Bent u ooit een situatie tegengekomen waarin u de toestand van een entiteit moet beheren die in de loop van de tijd verandert? Er zijn veel voorbeelden die er zijn. Laten we beginnen met een makkelijke:het samenvoegen van klantrecords.
Stel dat we lijsten met klanten uit twee verschillende bronnen samenvoegen. We kunnen een van de volgende toestanden hebben:Duplicaten geïdentificeerd – het systeem heeft twee mogelijk dubbele entiteiten gevonden; Bevestigde duplicaten – een gebruiker valideert dat de twee entiteiten inderdaad duplicaten zijn; of Uniek bevestigd – de gebruiker beslist dat de twee entiteiten uniek zijn. In elk van deze situaties hoeft de gebruiker alleen een ja-nee-beslissing te nemen.
Maar hoe zit het met complexere situaties? Is er een manier om de daadwerkelijke workflow tussen staten te definiëren? Lees verder…
Hoe dingen gemakkelijk fout kunnen gaan
Veel organisaties moeten sollicitaties beheren. In een eenvoudig model zou u een tabel kunnen hebben met de naam JOB_APPLICATION , en u kunt de status van de toepassing volgen met behulp van een tabel met referentiegegevens die waarden als deze bevat:
| Applicatiestatus |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Deze waarden kunnen op elk moment in willekeurige volgorde worden geselecteerd. Het vertrouwt erop dat eindgebruikers ervoor zorgen dat in elke fase een logische en juiste selectie wordt gemaakt. Niets verbiedt een onlogische volgorde van toestanden.
Laten we bijvoorbeeld zeggen dat een aanvraag is afgewezen. De huidige status is uiteraard APPLICATION_REJECTED . Er is niets dat op applicatieniveau kan worden gedaan om te voorkomen dat een onervaren gebruiker vervolgens INVITED_TO_INTERVIEW selecteert of een andere onlogische toestand.
Wat nodig is, is iets om de gebruiker te begeleiden bij het selecteren van de volgende logische status, iets dat een logische workflow definieert .
En wat als je verschillende eisen stelt aan verschillende soorten sollicitaties? Voor sommige banen kan het bijvoorbeeld nodig zijn dat de sollicitant een proeve van bekwaamheid aflegt. Natuurlijk kun je meer waarden aan de lijst toevoegen om deze te dekken, maar er is niets in het huidige ontwerp dat de eindgebruiker ervan weerhoudt een verkeerde selectie te maken voor het type toepassing in kwestie. De realiteit is dat er verschillende workflows . zijn voor verschillende contexten .
Nog een punt om over na te denken:zijn de vermelde opties echt allemaal staten ? Of zijn sommige in feite resultaten ? Het aanbod van een baan kan bijvoorbeeld worden geaccepteerd of afgewezen door de sollicitant. Daarom JOB_OFFER_MADE heeft echt twee uitkomsten:JOB_OFFER_ACCEPTED en JOB_OFFER_DECLINED .
Een andere uitkomst kan zijn dat een jobaanbieding wordt ingetrokken. Misschien wilt u de reden waarom het is ingetrokken, vastleggen met behulp van een kwalificatie. Als u deze redenen gewoon aan de bovenstaande lijst toevoegt, leidt niets de eindgebruiker tot het maken van logische selecties.
Dus hoe complexer de toestanden, uitkomsten en kwalificaties worden, hoe meer je de workflow moet definiëren. van een proces .
Organiseren van processen, toestanden en resultaten
Het is belangrijk om te begrijpen wat er met uw gegevens gebeurt voordat u deze probeert te modelleren. In eerste instantie ben je misschien geneigd te denken dat er hier een strikte hiërarchie van typen is:
Als we het bovenstaande voorbeeld nader bekijken, zien we dat de INVITED_TO_INTERVIEW en de JOB_OFFER_MADE staten delen dezelfde mogelijke uitkomsten, namelijk ACCEPTED en DECLINED . Dit vertelt ons dat er een veel-op-veel-relatie is tussen staten en resultaten. Dit geldt vaak voor andere staten, resultaten en kwalificaties.
