Ik heb onlangs een e-mailvraag ontvangen van iemand in de community over de CLR_MANUAL_EVENT wacht type; in het bijzonder hoe problemen op te lossen waarbij dit wachten plotseling veel voorkomt voor een bestaande werkbelasting die sterk afhankelijk was van typen ruimtelijke gegevens en query's met behulp van de ruimtelijke methoden in SQL Server.
Als consultant is mijn eerste vraag bijna altijd:"Wat is er veranderd?" Maar in dit geval, zoals in zoveel gevallen, was ik er zeker van dat er niets was veranderd met de code van de applicatie of de werkbelastingspatronen. Dus mijn eerste stop was om de CLR_MANUAL_EVENT . op te halen wacht in de SQLskills.com Wait Types Library om te zien welke andere informatie we al hebben verzameld over dit type wait, aangezien ik niet vaak problemen zie met wachten in SQL Server. Wat ik echt interessant vond, was de grafiek/heatmap van gebeurtenissen voor dit type wacht, geleverd door SentryOne bovenaan de pagina:
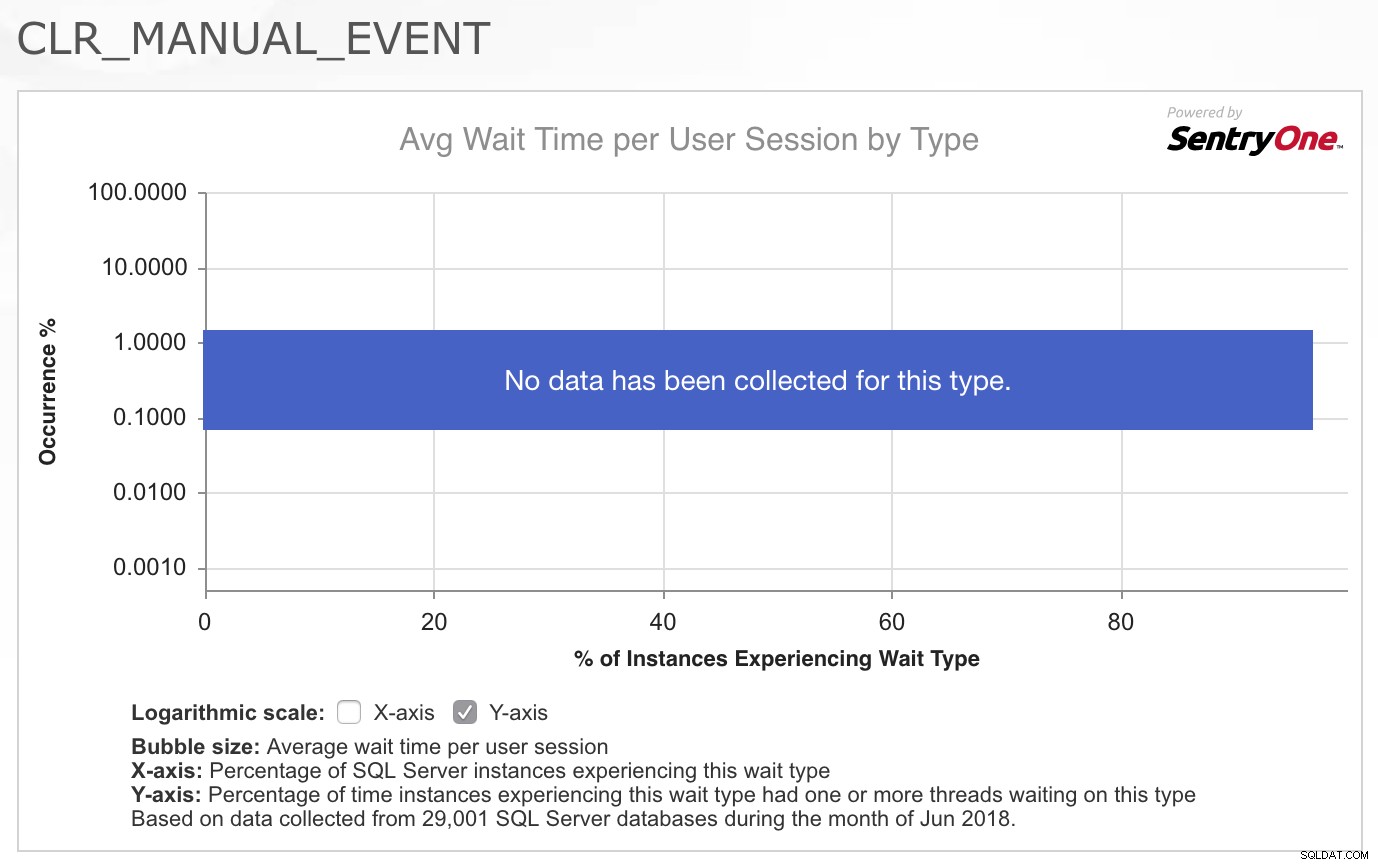
Het feit dat er voor dit type geen gegevens zijn verzameld in een goede dwarsdoorsnede van hun klanten, bevestigde voor mij echt dat dit niet iets is dat vaak een probleem is, dus ik was geïntrigeerd door het feit dat deze specifieke werklast nu vertoonde problemen met dit wachten. Ik wist niet zeker waar ik heen moest om het probleem verder te onderzoeken, dus antwoordde ik de e-mail en zei dat het me speet dat ik niet verder kon helpen, omdat ik geen idee had wat de letterlijke tientallen threads zou veroorzaken die ruimtelijke query's uitvoeren op ineens moet ik 2-4 seconden per keer wachten op dit wachttype.
