Dit artikel is het vierde in een reeks over optimalisatiedrempels. De serie behandelt het groeperen en aggregeren van gegevens, legt de verschillende algoritmen uit die SQL Server kan gebruiken en het kostenmodel dat helpt bij het kiezen tussen de algoritmen. In dit artikel richt ik me op overwegingen van parallellisme. Ik behandel de verschillende parallellismestrategieën die SQL Server kan gebruiken, de drempels voor het kiezen tussen een serieel en een parallel plan, en de kostenlogica die SQL Server toepast met behulp van een concept genaamd mate van parallellisme voor kostenberekening (DOP voor kosten).
Ik blijf de dbo.Orders-tabel in de PerformanceV3-voorbeelddatabase gebruiken in mijn voorbeelden. Voordat u de voorbeelden in dit artikel uitvoert, voert u de volgende code uit om een aantal onnodige indexen te verwijderen:
DROP INDEX INDIEN BESTAAT idx_nc_sid_od_cid OP dbo.Orders;DROP INDEX INDIEN BESTAAT idx_unc_od_oid_i_cid_eid OP dbo.Orders;
De enige twee indexen die in deze tabel moeten worden achtergelaten, zijn idx_cl_od (geclusterd met orderdatum als sleutel) en PK_Orders (niet-geclusterd met orderid als sleutel).
Parallistische strategieën
Naast het moeten kiezen tussen verschillende groeperings- en aggregatiestrategieën (vooraf besteld Stream Aggregate, Sort + Stream Aggregate, Hash Aggregate), moet SQL Server ook kiezen of het een serieel of een parallel abonnement wil. In feite kan het kiezen tussen meerdere verschillende parallellismestrategieën. SQL Server maakt gebruik van kostenlogica die resulteert in optimalisatiedrempels die onder verschillende omstandigheden de voorkeur geven aan de ene strategie boven de andere. We hebben de kostenlogica die SQL Server gebruikt in seriële plannen in de vorige delen van de serie al uitgebreid besproken. In deze sectie zal ik een aantal parallellisme-strategieën introduceren die SQL Server kan gebruiken voor het afhandelen van groepering en aggregatie. In eerste instantie zal ik niet ingaan op de details van de kostenlogica, maar alleen de beschikbare opties beschrijven. Verderop in het artikel zal ik uitleggen hoe de kostprijsformules werken, en een belangrijke factor in die formules die DOP voor kostprijsberekening wordt genoemd.
Zoals u later zult leren, houdt SQL Server rekening met het aantal logische CPU's in de machine in zijn kostprijsformules voor parallelle plannen. In mijn voorbeelden, tenzij ik anders zeg, ga ik ervan uit dat het doelsysteem 8 logische CPU's heeft. Als je de voorbeelden wilt uitproberen die ik zal geven, om dezelfde plannen en kostenwaarden te krijgen als ik, moet je de code ook uitvoeren op een machine met 8 logische CPU's. Als uw machine toevallig een ander aantal CPU's heeft, kunt u een machine met 8 CPU's emuleren - voor kostendoeleinden - zoals:
DBCC OPTIMIZER_WHATIF(CPU's, 8);
Ook al is deze tool niet officieel gedocumenteerd en ondersteund, het is best handig voor onderzoeks- en leerdoeleinden.
De tabel Orders in onze voorbeelddatabase heeft 1.000.000 rijen met order-ID's in het bereik van 1 tot 1.000.000. Om drie verschillende parallellismestrategieën voor groepering en aggregatie te demonstreren, filter ik bestellingen waarvan de bestellings-ID groter is dan of gelijk aan 300001 (700.000 overeenkomsten) en groepeer ik de gegevens op drie verschillende manieren (per custid [20.000 groepen vóór filtering], door empid [500 groepen], en door shipperid [5 groepen]), en bereken het aantal bestellingen per groep.
