Een ondersteunende index kan mogelijk helpen om de noodzaak van expliciete sortering in het queryplan te voorkomen bij het optimaliseren van T-SQL-query's met vensterfuncties. Door een ondersteunende index, Ik bedoel een met de elementen voor het partitioneren en ordenen van vensters als de indexsleutel, en de rest van de kolommen die in de query verschijnen als de index-inclusief kolommen. Ik verwijs vaak naar zo'n indexeringspatroon als een POC index als een acroniem voor partitioneren , bestellen, en bedekkend . Als een partitie- of bestelelement niet in de vensterfunctie voorkomt, laat u dat deel natuurlijk weg uit de indexdefinitie.
Maar hoe zit het met vragen met betrekking tot meerdere vensterfuncties met verschillende bestelbehoeften? Evenzo, wat als andere elementen in de query naast vensterfuncties ook invoergegevens vereisen zoals besteld in het plan, zoals een presentatie ORDER BY-clausule? Deze kunnen ertoe leiden dat verschillende delen van het plan de invoergegevens in verschillende volgordes moeten verwerken.
In dergelijke omstandigheden accepteert u doorgaans dat expliciete sortering onvermijdelijk is in het plan. Mogelijk merkt u dat de syntactische rangschikking van uitdrukkingen in de zoekopdracht van invloed kan zijn op hoeveel expliciete sorteeroperatoren die u in het plan krijgt. Door enkele basistips te volgen, kunt u soms het aantal expliciete sorteeroperatoren verminderen, wat natuurlijk een grote impact kan hebben op de prestaties van de zoekopdracht.
Omgeving voor demo's
In mijn voorbeelden gebruik ik de voorbeelddatabase PerformanceV5. U kunt hier de broncode downloaden om deze database aan te maken en te vullen.
Ik heb alle voorbeelden uitgevoerd op SQL Server 2019 Developer, waar batch-modus op rowstore beschikbaar is.
In dit artikel wil ik me concentreren op tips die te maken hebben met het potentieel van de berekening van de vensterfunctie in het plan om te vertrouwen op geordende invoergegevens zonder dat een extra expliciete sorteeractiviteit in het plan vereist is. Dit is relevant wanneer de optimizer een seriële of parallelle rijmodusbehandeling van vensterfuncties gebruikt en wanneer een seriële batchmodus Window Aggregate-operator wordt gebruikt.
SQL Server ondersteunt momenteel geen efficiënte combinatie van een parallelle invoer voor orderbehoud voorafgaand aan een parallelle batch-modus Window Aggregate-operator. Dus om een parallelle batch-mode Window Aggregate-operator te gebruiken, moet de optimizer een intermediaire parallelle batch-mode Sort-operator injecteren, zelfs als de invoer al vooraf is besteld.
Omwille van de eenvoud kunt u parallellisme voorkomen in alle voorbeelden in dit artikel. Om dit te bereiken zonder dat u een hint aan alle query's hoeft toe te voegen en zonder een serverbrede configuratieoptie in te stellen, kunt u de configuratieoptie voor databasebereik instellen MAXDOP naar 1 , zoals zo:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Vergeet niet om het terug te zetten naar 0 nadat u klaar bent met het testen van de voorbeelden in dit artikel. Ik zal je er aan het einde aan herinneren.
Als alternatief kunt u parallellisme op sessieniveau voorkomen met de ongedocumenteerde DBCC OPTIMIZER_WHATIF commando, zoals zo:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Om de optie opnieuw in te stellen wanneer u klaar bent, roept u deze opnieuw op met de waarde 0 als het aantal CPU's.
Als je klaar bent met het uitproberen van alle voorbeelden in dit artikel terwijl parallellisme is uitgeschakeld, raad ik aan om parallellisme in te schakelen en alle voorbeelden opnieuw te proberen om te zien wat er verandert.
Tips 1 en 2
Laten we, voordat ik met de tips begin, eerst kijken naar een eenvoudig voorbeeld met een vensterfunctie die is ontworpen om te profiteren van een supp class="border indent shadow orting index.