Een dag later ontving ik een vriendelijke follow-up e-mail van de persoon die de vraag stelde, die me liet weten dat ze het probleem hadden opgelost. Er was inderdaad niets veranderd in de daadwerkelijke werkbelasting van de applicatie, maar er was een verandering in de omgeving die plaatsvond. Een softwarepakket van derden werd door hun beveiligingsteam op alle servers in hun infrastructuur geïnstalleerd en deze software verzamelde gegevens met tussenpozen van vijf minuten en zorgde ervoor dat de .NET-afvalverwerkingsverwerking ongelooflijk agressief werd en "gek werd" als ze zeiden. Gewapend met deze informatie en wat van mijn eerdere kennis van .NET-ontwikkeling, besloot ik dat ik hier wat mee wilde spelen en kijken of ik het gedrag kon reproduceren en hoe we de oorzaken verder konden oplossen.
Achtergrondinformatie
In de loop der jaren heb ik altijd de PSSQL-blog op MSDN gevolgd, en dat is meestal een van mijn favoriete locaties als ik me herinner dat ik ergens in het verleden over een probleem met SQL Server heb gelezen, maar ik kan ' onthoud niet alle details.
Er is een blogbericht met de titel Hoge wachttijden op CLR_MANUAL_EVENT en CLR_AUTO_EVENT door Jack Li uit 2008 waarin wordt uitgelegd waarom deze wachttijden veilig kunnen worden genegeerd in de totale sys.dm_os_wait_stats DMV aangezien de wachttijden onder normale omstandigheden plaatsvinden, maar er wordt niet ingegaan op wat te doen als de wachttijden te lang zijn, of wat de oorzaak kan zijn dat ze in meerdere threads in sys.dm_os_waiting_tasks worden gezien actief.
Er is nog een blogpost van Jack Li uit 2013 met de titel Een prestatieprobleem met CLR-afvalverzameling en SQL-CPU-affiniteitsinstelling waarnaar ik verwijs in onze IEPTO2-klasse voor prestatieafstemming als ik praat over overwegingen met meerdere instanties en hoe de .NET Garbage Collector (GC) die door één instantie wordt geactiveerd, van invloed kan zijn op de andere instanties op dezelfde server.
De GC in .NET is bedoeld om het geheugengebruik van applicaties die CLR gebruiken te verminderen door toe te staan dat het geheugen dat aan objecten is toegewezen automatisch wordt opgeschoond, waardoor ontwikkelaars niet langer handmatig geheugentoewijzing en -deallocatie moeten afhandelen in de mate die vereist is door onbeheerde code . De GC-functionaliteit is gedocumenteerd in Books Online als u meer wilt weten over hoe het werkt, maar de bijzonderheden buiten het feit dat collecties kunnen worden geblokkeerd, zijn niet belangrijk voor het oplossen van problemen met actieve wachttijden op CLR_MANUAL_EVENT in SQL Server verder.
De kern van het probleem aanpakken
Met de wetenschap dat het verzamelen van afval door .NET de oorzaak was van het probleem, besloot ik wat te experimenteren met een enkele ruimtelijke query tegen AdventureWorks2016 en een heel eenvoudig PowerShell-script om de garbage collector handmatig in een lus aan te roepen om bij te houden wat er gebeurt in sys.dm_os_waiting_tasks binnenkant van SQL Server voor de query:
USE AdventureWorks2016; GO SELECT a.SpatialLocation.ToString(), a.City, b.SpatialLocation.ToString(), b.City FROM Person.Address AS a INNER JOIN Person.Address AS b ON a.SpatialLocation.STDistance(b.SpatialLocation) <= 100 ORDER BY a.SpatialLocation.STDistance(b.SpatialLocation);
Deze zoekopdracht vergelijkt alle adressen in het Person.Address tabel tegen elkaar om elk adres te vinden dat zich binnen 100 meter van een ander adres in de tabel bevindt. Dit creëert een langlopende parallelle taak binnen SQL Server die ook een groot Cartesiaans resultaat oplevert. Als u besluit dit gedrag zelf te reproduceren, verwacht dan niet dat dit de resultaten voltooit of retourneert. Terwijl de query wordt uitgevoerd, begint de bovenliggende thread voor de taak te wachten op CXPACKET wacht en de query wordt nog enkele minuten verwerkt. Waar ik echter in geïnteresseerd was, was wat er gebeurt als garbagecollection plaatsvindt in de CLR-runtime of als de GC wordt aangeroepen, dus ik gebruikte een eenvoudig PowerShell-script dat de GC zou herhalen en handmatig zou forceren om uit te voeren.