Gebruik de volgende code om indexen te maken die de gegroepeerde zoekopdrachten ondersteunen:
CREATE INDEX idx_oid_i_eid OP dbo.Orders(orderid) INCLUDE(empid);CREATE INDEX idx_oid_i_sid OP dbo.Orders(orderid) INCLUDE(shipperid);CREATE INDEX idx_oid_i_cid ON dbo.Orders(custid) INCLUSIEF pre>De volgende zoekopdrachten implementeren de bovengenoemde filtering en groepering:
-- Query 1:Serieel SELECT custid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION (MAXDOP 1); -- Query 2:Parallel, niet lokaal/globaal SELECT custid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid; -- Query 3:Lokale parallelle globale parallelle SELECT empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Query 4:Lokale parallelle globale seriële SELECT verzendperiode, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=300001GROEP OP verzendperiode;Merk op dat Query 1 en Query 2 hetzelfde zijn (beide groeperen op custid), alleen dwingt de eerste een serieel plan af en de laatste krijgt een parallel plan op een machine met 8 CPU's. Ik gebruik deze twee voorbeelden om de seriële en parallelle strategieën voor dezelfde zoekopdracht te vergelijken.
Afbeelding 1 toont de geschatte plannen voor alle vier de zoekopdrachten:
Figuur 1:Parallellismestrategieën
Maak je voorlopig geen zorgen over de kostenwaarden in de afbeelding en de vermelding van de term DOP voor kostprijsberekening. Ik kom daar later op terug. Richt u eerst op het begrijpen van de strategieën en de verschillen daartussen.
De strategie die wordt gebruikt in het serieplan voor Query 1 zal u bekend voorkomen uit de vorige delen van de serie. Het plan filtert de relevante orders met behulp van een zoekfunctie in de dekkingsindex die u eerder hebt gemaakt. Vervolgens, met het geschatte aantal rijen dat moet worden gegroepeerd en geaggregeerd, geeft de optimizer de voorkeur aan de Hash Aggregate-strategie boven de Sort + Stream Aggregate-strategie.
Het plan voor Query 2 maakt gebruik van een eenvoudige parallellismestrategie waarbij slechts één aggregaatoperator wordt gebruikt. Een parallelle Index Seek-operator distribueert pakketten met rijen naar de verschillende threads op een round-robin-manier. Elk rijenpakket kan meerdere afzonderlijke klant-ID's bevatten. Om ervoor te zorgen dat een enkele aggregatieoperator de juiste definitieve groepsaantallen kan berekenen, moeten alle rijen die tot dezelfde groep behoren, door dezelfde thread worden afgehandeld. Om deze reden wordt een parallellisme (Repartition Streams) exchange-operator gebruikt om de streams te herpartitioneren volgens de groeperingsset (custid). Ten slotte wordt een parallellisme (Gather Streams) exchange-operator gebruikt om de streams van de meerdere threads te verzamelen in een enkele stroom resultaatrijen.
De plannen voor Query 3 en Query 4 maken gebruik van een meer complexe parallellismestrategie. De plannen beginnen vergelijkbaar met het plan voor Query 2, waar een parallelle Index Seek-operator rijenpakketten naar verschillende threads distribueert. Vervolgens wordt het aggregatiewerk in twee stappen uitgevoerd:één aggregatie-operator groepeert en aggregeert lokaal de rijen van de huidige thread (let op het partiëleagg1004-resultaatlid), en een tweede aggregatie-operator groepeert en aggregeert globaal de resultaten van de lokale aggregaties (let op de globalagg1005 resultaat lid). Elk van de twee geaggregeerde stappen - lokaal en globaal - kan elk van de geaggregeerde algoritmen gebruiken die ik eerder in de serie heb beschreven. Beide plannen voor Query 3 en Query 4 beginnen met een lokale Hash Aggregate en gaan verder met een globale Sort + Stream Aggregate. Het verschil tussen de twee is dat de eerste parallellisme gebruikt in beide stappen (vandaar dat er een Repartition Streams-uitwisseling wordt gebruikt tussen de twee en een Gather Streams-uitwisseling na het globale aggregaat), en dat de laatste het lokale aggregaat in een parallelle zone en de globale zone afhandelt. aggregeren in een seriële zone (vandaar een Gather Streams-uitwisseling wordt gebruikt tussen de twee).