Beschouw de volgende vraag, die ik vraag 1 noem:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Maak je geen zorgen over het feit dat het voorbeeld gekunsteld is. Er is geen goede zakelijke reden om een doorlopend totaal van order-ID's te berekenen:deze tabel heeft een behoorlijke omvang met rijen van 1 MM en ik wilde een eenvoudig voorbeeld laten zien met een algemene vensterfunctie, zoals een functie die een lopende totale berekening toepast.
Door het POC-indexeringsschema te volgen, maakt u de volgende index om de zoekopdracht te ondersteunen:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Het plan voor deze zoekopdracht wordt getoond in figuur 1.
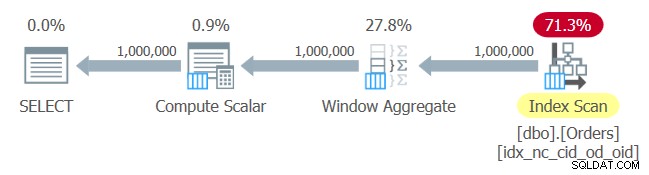 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
Geen verrassingen hier. Het plan past een indexvolgorde-scan toe van de index die u zojuist hebt gemaakt, en levert de bestelde gegevens aan de Window Aggregate-operator, zonder dat expliciete sortering nodig is.
Overweeg vervolgens de volgende vraag, die meerdere vensterfuncties met verschillende bestelbehoeften omvat, evenals een presentatie ORDER BY-clausule:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Ik noem deze query Query 2. Het plan voor deze query wordt getoond in Afbeelding 2.
 Figuur 2:Plan voor Query 2
Figuur 2:Plan voor Query 2
Merk op dat er vier sorteeroperatoren in het plan zijn.
Als u de verschillende vensterfuncties en bestelbehoeften voor presentaties analyseert, zult u zien dat er drie verschillende bestelbehoeften zijn:
- custid, orderdatum, orderid
- bestelnummer
- custid, orderid
Aangezien een van hen (de eerste in de bovenstaande lijst) kan worden ondersteund door de index die u eerder hebt gemaakt, zou u verwachten dat u slechts twee soorten in het plan ziet. Dus waarom heeft het plan vier soorten? Het lijkt erop dat SQL Server niet te geavanceerd probeert te zijn met het herschikken van de verwerkingsvolgorde van de functies in het plan om sorteringen te minimaliseren. Het verwerkt de functies in het plan in de volgorde waarin ze in de query voorkomen. Dat is in ieder geval het geval voor het eerste optreden van elke afzonderlijke bestelbehoefte, maar ik zal hier binnenkort op ingaan.
U kunt de noodzaak voor sommige soorten in het plan wegnemen door de volgende twee eenvoudige praktijken toe te passen:
Tip 1:Als je een index hebt om sommige vensterfuncties in de query te ondersteunen, specificeer die dan eerst.
Tip 2:Als de query vensterfuncties omvat met dezelfde bestelbehoefte als de presentatievolgorde in de query, geeft u die functies als laatste op.
Door deze tips te volgen, herschikt u de weergavevolgorde van de vensterfuncties in de query als volgt:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Ik noem deze zoekopdracht Query 3. Het plan voor deze zoekopdracht wordt weergegeven in Afbeelding 3.
 Figuur 3:Plan voor Query 3
Figuur 3:Plan voor Query 3
Zoals je kunt zien, heeft het plan nu slechts twee soorten.
Tip 3
SQL Server probeert niet al te geavanceerd te zijn in het herschikken van de verwerkingsvolgorde van vensterfuncties in een poging om sorteringen in het plan te minimaliseren. Het is echter in staat tot een bepaalde eenvoudige herschikking. Het scant de vensterfuncties op basis van de weergavevolgorde in de zoekopdracht en elke keer dat het een nieuwe duidelijke bestelbehoefte detecteert, kijkt het vooruit naar extra vensterfuncties met dezelfde bestelbehoefte en als het deze vindt, groepeert het ze samen met het eerste exemplaar. In sommige gevallen kan het zelfs dezelfde operator gebruiken om meerdere vensterfuncties te berekenen.
Beschouw de volgende vraag als voorbeeld:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Ik noem deze query Query 4. Het plan voor deze query wordt getoond in figuur 4.
