Inleiding
- Er zijn enkele specifieke regels die moeten worden gevolgd bij het maken van de database-objecten. Om de prestaties van een database te verbeteren, moeten een primaire sleutel, geclusterde en niet-geclusterde indexen en beperkingen worden toegewezen aan een tabel. Hoewel we al deze regels volgen, kunnen dubbele rijen nog steeds voorkomen in een tabel.
- Het is altijd een goede gewoonte om de databasesleutels te gebruiken. Het gebruik van de databasesleutels verkleint de kans op dubbele records in een tabel. Maar als er al dubbele records in een tabel aanwezig zijn, zijn er specifieke manieren om deze dubbele records te verwijderen.
Manieren om dubbele rijen te verwijderen
- Gebruik van DELETE JOIN instructie om dubbele rijen te verwijderen
DELETE JOIN-instructie wordt geleverd in MySQL die helpt bij het verwijderen van dubbele rijen uit een tabel.
Overweeg een database met de naam "studentdb". We zullen er een tabelstudent in maken.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
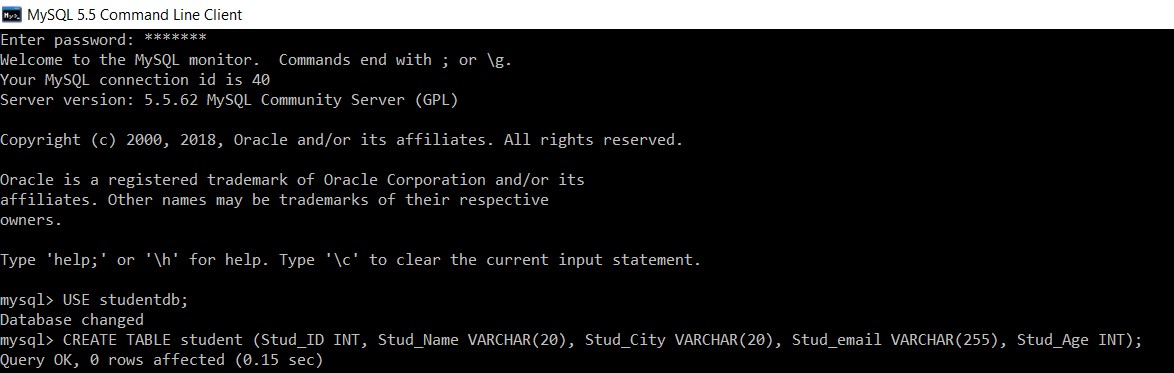
We hebben met succes een 'student'-tabel gemaakt in de 'studentdb'-database.
Nu gaan we de volgende query's schrijven om gegevens in de studententabel in te voegen.
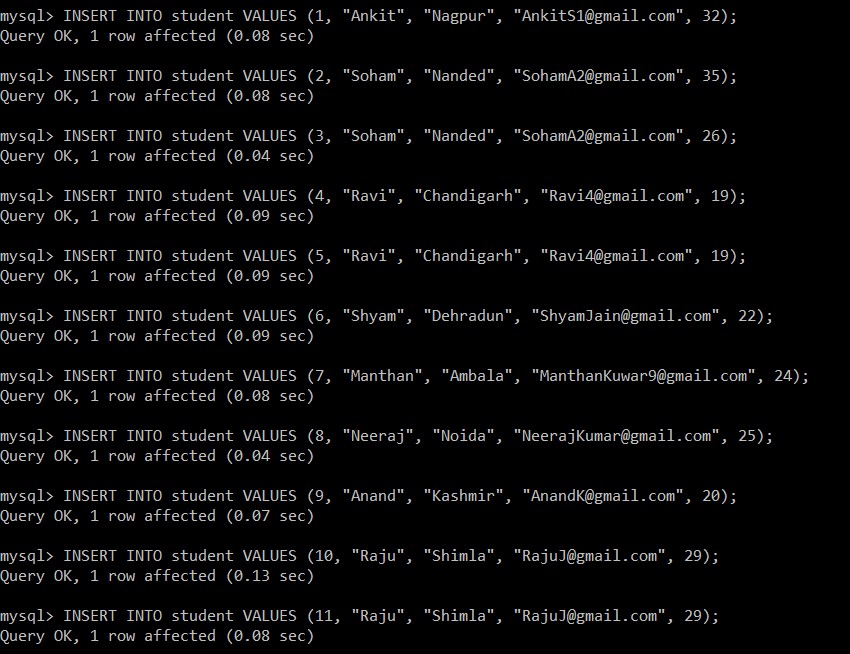
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
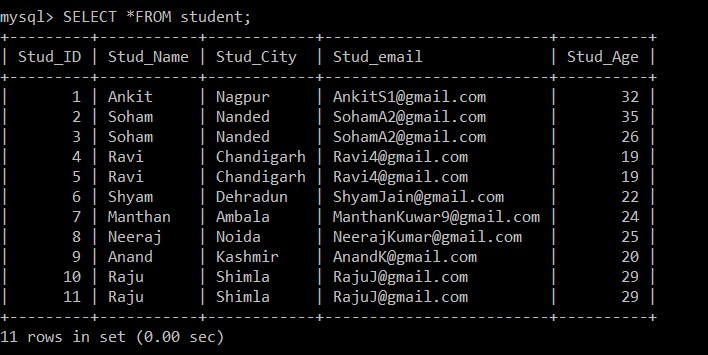
Nu halen we alle records uit de studententabel. We zullen deze tabel en database in overweging nemen voor alle volgende voorbeelden.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Voorbeeld 1:
Schrijf een query om dubbele rijen uit de studententabel te verwijderen met de DELETE JOIN verklaring.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;We hebben de DELETE-query gebruikt met INNER JOIN. Om de INNER JOIN op een enkele tabel te implementeren, hebben we twee instanties s1 en s2 gemaakt. Vervolgens hebben we met behulp van de WHERE-clausule twee voorwaarden gecontroleerd om de dubbele rijen in de studententabel te achterhalen. Als de e-mail-ID in twee verschillende records hetzelfde is en de student-ID verschilt, wordt deze behandeld als een duplicaatrecord volgens de WHERE-clausulevoorwaarde.