Wanneer u onderzoek doet naar query-optimalisatie in het algemeen en parallellisme in het bijzonder, is het goed om bekend te zijn met tools waarmee u verschillende optimalisatieaspecten kunt controleren om hun effecten te zien. U weet al hoe u een serieel plan moet forceren (met een MAXDOP 1-hint) en hoe u een omgeving moet emuleren die, voor kostendoeleinden, een bepaald aantal logische CPU's heeft (DBCC OPTIMIZER_WHATIF, met de optie CPU's). Een ander handig hulpmiddel is de query-hint ENABLE_PARALLEL_PLAN_PREFERENCE (geïntroduceerd in SQL Server 2016 SP1 CU2), die het parallellisme maximaliseert. Wat ik hiermee bedoel is dat als een parallel plan wordt ondersteund voor de query, parallellisme de voorkeur heeft in alle delen van het plan die parallel kunnen worden afgehandeld, alsof het gratis is. In figuur 1 ziet u bijvoorbeeld dat het plan voor query 4 standaard het lokale aggregaat in een seriële zone en het globale aggregaat in een parallelle zone verwerkt. Hier is dezelfde query, alleen deze keer met de ENABLE_PARALLEL_PLAN_PREFERENCE query-hint toegepast (we noemen het Query 5):
SELECTEER verzendperiode, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROEP OP verzendperiodeOPTIE(GEBRUIK HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Het plan voor Query 5 wordt getoond in Afbeelding 2:
Figuur 2:Maximaliseren van parallellisme
Merk op dat deze keer zowel de lokale als de globale aggregaten in parallelle zones worden verwerkt.
Keuze van serie/parallel abonnement
Bedenk dat SQL Server tijdens query-optimalisatie meerdere kandidaatplannen maakt en degene met de laagste kosten kiest uit de plannen die het heeft geproduceerd. De term kosten is een beetje een verkeerde benaming, aangezien het kandidaat-plan met de laagste kosten, volgens de schattingen, het plan met de laagste doorlooptijd zou moeten zijn, niet het plan met de laagste hoeveelheid middelen die in het algemeen worden gebruikt. Bijvoorbeeld, tussen een serieel kandidaatplan en een parallel plan dat voor dezelfde query is geproduceerd, zal het parallelle plan waarschijnlijk meer bronnen gebruiken, omdat het exchange-operators moet gebruiken die de threads synchroniseren (streams distribueren, herpartitioneren en verzamelen). Om ervoor te zorgen dat het parallelle plan minder tijd nodig heeft om te worden uitgevoerd dan het seriële plan, moeten de besparingen die worden bereikt door het werk met meerdere threads te doen, opwegen tegen het extra werk dat door de exchange-operators wordt gedaan. En dit moet worden weerspiegeld in de kostenformules die SQL Server gebruikt wanneer er sprake is van parallellisme. Geen eenvoudige taak om nauwkeurig uit te voeren!
Naast dat de kosten van het parallelle abonnement lager moeten zijn dan de kosten van het seriële abonnement om de voorkeur te krijgen, moeten de kosten van het alternatief voor het seriële abonnement groter zijn dan of gelijk zijn aan de kostendrempel voor parallellisme . Dit is een serverconfiguratieoptie die standaard is ingesteld op 5 en die voorkomt dat query's met redelijk lage kosten parallel worden afgehandeld. De gedachte hier is dat een systeem met een groot aantal kleine query's over het algemeen meer baat zou hebben bij het gebruik van seriële plannen, in plaats van veel bronnen te verspillen aan het synchroniseren van threads. U kunt nog steeds meerdere query's hebben terwijl seriële plannen tegelijkertijd worden uitgevoerd, waarbij efficiënt gebruik wordt gemaakt van de multi-CPU-bronnen van de machine. In feite willen veel SQL Server-professionals de kostendrempel voor parallellisme verhogen van de standaardwaarde van 5 naar een hogere waarde. Een systeem dat een vrij klein aantal grote zoekopdrachten tegelijk uitvoert, zou veel meer baat hebben bij het gebruik van parallelle plannen.
Om samen te vatten:om SQL Server de voorkeur te geven aan een parallel plan boven het seriële alternatief, moeten de kosten van het seriële plan ten minste de kostendrempel voor parallellisme zijn en moeten de kosten van het parallelle plan lager zijn dan de kosten van het seriële plan (wat inhoudt dat mogelijk kortere looptijd).