 Figuur 4:Plan voor Query 4
Figuur 4:Plan voor Query 4
Vensterfuncties met dezelfde bestelbehoeften worden niet gegroepeerd in de query. Er staan echter nog maar twee soorten in het plan. Dit komt omdat wat telt in termen van verwerkingsvolgorde in het plan, het eerste optreden van elke afzonderlijke bestelbehoefte is. Dit brengt me bij de derde tip.
Tip 3:Zorg ervoor dat u de tips 1 en 2 volgt voor het eerste optreden van elke afzonderlijke bestelbehoefte. Latere gevallen van dezelfde bestelbehoefte, zelfs als ze niet aangrenzend zijn, worden geïdentificeerd en gegroepeerd met de eerste.
Tips 4 en 5
Stel dat u kolommen wilt retourneren die het resultaat zijn van vensterberekeningen in een bepaalde volgorde van links naar rechts in de uitvoer. Maar wat als de volgorde niet hetzelfde is als de volgorde die de sortering in het plan minimaliseert?
Stel dat u hetzelfde resultaat wilt als het resultaat dat door Query 2 is geproduceerd in termen van kolomvolgorde van links naar rechts in de uitvoer (kolomvolgorde:andere cols, sum2, sum1, sum3), maar dat u liever de hetzelfde plan als dat voor Query 3 (kolomvolgorde:andere cols, sum1, sum3, sum2), dat twee soorten kreeg in plaats van vier.
Dat is prima te doen als je bekend bent met de vierde tip.
Tip 4:De bovengenoemde aanbevelingen zijn van toepassing op de weergavevolgorde van vensterfuncties in de code, zelfs binnen een benoemde tabelexpressie zoals een CTE of view, en zelfs als de buitenste query de kolommen in een andere volgorde retourneert dan in de benoemde tabeluitdrukking. Daarom, als u kolommen in een bepaalde volgorde in de uitvoer moet retourneren, en deze verschilt van de optimale volgorde in termen van het minimaliseren van sorteringen in het plan, volgt u de tips in termen van weergavevolgorde binnen een benoemde tabelexpressie en retourneert u de kolommen in de buitenste query in de gewenste uitvoervolgorde.
De volgende query, die ik Query 5 zal noemen, illustreert deze techniek:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Het plan voor deze zoekopdracht wordt getoond in figuur 5.
 Figuur 5:Plan voor Query 5
Figuur 5:Plan voor Query 5
U krijgt nog steeds slechts twee soorten in het plan, ondanks het feit dat de kolomvolgorde in de uitvoer is:andere cols, sum2, sum1, sum3, zoals in Query 2.
Een waarschuwing bij deze truc met de benoemde tabeluitdrukking is dat als uw kolommen in de tabeluitdrukking niet worden verwezen door de buitenste query, ze worden uitgesloten van het plan en daarom niet meetellen.
Beschouw de volgende vraag, die ik vraag 6 zal noemen:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Hier wordt naar alle tabeluitdrukkingskolommen verwezen door de buitenste query, dus optimalisatie vindt plaats op basis van het eerste afzonderlijke voorkomen van elke bestelbehoefte binnen de tabeluitdrukking:
- max1:custid, orderdatum, orderid
- max3:bestel-id
- max2:custid, orderid
Dit resulteert in een plan met slechts twee soorten zoals weergegeven in figuur 6.
 Figuur 6:Plan voor Query 6
Figuur 6:Plan voor Query 6
Wijzig nu alleen de buitenste query door de verwijzingen naar max2, max1, max3, avg2, avg1 en avg3 te verwijderen, zoals:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Ik zal naar deze query verwijzen als Query 7. De berekeningen van max1, max3, max2, avg1, avg3 en avg2 in de tabelexpressie zijn niet relevant voor de buitenste query, dus worden ze uitgesloten. De overige berekeningen met vensterfuncties in de tabeluitdrukking, die relevant zijn voor de buitenste query, zijn die van sum2, sum1 en sum3. Helaas verschijnen ze niet in de tabeluitdrukking in optimale volgorde wat betreft het minimaliseren van sorteringen. Zoals je kunt zien in het plan voor deze zoekopdracht, zoals weergegeven in figuur 7, zijn er vier soorten.