Op conceptueel niveau is dit dus wat er feitelijk aan de hand is met onze metadata:
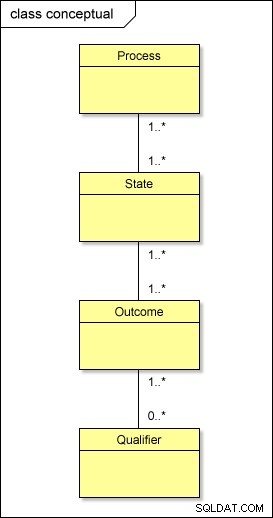
Als je dit model zou transformeren naar de fysieke wereld met behulp van de standaardbenadering, zou je tabellen hebben met de naam PROCESS , STATE , OUTCOME , en QUALIFIER; je zou ook tussentabellen moeten hebben tussen hen – PROCESS_STATE , STATE_OUTCOME , en OUTCOME_QUALIFIER – om de veel-op-veel-relaties op te lossen . Dit bemoeilijkt het ontwerp.
Hoewel de logische hiërarchie van niveaus (proces → status → uitkomst → kwalificatie) moet worden gehandhaafd, is er een eenvoudigere manier om onze metadata fysiek te organiseren.
Het werkstroompatroon
Het onderstaande diagram definieert de belangrijkste componenten van een workflowdatabasemodel:
De gele tabellen aan de linkerkant bevatten workflow-metadata en de blauwe tabellen aan de rechterkant bevatten bedrijfsgegevens.
Het eerste om op te merken is dat elke entiteit kan worden beheerd zonder dat er grote veranderingen aan dit model nodig zijn. De YOUR_ENTITIY_TO_MANAGE tabel is degene onder workflowbeheer. In termen van ons voorbeeld zou dit de JOB_APPLICATION tafel.
Vervolgens hoeven we alleen de wf_state_type_process_id . toe te voegen kolom naar de tabel die we willen beheren. Deze kolom verwijst naar het daadwerkelijke workflow proces gebruikt om de entiteit te beheren. Dit is niet strikt een externe-sleutelkolom, maar het stelt ons in staat om snel WORKFLOW_STATE_TYPE te doorzoeken voor het juiste proces. De tabel die de staatsgeschiedenis . zal bevatten is MANAGED_ENTITY_STATE . Nogmaals, u zou hier uw eigen specifieke tabelnaam kiezen en deze naar uw eigen wensen aanpassen.
De metagegevens
De verschillende workflowniveaus zijn gedefinieerd in WORKFLOW_LEVEL_TYPE . Deze tabel bevat het volgende:
| Sleutel typen | Beschrijving |
|---|---|
| PROCES | Workflowproces op hoog niveau. |
| STAAT | Een status in het proces. |
| RESULTAAT | Hoe een staat eindigt, de uitkomst. |
| KWALIFICATIE | Een optionele, meer gedetailleerde kwalificatie voor een uitkomst. |
WORKFLOW_STATE_TYPE en WORKFLOW_STATE_HIERARCHY vorm een klassieke Bill of Materials (BOM)-structuur . Deze structuur, die zeer beschrijvend is voor een daadwerkelijke fabricagelijst, is vrij gebruikelijk in datamodellering. Het kan hiërarchieën definiëren of op veel recursieve situaties worden toegepast. We gaan het hier gebruiken om onze logische hiërarchie van processen, toestanden, resultaten en optionele kwalificaties te definiëren.