Voordat ik inga op de details van de werkelijke kostprijsformules, illustreer ik met voorbeelden verschillende scenario's waarbij een keuze wordt gemaakt tussen seriële en parallelle plannen. Zorg ervoor dat uw systeem 8 logische CPU's aanneemt om querykosten te krijgen die vergelijkbaar zijn met die van mij als u de voorbeelden wilt uitproberen.
Overweeg de volgende vragen (we noemen ze Query 6 en Query 7):
-- Query 6:Serial SELECT empid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; -- Query 7:Geforceerde parallelle SELECT empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=4000001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));De plannen voor deze zoekopdrachten worden weergegeven in figuur 3.
Figuur 3:Seriekosten
Hier zijn de [geforceerde] parallelle abonnementskosten lager dan de seriële abonnementskosten; de kosten van het seriële abonnement zijn echter lager dan de standaardkostendrempel voor parallellisme van 5, vandaar dat SQL Server standaard het seriële abonnement heeft gekozen.
Overweeg de volgende vragen (we noemen ze Query 8 en Query 9):
-- Query 8:Parallel SELECT empid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Query 9:gedwongen serieel SELECT empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empidOPTION (MAXDOP 1);De plannen voor deze zoekopdrachten worden weergegeven in figuur 4.
Figuur 4:Seriekosten>=kostendrempel voor parallellisme, parallelle kosten
Hier zijn de [geforceerde] seriële abonnementskosten groter dan of gelijk aan de kostendrempel voor parallellisme, en zijn de parallelle abonnementskosten lager dan de seriële abonnementskosten, vandaar dat SQL Server standaard het parallelle abonnement heeft gekozen.
Overweeg de volgende vragen (we noemen ze Query 10 en Query 11):
-- Query 10:Serieel SELECT *FROM dbo.OrdersWHERE orderid>=100000; -- Query 11:Geforceerde parallelle SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));De plannen voor deze zoekopdrachten worden weergegeven in figuur 5.
Figuur 5:Seriekosten>=kostendrempel voor parallellisme, parallelle kosten>=seriële kosten
Hier zijn de kosten van het seriële plan groter dan of gelijk aan de kostendrempel voor parallellisme; de kosten van het seriële abonnement zijn echter lager dan de kosten van het [geforceerde] parallelle abonnement, vandaar dat SQL Server standaard het seriële abonnement heeft gekozen.
Er is nog iets dat je moet weten over het maximaliseren van parallellisme met de ENABLE_PARALLEL_PLAN_PREFERENCE-hint. Om ervoor te zorgen dat SQL Server zelfs een parallel plan kan gebruiken, moet er een mogelijkheid zijn voor parallellisme, zoals een residuaal predikaat, een sortering, een aggregaat, enzovoort. Een plan dat alleen een indexscan of indexzoekopdracht toepast zonder een residuaal predikaat en zonder enige andere mogelijkheid tot parallellisme, wordt verwerkt met een serieel plan. Beschouw de volgende zoekopdrachten als een voorbeeld (we noemen ze Query 12 en Query 13):
-- Query 12 SELECTEER *FROM dbo.OrdersOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- Query 13 SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));De plannen voor deze zoekopdrachten worden weergegeven in figuur 6.
Figuur 6:Parallellisme-enabler
Query 12 krijgt ondanks de hint een serieel plan, omdat er geen parallellisme mogelijk is. Query 13 krijgt een parallel plan omdat er een residuaal predikaat bij betrokken is.