 Figuur 7:Plan voor Query 7
Figuur 7:Plan voor Query 7
Als u denkt dat het onwaarschijnlijk is dat u kolommen in de inner query zult hebben waarnaar u niet zult verwijzen in de outer query, denk aan views. Elke keer dat u een weergave opvraagt, bent u mogelijk geïnteresseerd in een andere subset van de kolommen. Met dit in gedachten kan de vijfde tip helpen bij het verminderen van soorten in het plan.
Tip 5:In de innerlijke query van een benoemde tabelexpressie zoals een CTE of view, groepeer je alle vensterfuncties met dezelfde bestelbehoeften bij elkaar en volg je tips 1 en 2 in de volgorde van de groepen functies.
De volgende code implementeert een weergave op basis van deze aanbeveling:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Vraag nu de weergave op en vraag alleen om de resultaatkolommen sum2, sum1 en sum3, in deze volgorde:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Ik zal naar deze query verwijzen als Query 8. U krijgt het plan weergegeven in Afbeelding 8 met slechts twee soorten.
 Figuur 8:Plan voor Query 8
Figuur 8:Plan voor Query 8
Tip 6
Wanneer u een vraag heeft met meerdere vensterfuncties met meerdere duidelijke bestelbehoeften, is de algemene wijsheid dat u slechts één daarvan kunt ondersteunen met vooraf bestelde gegevens via een index. Dit is zelfs het geval wanneer alle vensterfuncties respectievelijke ondersteunende indexen hebben.
Laat me dit aantonen. Herinner u eerder toen u de index idx_nc_cid_od_oid maakte, die vensterfuncties kan ondersteunen die de gegevens nodig hebben die zijn geordend op custid, orderdate, orderid, zoals de volgende uitdrukking:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Stel dat je naast deze vensterfunctie ook de volgende vensterfunctie nodig hebt in dezelfde query:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Deze vensterfunctie zou baat hebben bij de volgende index:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
De volgende vraag, die ik vraag 9 zal noemen, roept beide vensterfuncties op:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Het plan voor deze zoekopdracht wordt getoond in figuur 9.
 Figuur 9:Plan voor Query 9
Figuur 9:Plan voor Query 9
Ik krijg de volgende tijdstatistieken voor deze zoekopdracht op mijn computer, met resultaten weggegooid in SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Zoals eerder uitgelegd, scant SQL Server de vensterexpressies in volgorde van voorkomen in de query en denkt dat het de eerste kan ondersteunen met een geordende scan van de index idx_nc_cid_od_oid. Maar dan voegt het een sorteeroperator toe aan het plan om de gegevens te ordenen zoals de tweede vensterfunctie nodig heeft. Dit betekent dat het plan N log N schaling heeft. Het overweegt niet om de index idx_nc_cid_oid te gebruiken om de tweede vensterfunctie te ondersteunen. Je denkt waarschijnlijk dat het niet kan, maar probeer een beetje buiten de kaders te denken. Zou je niet elk van de vensterfuncties kunnen berekenen op basis van de respectieve indexvolgorde en dan de resultaten samenvoegen? Theoretisch kan dat, en afhankelijk van de grootte van de gegevens, de beschikbaarheid van indexering en andere beschikbare bronnen, zou de join-versie het soms beter kunnen doen. SQL Server houdt geen rekening met deze benadering, maar je kunt het zeker implementeren door de join zelf te schrijven, zoals:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Ik noem deze query Query 10. Het plan voor deze query wordt getoond in Afbeelding 10.