OPMERKING:DIT IS OM VEEL REDENEN GEEN AANBEVOLEN PRAKTIJK IN PRODUCTIECODE!
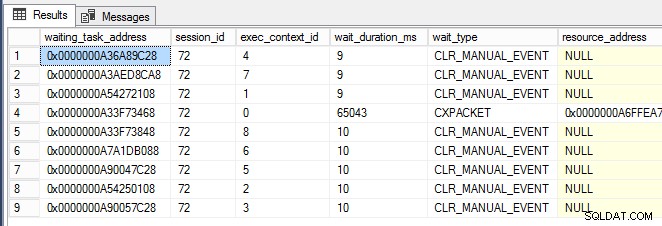
while (1 -eq 1) {[System.GC]::Collect() } Toen het PowerShell-venster eenmaal actief was, begon ik bijna onmiddellijk CLR_MANUAL_EVENT te zien wacht op de parallelle subtaakthreads (hieronder weergegeven, waarbij exec_context_id groter is dan nul) in sys.dm_os_waiting_tasks :
Nu ik dit gedrag kon activeren en het duidelijk begon te worden dat SQL Server hier niet noodzakelijk het probleem is en mogelijk het slachtoffer is van andere activiteiten, wilde ik weten hoe ik dieper kon graven en de oorzaak van het probleem kon achterhalen . Dit is waar PerfMon van pas kwam voor het volgen van de .NET CLR Memory-tellergroep voor alle taken op de server.
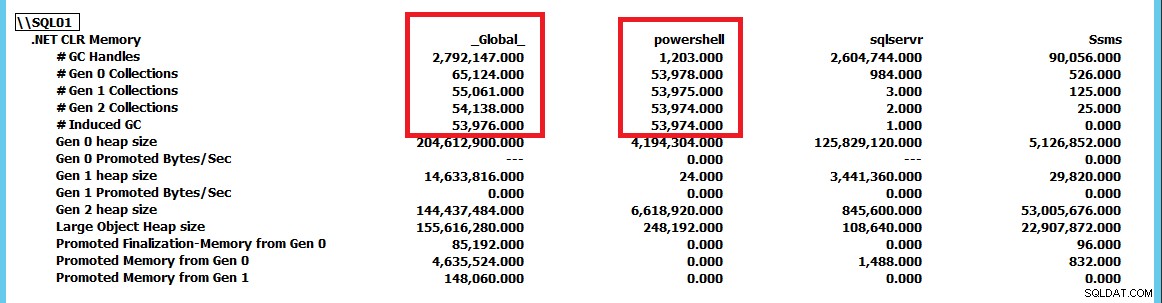
Deze schermafbeelding is verkleind om de collecties voor sqlservr weer te geven en powershell als applicaties vergeleken met de _Global_ verzamelingen door de .NET-runtime. Door GC.Collect() . te forceren constant draaien, kunnen we zien dat de powershell instantie stuurt de GC-verzamelingen op de server aan. Met behulp van deze PerfMon-tellergroep kunnen we volgen welke applicaties de meeste verzamelingen uitvoeren en van daaruit verder onderzoek naar het probleem voortzetten. In dit geval elimineert het simpelweg stoppen van het PowerShell-script de CLR_MANUAL_EVENT wacht in SQL Server en de query gaat door met verwerken totdat we deze stoppen of toestaan dat de miljard rijen met resultaten worden geretourneerd die erdoor zouden worden uitgevoerd.
Conclusie
Als u actief wacht op CLR_MANUAL_EVENT waardoor de applicatie vertragingen veroorzaakt, ga er niet automatisch vanuit dat het probleem zich in SQL Server voordoet. SQL Server gebruikt de garbagecollection op serverniveau (tenminste vóór SQL Server 2017 CU4, waar kleine servers met minder dan 2 GB RAM de garbagecollection op clientniveau kunnen gebruiken om het gebruik van bronnen te verminderen). Als u dit probleem ziet optreden in SQL Server, gebruikt u de .NET CLR-geheugentellergroep in PerfMon en controleert u of een andere toepassing de garbagecollection in CLR aanstuurt en als resultaat de CLR-taken intern in SQL Server blokkeert.