DOP berekenen en testen voor kostenberekening
Microsoft moest de kostenformules kalibreren in een poging om lagere parallelle abonnementskosten te krijgen dan de seriële abonnementskosten een kortere runtime weerspiegelen en vice versa. Een mogelijk idee was om de CPU-kosten van de seriële operator te nemen en deze eenvoudig te delen door het aantal logische CPU's in de machine om de CPU-kosten van de parallelle operator te produceren. Het logische aantal CPU's in de machine is de belangrijkste factor die de mate van parallellisme van de query bepaalt, of kortweg DOP (het aantal threads dat kan worden gebruikt in een parallelle zone in het plan). Het simplistische denken hier is dat als een operator T-tijdseenheden nodig heeft om te voltooien bij het gebruik van één thread, en de mate van parallellisme van de query D is, de operator T/D-tijd nodig heeft om te voltooien bij gebruik van D-threads. In de praktijk liggen de zaken niet zo eenvoudig. U hebt bijvoorbeeld meestal meerdere query's tegelijkertijd uitgevoerd en niet slechts één, in welk geval een enkele query niet alle CPU-bronnen van de machine zal krijgen. Dus kwam Microsoft met het idee van mate van parallellisme voor kostenberekening (DOP voor kosten, kortom). Deze maat is doorgaans lager dan het aantal logische CPU's in de machine en is de factor waarmee de CPU-kosten van de seriële operator worden gedeeld om de CPU-kosten van de parallelle operator te berekenen.
Normaal gesproken wordt DOP voor kostprijsberekening berekend als het aantal logische CPU's gedeeld door 2, met behulp van integer-deling. Er zijn wel uitzonderingen. Als het aantal CPU's 2 of 3 is, wordt DOP voor kostprijsberekening ingesteld op 2. Bij 4 of meer CPU's wordt DOP voor kostprijsberekening opnieuw ingesteld op #CPU's / 2, waarbij gebruik wordt gemaakt van deling op gehele getallen. Dat is tot een bepaald maximum, dat afhangt van de hoeveelheid geheugen die beschikbaar is voor de machine. In een machine met maximaal 4.096 MB geheugen is de maximale DOP voor kosten 8; met meer dan 4.096 MB is de maximale DOP voor kosten 32.
Om deze logica te testen, weet u al hoe u een gewenst aantal logische CPU's kunt emuleren met DBCC OPTIMIZER_WHATIF, met de optie CPU's, zoals:
DBCC OPTIMIZER_WHATIF(CPU's, 8);Door dezelfde opdracht te gebruiken met de optie MemoryMBs, kunt u een gewenste hoeveelheid geheugen in MB's emuleren, zoals:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);Gebruik de volgende code om de bestaande status van de geëmuleerde opties te controleren:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF (status); DBCC TRACEOFF(3604);Gebruik de volgende code om alle opties te resetten:
DBCC OPTIMIZER_WHATIF(ResetAll);Hier is een T-SQL-query die u kunt gebruiken om DOP te berekenen voor kosten op basis van een ingevoerd aantal logische CPU's en hoeveelheid geheugen:
DECLARE @NumCPU's ALS INT =8, @MemoryMB's ALS INT =16384; SELECT CASE WHEN @NumCPUs =1 THEN 1 WHEN @NumCPUs <=3 THEN 2 WHEN @NumCPUs>=4 THEN (SELECTEER MIN(n) FROM ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) AS D2(n)) EINDIG ALS DOP4CFROM ( VALUES( CASE WHEN @MemoryMBs <=4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C);Met de opgegeven invoerwaarden levert deze query 4 op.
Tabel 1 geeft de DOP weer voor kosten die u krijgt op basis van het logische aantal CPU's en de hoeveelheid geheugen in uw machine.
| #CPU's | DOP voor kosten wanneer MemoryMBs <=4096 | DOP voor kosten wanneer MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tabel 1:DOP voor kostenberekening
Laten we als voorbeeld de eerder getoonde Query 1 en Query 2 opnieuw bekijken:
-- Query 1:Gedwongen serienummer SELECT custid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION (MAXDOP 1); -- Query 2:Natuurlijk parallel SELECT custid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid;
De plannen voor deze zoekopdrachten worden weergegeven in figuur 7.
 Figuur 7:DOP voor kosten
Figuur 7:DOP voor kosten
Query 1 dwingt een serieel plan af, terwijl Query 2 een parallel plan krijgt in mijn omgeving (8 logische CPU's en 16.384 MB geheugen emuleert). Dit betekent dat DOP voor kostprijsberekening in mijn omgeving 4 is. Zoals vermeld, worden de CPU-kosten van een parallelle operator berekend als de CPU-kosten van de seriële operator gedeeld door DOP voor kostprijsberekening. Je kunt zien dat dat inderdaad het geval is in ons parallelle plan met de Index Seek- en Hash Aggregate-operators die parallel worden uitgevoerd.