Uitvoer:
Query OK, 3 rows affected (0.20 sec)De resultaten van de bovenstaande zoekopdracht laten zien dat er drie dubbele records aanwezig zijn in de studententabel.

We zullen de SELECT-query gebruiken om de dubbele records te vinden die zijn verwijderd.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
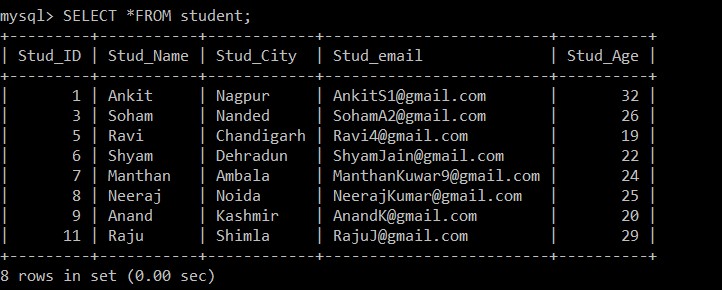
Nu zijn er slechts 8 records aanwezig in de studententabel, aangezien de drie dubbele records worden verwijderd uit de momenteel geselecteerde tabel. Volgens de volgende voorwaarde:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Als de e-mail-ID's van twee records hetzelfde zijn, wordt, aangezien het kleiner dan-teken wordt gebruikt tussen de student-ID, alleen de record met grotere werknemer-ID's bewaard en wordt het andere dubbele record tussen de twee records verwijderd.
Voorbeeld 2:
Schrijf een query om dubbele rijen uit de studententabel te verwijderen met behulp van de delete join-instructie, terwijl u de dubbele record met een lager werknemers-ID behoudt en de andere verwijdert.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;We hebben de DELETE-query gebruikt met INNER JOIN. Om de INNER JOIN op een enkele tabel te implementeren, hebben we twee instanties s1 en s2 gemaakt. Vervolgens hebben we met behulp van de WHERE-component twee voorwaarden gecontroleerd om de dubbele rijen in de studententabel te achterhalen. Als de e-mail-ID die in twee verschillende records aanwezig is hetzelfde is en de student-ID anders is, wordt deze behandeld als een duplicaatrecord volgens de WHERE-clausulevoorwaarde.
Uitvoer:
Query OK, 3 rows affected (0.09 sec)De resultaten van de bovenstaande zoekopdracht laten zien dat er drie dubbele records aanwezig zijn in de studententabel.

