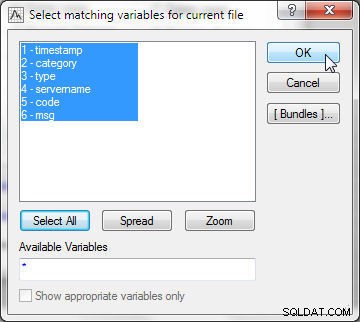
Figuur 15: Variabelen selecteren in het huidige bestand
Selecteer op dezelfde manier alle variabelen voor het samenvoegbestand (Bestand 2) en klik op OK (zie Afbeelding 16).
Figuur 16: Variabelen selecteren in bestand samenvoegen
Klik op OK in Samenvoegopties, zoals weergegeven in Afbeelding 17.
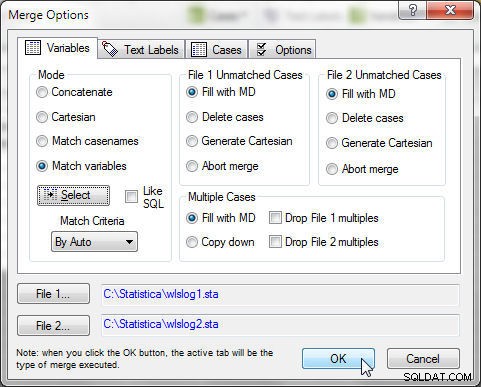
Figuur 17: Samenvoegen met modus als matchvariabelen
De twee spreadsheets worden samengevoegd door variabelenamen te matchen, zoals weergegeven in Afbeelding 18.
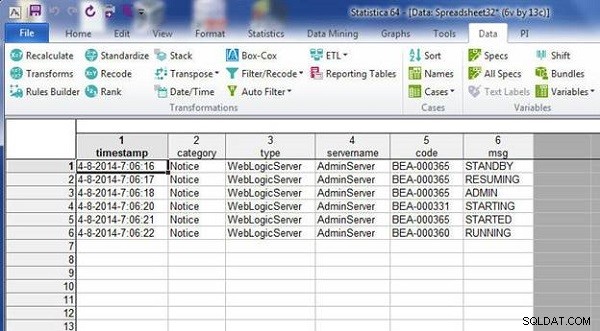
Figuur 18: Resulterende spreadsheet van samenvoegen door variabelenamen te matchen
Bij het samenvoegen van spreadsheets door variabelenamen te matchen, worden de gegevenswaarden numeriek en tekstueel gesorteerd. Voeg bijvoorbeeld twee spreadsheets samen met de 1 spreadsheet, weergegeven in Afbeelding 19.
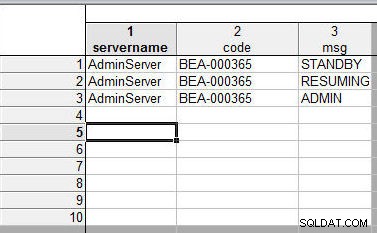
Figuur 19: Eerste spreadsheet om samen te voegen
Het 2e werkblad wordt getoond in Figuur 20. Een wijziging toegevoegd is dat de variabelenaam iets is gewijzigd in Bestand 1:“ServerType” in plaats van “servernaam”, “MessageCode” in plaats van “code” en “Bericht” in plaats van “ bericht”.
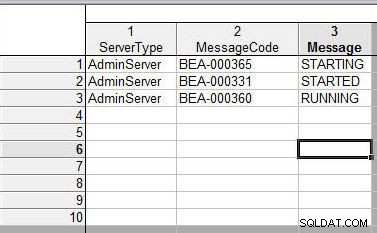
Figuur 20: Tweede spreadsheet om samen te voegen
Klik op Selecteren om de variabelen te selecteren die voor matching moeten worden gebruikt. Selecteer in Bestand 1 alle variabelen (zie Afbeelding 21).