Wat betreft de kosten van de beursoperators, deze bestaan uit opstartkosten en een aantal constante kosten per rij, die u eenvoudig kunt reverse-engineeren.
Merk op dat in de eenvoudige parallelle groeperings- en aggregatiestrategie, die hier wordt gebruikt, de kardinaliteitsschattingen in de seriële en parallelle plannen hetzelfde zijn. Dat komt omdat er maar één aggregaatoperator in dienst is. Later zul je zien dat de dingen anders zijn als je de lokale/globale strategie gebruikt.
De volgende query's illustreren het effect van het aantal logische CPU's en het aantal betrokken rijen op de querykosten (10 query's, met stappen van 100.000 rijen):
SELECT empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=900001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=800001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=700001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=600001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=500001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=200001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=100001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=000001GROUP BY empid;
Afbeelding 8 toont de resultaten.
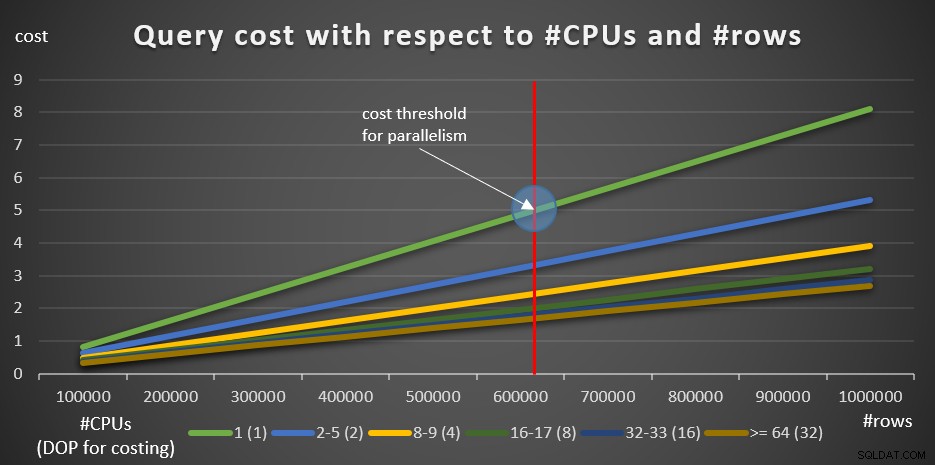
Figuur 8:Querykosten met betrekking tot #CPU's en #rijen
De groene lijn geeft de kosten weer van de verschillende zoekopdrachten (met de verschillende aantallen rijen) met behulp van een serieel plan. De andere lijnen vertegenwoordigen de kosten van de parallelle plannen met verschillende aantallen logische CPU's, en hun respectievelijke DOP voor kostenberekening. De rode lijn geeft het punt aan waar de seriële querykosten 5 zijn:de standaardkostendrempel voor het instellen van parallellisme. Links van dit punt (minder rijen om te groeperen en te aggregeren), normaal gesproken zal de optimizer geen parallel plan overwegen. Om de kosten van parallelle plannen onder de kostendrempel voor parallellisme te kunnen onderzoeken, kunt u twee dingen doen. Een optie is om de vraaghint ENABLE_PARALLEL_PLAN_PREFERENCE te gebruiken, maar ter herinnering:deze optie maximaliseert parallellisme in plaats van het alleen maar te forceren. Als dat niet het gewenste effect is, kunt u de kostendrempel voor parallellisme gewoon uitschakelen, zoals:
EXEC sp_configure 'toon geavanceerde opties', 1; HERCONFIGUREREN; EXEC sp_configure 'kostendrempel voor parallellisme', 0; EXEC sp_configure 'toon geavanceerde opties', 0; HERCONFIGUREREN;
Dat is natuurlijk geen slimme zet in een productiesysteem, maar prima bruikbaar voor onderzoeksdoeleinden. Dat is wat ik deed om de informatie voor de grafiek in figuur 8 te produceren.
