Nu is onze community voor big data-analyse begonnen met het volledig gebruiken van Apache Spark voor de verwerking van big data. De verwerking kan voor ad-hocquery's, vooraf gebouwde query's, grafische verwerking, machine learning en zelfs voor het streamen van gegevens.
Daarom is het begrip van Spark Job Submission van groot belang voor de gemeenschap. Breid het graag uit om de lessen van de stappen die betrokken zijn bij de Apache Spark Job Submission met u te delen.
In principe heeft het twee stappen,

Vacature indienen
Spark-taak wordt automatisch verzonden wanneer een actie zoals count () wordt uitgevoerd op een RDD.
Intern runJob() om te worden aangeroepen op de SparkContext en vervolgens een beroep te doen op de planner die als onderdeel van de afleiding wordt uitgevoerd.
De planner bestaat uit 2 delen:DAG Scheduler en Task Scheduler.
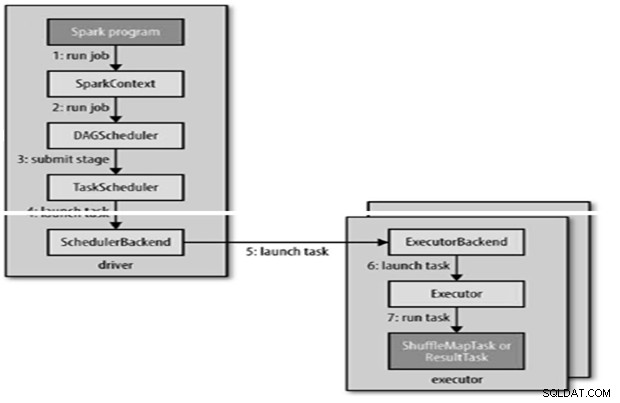
DAG-constructie
Er zijn twee soorten DAG-constructies,

- Eenvoudige Spark-taak is er een die geen shuffle nodig heeft en daarom slechts één enkele fase heeft die bestaat uit resultaattaken, zoals een alleen-kaarttaak in MapReduce
- Complexe Spark-taak omvat groeperingsbewerkingen en vereist een of meer willekeurige fasen.
- Spark's DAG-planner verandert de taak in twee fasen.
- DAG-planner is verantwoordelijk voor het opsplitsen van een fase in taken voor indiening bij de taakplanner.
- Elke taak krijgt een plaatsingsvoorkeur van de DAG-planner zodat de taakplanner kan profiteren van de gegevenslocatie.
- Kinderfasen worden pas ingediend als hun ouders het succesvol hebben afgerond.
Taakplanning
- Taakplanner stuurt een reeks taken; het gebruikt de lijst met uitvoerders die voor de toepassing worden uitgevoerd en maakt een toewijzing van taken aan uitvoerders die rekening houdt met plaatsingsvoorkeuren.
- Taakplanner wijst toe aan uitvoerders die vrije kernen hebben, elke taak krijgt standaard één kern toegewezen. Het kan worden gewijzigd door de parameter spark.task.cpus.
- Spark gebruikt Akka, een op acteurs gebaseerd platform voor het bouwen van zeer schaalbare gebeurtenisgestuurde gedistribueerde applicaties.
- Spark gebruikt de Hadoop RPC niet voor externe gesprekken.
Taakuitvoering
Een uitvoerder voert een taak als volgt uit,
- Het zorgt ervoor dat de JAR en bestandsafhankelijkheden voor de taak up-to-date zijn.
- De-serialiseert de taakcode.
- Taakcode wordt uitgevoerd.
- Taak retourneert resultaten naar het stuurprogramma, dat samenvoegt tot een eindresultaat om terug te keren naar de gebruiker.
Referentie
- De definitieve gids voor Hadoop
- Analytics &Big Data Open Source-community
Dit artikel verscheen oorspronkelijk hier. Opnieuw gepubliceerd met toestemming. Dien hier uw auteursrechtklachten in.