We zullen de SELECT-query gebruiken om de dubbele records te vinden die zijn verwijderd.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
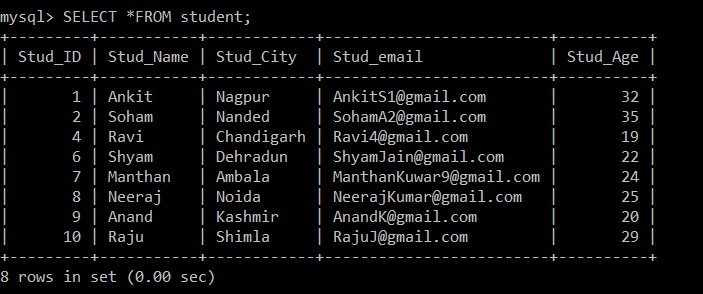
Nu zijn er slechts 8 records aanwezig in de studententabel, aangezien de drie dubbele records worden verwijderd uit de momenteel geselecteerde tabel. Volgens de volgende voorwaarde:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Als de e-mail-ID's van twee records hetzelfde zijn, aangezien het groter-dan-teken wordt gebruikt tussen de student-ID, wordt alleen het record met het lagere werknemers-ID bewaard en wordt het andere dubbele record tussen de twee records verwijderd.
- Gebruik van een tussentabel om dubbele rijen te verwijderen
De volgende stappen moeten worden gevolgd bij het verwijderen van de dubbele rijen met behulp van een tussentabel.
- Er moet een nieuwe tabel worden gemaakt, die hetzelfde zal zijn als de eigenlijke tabel.
- Voeg afzonderlijke rijen van de werkelijke tabel toe aan de nieuw gemaakte tabel.
- Laat de werkelijke tafel vallen en hernoem de nieuwe tafel met dezelfde naam als een werkelijke tafel.
Voorbeeld:
Schrijf een query om de dubbele records uit de studententabel te verwijderen met behulp van een tussentabel.
Stap 1:
Eerst zullen we een tussentabel maken die hetzelfde zal zijn als de werknemerstabel.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Hier is 'employee' de originele tabel en 'temp_student' is de tussentabel.
Stap 2:
Nu halen we alleen de unieke records uit de studententabel en voegen we alle opgehaalde records in de temp_studenttabel in.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Hier, voordat de afzonderlijke records uit de studententabel in temp_student worden ingevoegd, worden alle dubbele records gefilterd door Stud_email. Dan zijn alleen de records met een unieke e-mail-ID ingevoegd in temp_student.
Stap 3:
Daarna zullen we de studententafel verwijderen en de tabel temp_student hernoemen naar de studententafel.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
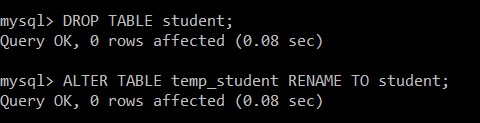
De studententabel is succesvol verwijderd en temp_student wordt hernoemd naar de studententabel, die alleen de unieke records bevat.
Vervolgens moeten we controleren of de studententabel nu alleen de unieke records bevat. Om dit te verifiëren, hebben we de SELECT-query gebruikt om de gegevens in de studententabel te zien.
mysql> SELECT *FROM student;Uitvoer:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
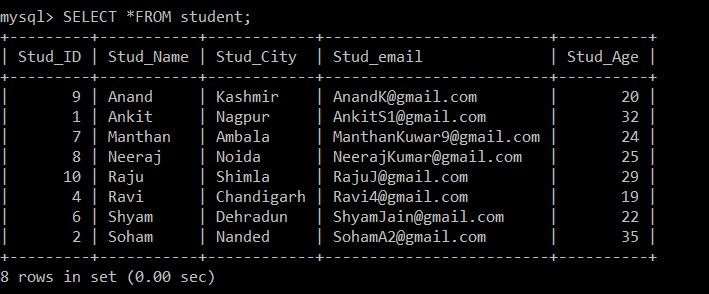
Nu zijn er slechts 8 records aanwezig in de studententabel, aangezien de drie dubbele records worden verwijderd uit de momenteel geselecteerde tabel. In stap 2 werd tijdens het ophalen van de afzonderlijke records uit de originele tabel en het invoegen ervan in een tussenliggende tabel een GROUP BY-clausule gebruikt op Stud_email, zodat alle records werden ingevoegd op basis van de e-mail-ID's van studenten. Hier wordt standaard alleen het record met een lager werknemers-ID bij de dubbele records gehouden en wordt het andere verwijderd.