Databases zijn op verschillende manieren ontworpen. Meestal kunnen we "schoolvoorbeelden" gebruiken:normaliseer de database en alles werkt prima. Maar er zijn situaties die een andere aanpak vereisen. We kunnen referenties verwijderen om meer flexibiliteit te krijgen. Maar wat als we de prestaties moeten verbeteren terwijl alles volgens het boekje is gedaan? In dat geval is denormalisatie een techniek die we zouden moeten overwegen. In dit artikel bespreken we de voor- en nadelen van denormalisatie en welke situaties dit rechtvaardigen.
Wat is denormalisatie?
Denormalisatie is een strategie die wordt gebruikt op een eerder genormaliseerde database om de prestaties te verbeteren. Het idee erachter is om overtollige gegevens toe te voegen waar we denken dat dit ons het meest zal helpen. We kunnen extra attributen in een bestaande tabel gebruiken, nieuwe tabellen toevoegen of zelfs instanties van bestaande tabellen maken. Het gebruikelijke doel is om de uitvoeringstijd van geselecteerde query's te verkorten door gegevens toegankelijker te maken voor de query's of door samengevatte rapporten in afzonderlijke tabellen te genereren. Dit proces kan enkele nieuwe problemen met zich meebrengen, en we zullen ze later bespreken.
Een genormaliseerde database is het startpunt voor het denormalisatieproces. Het is belangrijk om onderscheid te maken tussen de database die niet is genormaliseerd en de database die eerst is genormaliseerd en later is gedenormaliseerd. De tweede is oké; de eerste is vaak het gevolg van een slecht databaseontwerp of een gebrek aan kennis.
Voorbeeld:een genormaliseerd model voor een zeer eenvoudige CRM
Het onderstaande model zal als voorbeeld dienen:
Laten we snel de tabellen bekijken:
- Het
user_accounttabel slaat gegevens op over gebruikers die inloggen op onze applicatie (vereenvoudiging van het model, rollen en gebruikersrechten zijn hiervan uitgesloten). - De
clienttabel bevat enkele basisgegevens over onze klanten. - Het
producttabel geeft een overzicht van producten die aan onze klanten worden aangeboden. - De
tasktabel bevat alle taken die we hebben gemaakt. U kunt elke taak zien als een reeks gerelateerde acties naar klanten toe. Elke taak heeft zijn gerelateerde gesprekken, vergaderingen en lijsten met aangeboden en verkochte producten. - De
callenmeetingtabellen slaan gegevens op over alle gesprekken en vergaderingen en relateren deze aan taken en gebruikers. - De woordenboeken
task_outcome,meeting_outcomeencall_outcomebevatten alle mogelijke opties voor de uiteindelijke status van een taak, vergadering of oproep. - De
product_offeredslaat een lijst op van alle producten die aan klanten werden aangeboden voor bepaalde taken terwijlproduct_soldbevat een lijst van alle producten die de klant daadwerkelijk heeft gekocht. - De
supply_ordertabel slaat gegevens op over alle bestellingen die we hebben geplaatst en deproducts_on_ordertabel geeft producten en hun hoeveelheid weer voor specifieke bestellingen. - De
writeofftabel is een lijst met producten die zijn afgeschreven als gevolg van ongelukken of iets dergelijks (bijv. kapotte spiegels).
De database is vereenvoudigd, maar het is perfect genormaliseerd. U zult geen ontslagen vinden en het moet zijn werk doen. We zouden in ieder geval geen prestatieproblemen mogen ervaren, zolang we maar met een relatief kleine hoeveelheid data werken.
Wanneer en waarom denormalisatie gebruiken
Zoals met bijna alles, moet u zeker weten waarom u denormalisatie wilt toepassen. U moet er ook zeker van zijn dat de winst van het gebruik ervan opweegt tegen eventuele schade. Er zijn een paar situaties waarin u zeker aan denormalisatie moet denken:
- Geschiedenis bijhouden: Gegevens kunnen in de loop van de tijd veranderen en we moeten waarden opslaan die geldig waren toen een record werd gemaakt. Wat voor veranderingen bedoelen we? Welnu, de voor- en achternaam van een persoon kunnen veranderen; een klant kan ook zijn bedrijfsnaam of andere gegevens wijzigen. Taakdetails moeten waarden bevatten die actueel waren op het moment dat een taak werd gegenereerd. We zouden de gegevens uit het verleden niet correct kunnen recreëren als dit niet zou gebeuren. We zouden dit probleem kunnen oplossen door een tabel toe te voegen met de geschiedenis van deze wijzigingen. In dat geval zou een selectiequery die de taak retourneert en een geldige clientnaam ingewikkelder worden. Misschien is een extra tafel niet de beste oplossing.