Beginnend met 100.000 rijen en het toevoegen van 100K-stappen, lijken alle grafieken te impliceren dat een kostendrempel voor parallellisme geen factor was, een parallel plan zou altijd de voorkeur hebben gehad. Dat is inderdaad het geval met onze zoekopdrachten en het aantal betrokken rijen. Probeer echter een kleiner aantal rijen, te beginnen met 10K en te verhogen met stappen van 10K met behulp van de volgende vijf zoekopdrachten (houd de kostendrempel voor parallellisme voorlopig uitgeschakeld):
SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=990001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=980001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=970001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=960001GROUP BY empid; SELECTEER empid, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=950001GROUP BY empid;
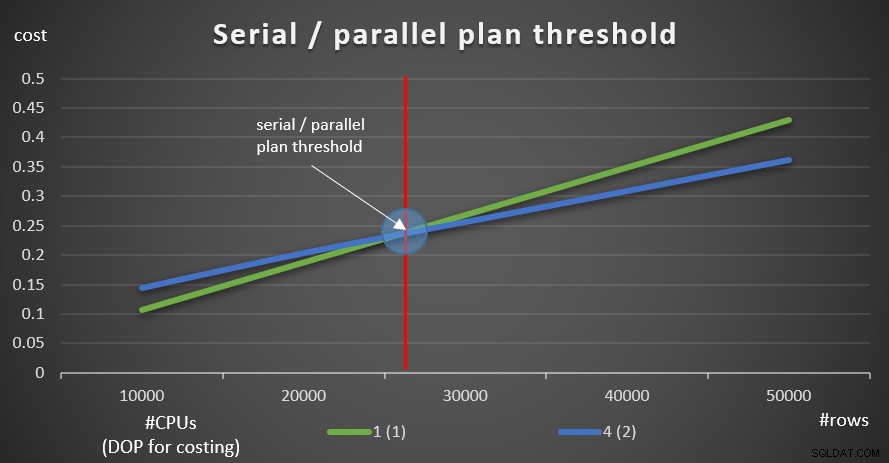
Afbeelding 9 toont de querykosten met zowel seriële als parallelle abonnementen (4 CPU's emuleren, DOP voor kosten 2).
 Figuur 9:Serieel / drempel voor parallel abonnement
Figuur 9:Serieel / drempel voor parallel abonnement
Zoals u kunt zien, is er een optimalisatiedrempel tot waar het seriële plan de voorkeur heeft en waarboven het parallelle plan de voorkeur heeft. Zoals gezegd, in een normaal systeem waarbij u de kostendrempel voor parallellisme-instelling op de standaardwaarde van 5 of hoger houdt, is de effectieve drempel sowieso hoger dan in deze grafiek.
Eerder vermeldde ik dat wanneer SQL Server kiest voor de eenvoudige strategie voor groepering en aggregatie van parallellisme, de kardinaliteitsschattingen van de seriële en parallelle plannen hetzelfde zijn. De vraag is hoe SQL Server omgaat met de kardinaliteitsschattingen voor de lokale/globale parallellismestrategie.
Om dit uit te zoeken, gebruik ik Query 3 en Query 4 uit onze eerdere voorbeelden:
-- Query 3:Lokale parallelle globale parallelle SELECT empid, COUNT(*) AS nummordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Query 4:Lokale parallelle globale seriële SELECT verzendperiode, COUNT(*) AS nummersFROM dbo.OrdersWHERE orderid>=300001GROEP OP verzendperiode;
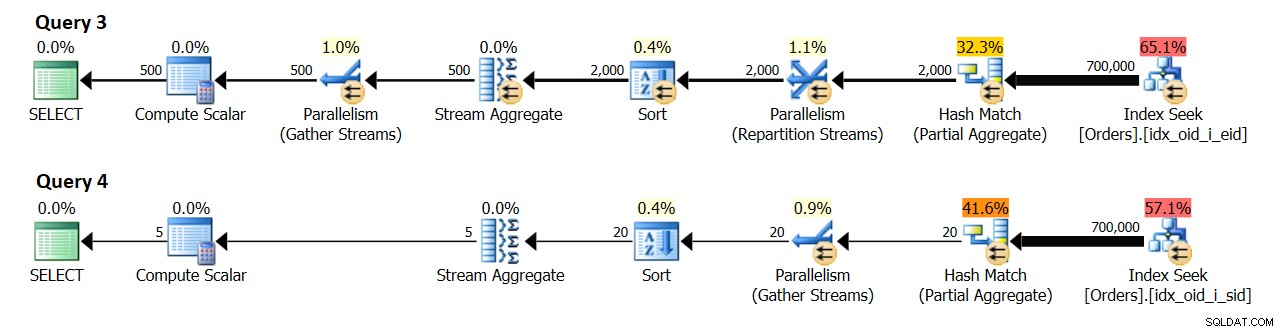
In een systeem met 8 logische CPU's en een effectieve DOP voor een kostprijs van 4, kreeg ik de plannen weergegeven in figuur 10.