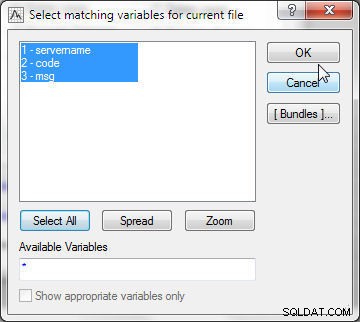
Figuur 21: Overeenkomende variabelen selecteren voor huidig bestand
Selecteer in Bestand 2 ook alle variabelen, zoals weergegeven in Afbeelding 22.
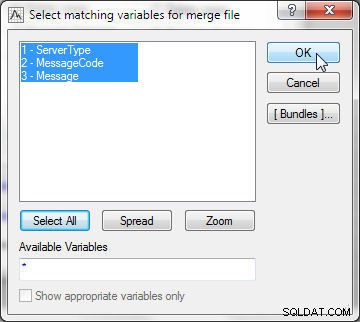
Figuur 22: Overeenkomende variabelen selecteren voor samenvoegbestand
Voeg de twee spreadsheets samen zoals eerder. De "servernaam" of "ServerType" is hetzelfde voor alle rijen en draagt niet bij aan het sorteren van gegevens in de resulterende spreadsheet. De kolomgegevenswaarden "code" of "MessageCode" worden gesorteerd als niet-hoofdlettergevoelig voor tekst; BEA-000331 is gesorteerd voor BEA-000360, die is gesorteerd vóór BEA-000365. Voor dezelfde waarde voor code BEA-000365 worden de kolomgegevens "msg" of "Message" gesorteerd op Tekst ook—ADMIN->RESUMING->STANDBY>STARTING—zoals weergegeven in Afbeelding 23.
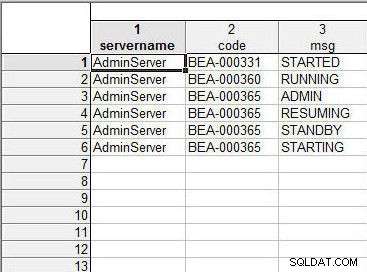
Figuur 23: Resulterend werkblad
Bij het selecteren van variabelen moeten bepaalde voorwaarden worden toegepast. Er moet ten minste één variabele worden geselecteerd om te matchen, anders wordt de fout weergegeven in Afbeelding 24 gegenereerd.
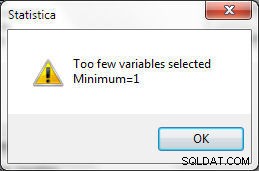
Figuur 24: Er moet minimaal 1 variabele zijn geselecteerd
Het aantal geselecteerde variabelen moet hetzelfde zijn in Bestand 1 en Bestand 2, anders wordt de fout weergegeven in Afbeelding 25 gegenereerd.
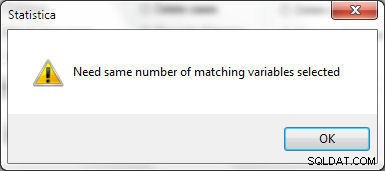
Figuur 25: Hetzelfde aantal variabelen moet worden geselecteerd in Spreadsheets om samen te voegen
Het gegevenstype van de geselecteerde variabelen moet hetzelfde zijn voor de geselecteerde variabelen. De variabelen "servername" en "ServerType" in respectievelijk Bestand 1 en Bestand 2 moeten bijvoorbeeld hetzelfde gegevenstype hebben, anders wordt de fout weergegeven in Afbeelding 26 gegenereerd.
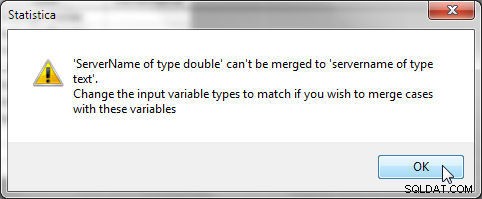
Figuur 26: Variabeletypes moeten hetzelfde zijn bij het samenvoegen door variabelen te matchen
Conclusie
In deze zelfstudie hebben we het samenvoegen van gegevensbestanden (ook wel spreadsheets genoemd) in Statistica Platform besproken met behulp van modi:Casenamen matchen en Match-variabelen.