Voordat we een hiërarchie kunnen definiëren, moeten we de afzonderlijke componenten definiëren. Dit zijn onze basisbouwstenen. Ik ga hier gewoon naar verwijzen door TYPE_KEY (wat uniek is) omwille van de beknoptheid. Voor ons voorbeeld hebben we:
| Type werkstroomniveau | Werkstroomstatus Type.Type-sleutel |
|---|---|
| RESULTAAT | GESLAAGD |
| RESULTAAT | MISLUKT |
| RESULTAAT | GEACCEPTEERD |
| RESULTAAT | GEWEIGERD |
| RESULTAAT | CANDIDATE_CANCELLED |
| RESULTAAT | EMPLOYER_CANCELLED |
| RESULTAAT | AFGEWEZEN |
| RESULTAAT | EMPLOYER_WITHDRAWN |
| RESULTAAT | NO_SHOW |
| RESULTAAT | GEHUURD |
| RESULTAAT | NOT_HIRED |
| STAAT | APPLICATION_RECEIVED |
| STAAT | APPLICATION_REVIEW |
| STAAT | INVITED_TO_INTERVIEW |
| STAAT | INTERVIEW |
| STAAT | TEST_APTITUDE |
| STAAT | SEEK_REFERENCES |
| STAAT | MAKE_OFFER |
| STAAT | APPLICATION_CLOSED |
| PROCES | STANDARD_JOB_APPLICATION |
| PROCES | TECHNICAL_JOB_APPLICATION |
Nu kunnen we beginnen met het definiëren van onze hiërarchie. Dit is waar we onze bouwstenen nemen en onze structuur definiëren. Voor elke staat definiëren we de mogelijke uitkomsten. In feite is het een regel van dit workflowsysteem dat elke status moet eindigen met een uitkomst:
| Oudertype – STATEN | Kindtype – UITKOMSTEN |
|---|---|
| APPLICATION_RECEIVED | GEACCEPTEERD |
| APPLICATION_RECEIVED | AFGEWEZEN |
| APPLICATION_REVIEW | GESLAAGD |
| APPLICATION_REVIEW | MISLUKT |
| INVITED_TO_INTERVIEW | GEACCEPTEERD |
| INVITED_TO_INTERVIEW | GEWEIGERD |
| INTERVIEW | GESLAAGD |
| INTERVIEW | MISLUKT |
| INTERVIEW | CANDIDATE_CANCELLED |
| INTERVIEW | NO_SHOW |
| MAKE_OFFER | GEACCEPTEERD |
| MAKE_OFFER | GEWEIGERD |
| SEEK_REFERENCES | GESLAAGD |
| SEEK_REFERENCES | MISLUKT |
| APPLICATION_CLOSED | GEHUURD |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | GESLAAGD |
| TEST_APTITUDE | MISLUKT |
Onze processen zijn gewoon een reeks toestanden die elk voor een bepaalde tijd bestaan. In de onderstaande tabel worden ze in een logische volgorde gepresenteerd, maar dit definieert niet de daadwerkelijke volgorde van verwerking.
| Oudertype – PROCESSEN | Kindtype – STATEN |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | INTERVIEW |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | INTERVIEW |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Er is een belangrijk punt te maken met betrekking tot een stuklijsthiërarchie. Net zoals een fysieke stuklijst assemblages en sub-assemblages definieert tot in de kleinste componenten, hebben we een vergelijkbare rangschikking in onze hiërarchie. Dit betekent dat we 'assemblies' en 'sub-assemblies' kunnen hergebruiken.
Bij wijze van voorbeeld:zowel de STANDARD_JOB_APPLICATION en TECHNICAL_JOB_APPLICATION processen heb het INTERVIEW staat . Op zijn beurt, de INTERVIEW staat heeft de PASSED , FAILED , CANDIDATE_CANCELLED , en NO_SHOW resultaten daarvoor gedefinieerd.
Wanneer u een toestand in een proces gebruikt, krijgt u automatisch de onderliggende uitkomsten ervan omdat het al een assemblage is. Dit betekent dat er voor beide soorten sollicitaties dezelfde uitkomsten bestaan bij het INTERVIEW fase. Als u verschillende interviewresultaten wilt voor verschillende soorten sollicitaties, moet u bijvoorbeeld TECHNICAL_INTERVIEW definiëren en STANDARD_INTERVIEW stelt dat elk hun eigen specifieke resultaten heeft.
In dit voorbeeld is het enige verschil tussen de twee soorten sollicitaties dat een technische sollicitatie een proeve van bekwaamheid bevat.
Voordat je gaat
In deel 1 van dit tweedelige artikel is het workflowdatabasepatroon geïntroduceerd. Het heeft laten zien hoe u het kunt opnemen om de levenscyclus van elke entiteit in uw database te beheren.
Deel 2 laat je zien hoe je de daadwerkelijke workflow definieert met behulp van aanvullende configuratietabellen. Hier krijgt de gebruiker de toegestane vervolgstappen te zien. We zullen ook een techniek demonstreren om het strikte hergebruik van 'assemblages' en 'sub-assemblages' in stuklijsten te omzeilen.