 Figuur 10:Kardinaliteitsschatting
Figuur 10:Kardinaliteitsschatting
Query 3 groepeert de bestellingen op empid. Uiteindelijk worden 500 verschillende groepen werknemers verwacht.
Query 4 groepeert de bestellingen op verzendperiode. Er worden uiteindelijk 5 verschillende verzendgroepen verwacht.
Vreemd genoeg lijkt het erop dat de kardinaliteitsschatting voor het aantal groepen geproduceerd door het lokale aggregaat {aantal verschillende groepen verwacht door elke thread} * {DOP voor kosten} is. In de praktijk realiseer je je dat het aantal meestal twee keer zo groot zal zijn, omdat het de DOP is voor uitvoering (ook bekend als gewoon DOP), die voornamelijk is gebaseerd op het aantal logische CPU's. Dit deel is een beetje lastig te emuleren voor onderzoeksdoeleinden, aangezien de opdracht DBCC OPTIMIZER_WHATIF met de optie CPU's invloed heeft op de berekening van DOP voor kostprijsberekening, maar DOP voor uitvoering zal niet groter zijn dan het werkelijke aantal logische CPU's dat uw SQL Server-instantie ziet. Dit aantal is in wezen gebaseerd op het aantal planners waarmee SQL Server begint. Je kunt controle over het aantal planners SQL Server begint met het gebruik van de -P{ #schedulers } opstartparameter, maar dat is een wat agressievere onderzoekstool in vergelijking met een sessie-optie.
In ieder geval, zonder enige middelen te emuleren, heeft mijn testmachine 4 logische CPU's, wat resulteert in DOP voor 2 kosten en DOP voor uitvoering 4. In mijn omgeving toont het lokale aggregaat in het plan voor Query 3 een schatting van 1.000 resultaatgroepen (500 x 2), en een werkelijke van 2.000 (500 x 4). Evenzo toont het lokale aggregaat in het plan voor Query 4 een schatting van 10 resultaatgroepen (5 x 2) en een werkelijke waarde van 20 (5 x 4).
Als je klaar bent met experimenteren, voer je de volgende code uit om op te schonen:
-- Stel de kostendrempel voor parallellisme in op standaard EXEC sp_configure 'toon geavanceerde opties', 1; HERCONFIGUREREN; EXEC sp_configure 'kostendrempel voor parallellisme', 5; EXEC sp_configure 'toon geavanceerde opties', 0; RECONFIGURE;GO -- Reset OPTIMIZER_WHATIF opties DBCC OPTIMIZER_WHATIF(ResetAll); -- Drop indexen DROP INDEX idx_oid_i_sid OP dbo.Orders;DROP INDEX idx_oid_i_eid OP dbo.Orders;DROP INDEX idx_oid_i_cid OP dbo.Orders;
Conclusie
In dit artikel heb ik een aantal parallellisme-strategieën beschreven die SQL Server gebruikt om groepering en aggregatie af te handelen. Een belangrijk concept om te begrijpen bij de optimalisatie van query's met parallelle plannen is de mate van parallellisme (DOP) voor kostenberekening. Ik liet een aantal optimalisatiedrempels zien, waaronder een drempel tussen seriële en parallelle plannen, en de kostendrempel voor parallellisme. De meeste van de concepten die ik hier heb beschreven, zijn niet uniek voor groepering en aggregatie, maar zijn net zo toepasbaar voor overwegingen met parallelle plannen in SQL Server in het algemeen. Volgende maand ga ik verder met de serie door optimalisatie te bespreken met herschrijvingen van zoekopdrachten.