- Verbeteren van zoekopdrachtprestaties: Sommige query's kunnen meerdere tabellen gebruiken om toegang te krijgen tot gegevens die we vaak nodig hebben. Denk aan een situatie waarin we aan 10 tafels moeten deelnemen om de naam van de klant en de producten die aan hem zijn verkocht, terug te geven. Sommige tabellen langs het pad kunnen ook grote hoeveelheden gegevens bevatten. In dat geval is het misschien verstandig om een
client_id. toe te voegen rechtstreeks toeschrijven aan deproducts_soldtafel. - Versnellen van rapportage: We hebben bepaalde statistieken heel vaak nodig. Het maken ervan op basis van live gegevens is behoorlijk tijdrovend en kan de algehele systeemprestaties beïnvloeden. Laten we zeggen dat we de verkoop van klanten over bepaalde jaren voor sommige of alle klanten willen volgen. Het genereren van dergelijke rapporten uit live gegevens zou bijna door de hele database "graven" en het veel vertragen. En wat gebeurt er als we die statistiek vaak gebruiken?
- Veelgebruikte waarden vooraf berekenen: We willen dat sommige waarden al zijn berekend, zodat we ze niet in realtime hoeven te genereren.
Het is belangrijk om erop te wijzen dat u denormalisatie niet hoeft te gebruiken als er geen prestatieproblemen zijn in de applicatie. Maar als je merkt dat het systeem langzamer gaat werken - of als je weet dat dit kan gebeuren - moet je nadenken over het toepassen van deze techniek. Overweeg voordat u ermee aan de slag gaat echter andere opties, zoals query-optimalisatie en juiste indexering. Je kunt denormalisatie ook gebruiken als je al in productie bent, maar het is beter om problemen in de ontwikkelingsfase op te lossen.
Wat zijn de nadelen van denormalisatie?
Het grootste voordeel van het denormalisatieproces is uiteraard de verbeterde prestatie. Maar we moeten er wel een prijs voor betalen, en die prijs kan bestaan uit:
- Schijfruimte: Dit wordt verwacht, omdat we dubbele gegevens hebben.
- Gegevensafwijkingen: We moeten ons er terdege van bewust zijn dat gegevens nu op meer dan één plek kunnen worden gewijzigd. We moeten elk stukje dubbele gegevens dienovereenkomstig aanpassen. Dat geldt ook voor berekende waarden en rapporten. We kunnen dit bereiken door triggers, transacties en/of procedures te gebruiken voor alle operaties die samen moeten worden voltooid.
- Documentatie: We moeten elke denormalisatieregel die we hebben toegepast goed documenteren. Als we het databaseontwerp later wijzigen, moeten we al onze uitzonderingen bekijken en opnieuw in overweging nemen. Misschien hebben we ze niet meer nodig omdat we het probleem hebben opgelost. Of misschien moeten we iets toevoegen aan bestaande denormalisatieregels. (Bijvoorbeeld:we hebben een nieuw attribuut toegevoegd aan de clienttabel en we willen de geschiedeniswaarde opslaan samen met alles wat we al opslaan. We zullen bestaande denormalisatieregels moeten wijzigen om dat te bereiken).
- Andere bewerkingen vertragen: We kunnen verwachten dat we het invoegen, wijzigen en verwijderen van gegevens zullen vertragen. Als deze operaties relatief zelden plaatsvinden, kan dit een voordeel zijn. In principe zouden we één langzame selectie verdelen in een groter aantal langzamere invoeg-/bijwerk-/verwijder-query's. Hoewel een zeer complexe selectiequery technisch gezien het hele systeem merkbaar zou kunnen vertragen, zou het vertragen van meerdere "kleinere" bewerkingen de bruikbaarheid van onze applicatie niet mogen schaden.
- Meer codering: Regel 2 en 3 vereisen extra codering, maar tegelijkertijd zullen ze sommige geselecteerde zoekopdrachten veel vereenvoudigen. Als we een bestaande database denormaliseren, moeten we deze geselecteerde query's aanpassen om de voordelen van ons werk te krijgen. We moeten ook waarden bijwerken in nieuw toegevoegde kenmerken voor bestaande records. Ook dit vereist wat meer codering.
Het voorbeeldmodel, gedenormaliseerd
In het onderstaande model heb ik enkele van de bovengenoemde denormalisatieregels toegepast. De roze tafels zijn aangepast, terwijl de lichtblauwe tafel helemaal nieuw is.