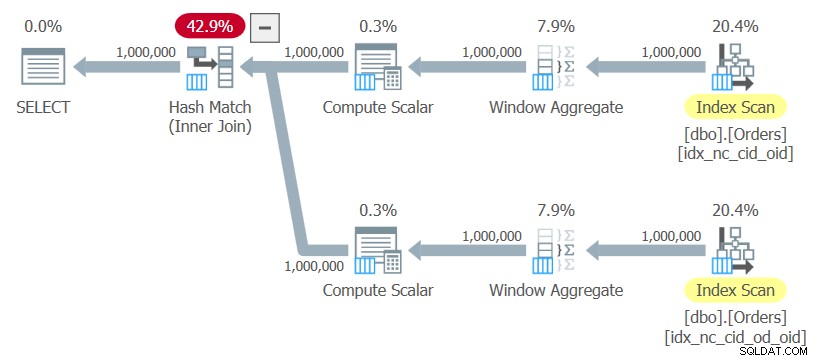 Figuur 10:Plan voor Query 10
Figuur 10:Plan voor Query 10
Het plan gebruikt geordende scans van de twee indexen zonder enige expliciete sortering, berekent de vensterfuncties en gebruikt een hash-join om de resultaten samen te voegen. Dit plan wordt lineair geschaald in vergelijking met het vorige, dat een N log N-schaal heeft.
Ik krijg de volgende tijdstatistieken voor deze zoekopdracht op mijn computer (opnieuw met de resultaten weggegooid in SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
Om het samen te vatten, hier is onze zesde tip.
Tip 6:Als je meerdere vensterfuncties hebt met meerdere verschillende bestelbehoeften, en je kunt ze allemaal ondersteunen met indexen, probeer dan een join-versie en vergelijk de prestaties met de query zonder de join.
Opruimen
Als u parallellisme hebt uitgeschakeld door de configuratieoptie MAXDOP met databasebereik in te stellen op 1, schakelt u parallellisme opnieuw in door het in te stellen op 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Als je de ongedocumenteerde sessie-optie DBCC OPTIMIZER_WHATIF hebt gebruikt met de CPU-optie ingesteld op 1, schakel dan parallellisme opnieuw in door deze op 0 in te stellen:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Je kunt alle voorbeelden opnieuw proberen met parallellisme ingeschakeld als je wilt.
Gebruik de volgende code om de nieuwe indexen die u hebt gemaakt op te schonen:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
En de volgende code om de weergave te verwijderen:
DROP VIEW IF EXISTS dbo.MyView;
Volg de tips om het aantal sorteringen te minimaliseren
Vensterfuncties moeten de bestelde invoergegevens verwerken. Indexering kan helpen bij het elimineren van sorteren in het plan, maar normaal gesproken alleen voor één duidelijke bestelbehoefte. Query's met meerdere bestelbehoeften hebben meestal een aantal soorten in hun plannen. Door bepaalde tips op te volgen, kunt u het aantal benodigde soorten echter minimaliseren. Hier is een samenvatting van de tips die ik in dit artikel heb genoemd:
- Tip 1: Als u een index hebt om sommige vensterfuncties in de query te ondersteunen, geeft u deze eerst op.
- Tip 2: Als de query vensterfuncties omvat met dezelfde bestelbehoefte als de presentatievolgorde in de query, geeft u die functies als laatste op.
- Tip 3: Zorg ervoor dat u tips 1 en 2 volgt voor het eerste optreden van elke afzonderlijke bestelbehoefte. Opeenvolgende gevallen van dezelfde ordeningsbehoefte, zelfs als ze niet aangrenzend zijn, worden geïdentificeerd en samen met de eerste gegroepeerd.
- Tip 4: De bovengenoemde aanbevelingen zijn van toepassing op de weergavevolgorde van vensterfuncties in de code, zelfs binnen een benoemde tabelexpressie zoals een CTE of view, en zelfs als de buitenste query de kolommen in een andere volgorde retourneert dan in de benoemde tabelexpressie. Daarom, als u kolommen in een bepaalde volgorde in de uitvoer moet retourneren en deze verschilt van de optimale volgorde in termen van het minimaliseren van sorteringen in het plan, volgt u de tips in termen van weergavevolgorde binnen een benoemde tabelexpressie en retourneert u de kolommen in de buitenste query in de gewenste uitvoervolgorde.
- Tip 5: In de innerlijke query van een benoemde tabeluitdrukking zoals een CTE of view, groepeert u alle vensterfuncties met dezelfde bestelbehoeften bij elkaar en volgt u tips 1 en 2 in de volgorde van de groepen functies.
- Tip 6: Als je meerdere vensterfuncties hebt met meerdere verschillende bestelbehoeften, en je kunt ze allemaal ondersteunen met indexen, probeer dan een join-versie en vergelijk de prestaties met de query zonder de join.