Welke wijzigingen worden toegepast en waarom?

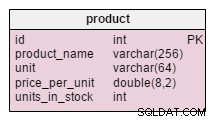
De enige verandering in het product tabel is de toevoeging van de units_in_stock attribuut. In een genormaliseerd model zouden we deze gegevens kunnen berekenen als bestelde eenheden – verkochte eenheden – (aangeboden eenheden) – afgeschreven eenheden . We zouden de berekening herhalen elke keer dat een klant om dat product vraagt, wat extreem tijdrovend zou zijn. In plaats daarvan berekenen we de waarde vooraf; als een klant het ons vraagt, hebben we het klaar. Dit vereenvoudigt natuurlijk de selectiequery aanzienlijk. Aan de andere kant, de units_in_stock kenmerk moet worden aangepast na elke invoeging, update of verwijdering in de products_on_order , writeoff , product_offered en product_sold tabellen.
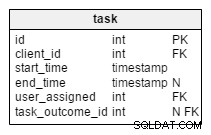
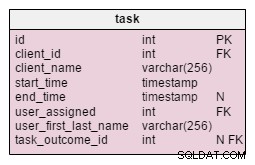
In de gewijzigde task tabel, vinden we twee nieuwe attributen:client_name en user_first_last_name . Beiden slaan waarden op toen de taak werd gemaakt. De reden is dat beide waarden in de loop van de tijd kunnen veranderen. We bewaren ook een externe sleutel die ze relateert aan de oorspronkelijke klant- en gebruikers-ID. Er zijn meer waarden die we willen opslaan, zoals klantadres, btw-nummer, enz.




De gedenormaliseerde product_offered tabel heeft twee nieuwe attributen, price_per_unit en price . De price_per_unit kenmerk wordt opgeslagen omdat we de werkelijke prijs moeten opslaan toen het product werd aangeboden . Het genormaliseerde model zou alleen de huidige staat tonen, dus als de productprijs verandert, zouden onze 'geschiedenis'-prijzen ook veranderen. Onze verandering zorgt er niet alleen voor dat de database sneller werkt:hij werkt ook beter. De price attribuut is de berekende waarde units_sold * price_per_unit . Ik heb het hier toegevoegd om te voorkomen dat we elke keer dat we een lijst met aangeboden producten willen bekijken, die berekening moeten maken. Het is een kleine kost, maar het verbetert de prestaties.
De wijzigingen die zijn aangebracht op de product_sold tafel lijken erg op elkaar. De tabelstructuur is hetzelfde, maar er wordt een lijst met verkochte artikelen opgeslagen.
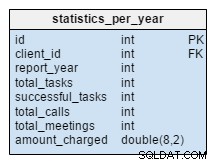
De statistics_per_year tafel is geheel nieuw in ons model. We moeten het zien als een gedenormaliseerde tabel omdat alle gegevens kunnen worden berekend uit de andere tabellen. Het idee achter deze tabel is om het aantal taken, succesvolle taken, vergaderingen en telefoontjes met betrekking tot een bepaalde klant op te slaan. Het behandelt ook het totaalbedrag dat per jaar in rekening wordt gebracht. Na het invoegen, bijwerken of verwijderen van iets in de task , meeting , call en product_sold tabellen, moeten we de gegevens van deze tabel voor die klant en het overeenkomstige jaar opnieuw berekenen. We kunnen verwachten dat we de meeste wijzigingen alleen voor het lopende jaar zullen hebben. Rapporten van voorgaande jaren zouden niet moeten veranderen.
Waarden in deze tabel worden vooraf berekend, dus we zullen minder tijd en middelen besteden op het moment dat we het resultaat van de berekening nodig hebben. Denk na over de waarden die u vaak nodig zult hebben. Misschien heb je ze niet altijd allemaal nodig en loop je het risico sommige ervan live te berekenen.
Denormalisatie is een zeer interessant en krachtig concept. Hoewel dit niet het eerste is dat u in gedachten moet hebben om de prestaties te verbeteren, kan het in sommige situaties de beste of zelfs de enige oplossing zijn.
Voordat u ervoor kiest om denormalisatie te gebruiken, moet u ervoor zorgen dat u dit wilt. Doe wat analyse en volg de prestaties. U zult waarschijnlijk besluiten om met denormalisatie te gaan nadat u al live bent gegaan. Wees niet bang om het te gebruiken, maar houd wijzigingen bij en u zou geen problemen moeten ondervinden (d.w.z. de gevreesde gegevensafwijkingen).