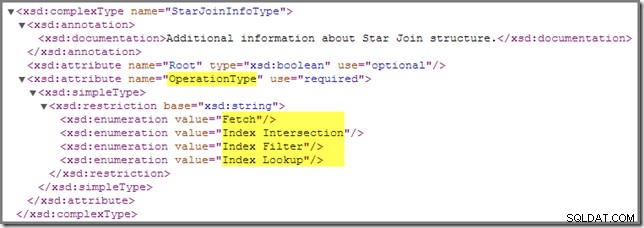
Van tijd tot tijd merkt u misschien dat een of meer joins in een uitvoeringsplan zijn geannoteerd met een StarJoinInfo structuur. Het officiële showplan-schema zegt het volgende over dit planelement (klik om te vergroten):
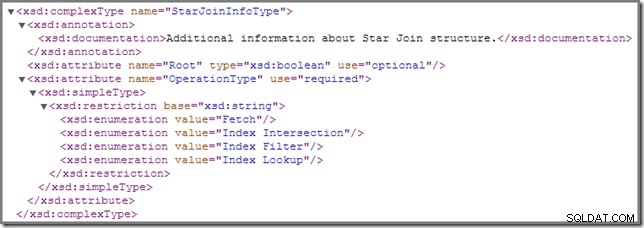
De in-line documentatie die daar wordt getoond ("aanvullende informatie over de Star Join-structuur ") is niet zo verhelderend, hoewel de andere details behoorlijk intrigerend zijn - we zullen deze in detail bekijken.
Als u uw favoriete zoekmachine raadpleegt voor meer informatie met termen als "SQL Server star join-optimalisatie", ziet u waarschijnlijk resultaten die geoptimaliseerde bitmapfilters beschrijven. Dit is een aparte Enterprise-only functie die is geïntroduceerd in SQL Server 2008 en niet gerelateerd is aan de StarJoinInfo helemaal geen structuur.
Optimalisaties voor selectieve sterquery's
De aanwezigheid van StarJoinInfo geeft aan dat SQL Server een van een reeks optimalisaties heeft toegepast die zijn gericht op selectieve sterschemaquery's. Deze optimalisaties zijn beschikbaar vanaf SQL Server 2005, in alle edities (niet alleen Enterprise). Merk op dat selectief verwijst hier naar het aantal rijen dat is opgehaald uit de feitentabel. De combinatie van dimensionale predikaten in een zoekopdracht kan nog steeds selectief zijn, zelfs als de afzonderlijke predikaten een groot aantal rijen kwalificeren.
Gewone indexkruising
De query-optimizer kan overwegen om meerdere niet-geclusterde indexen te combineren waar geen geschikte enkele index bestaat, zoals de volgende AdventureWorks-query laat zien:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
De optimizer bepaalt dat het combineren van twee niet-geclusterde indexen (één op SalesPersonID en de andere op CustomerID ) is de goedkoopste manier om aan deze vraag te voldoen (er is geen index op beide kolommen):
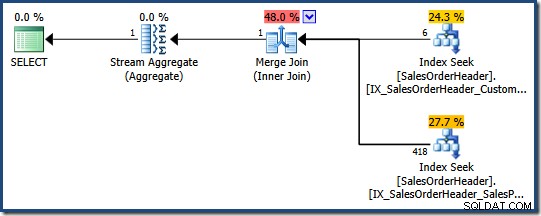
Elke indexzoekopdracht retourneert de geclusterde indexsleutel voor rijen die het predikaat doorgeven. De join komt overeen met de geretourneerde sleutels om ervoor te zorgen dat alleen rijen overeenkomen met beide predikaten worden doorgegeven.
Als de tabel een hoop was, zou elke zoekopdracht heap rij-ID's (RID's) retourneren in plaats van geclusterde indexsleutels, maar de algemene strategie is hetzelfde:zoek rij-ID's voor elk predikaat en koppel ze vervolgens aan elkaar.
Handmatige Star Join Index Intersection
Hetzelfde idee kan worden uitgebreid tot query's die rijen selecteren uit een feitentabel met behulp van predikaten die worden toegepast op dimensietabellen. Om te zien hoe dit werkt, kunt u met de volgende zoekopdracht (met behulp van de Contoso BI-voorbeelddatabase) het totale verkoopbedrag vinden voor mp3-spelers die worden verkocht in Contoso-winkels met precies 50 werknemers:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Ter vergelijking met latere pogingen, levert deze (zeer selectieve) zoekopdracht een zoekplan op zoals het volgende (klik om uit te vouwen):
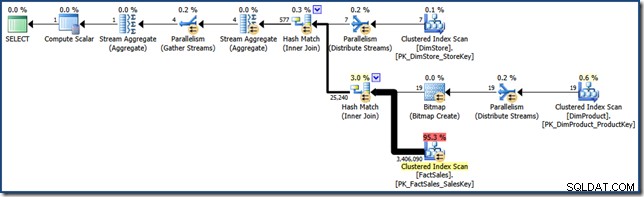
Dat uitvoeringsplan heeft een geschatte kostprijs van iets meer dan 15,6 eenheden . Het beschikt over parallelle uitvoering met een volledige scan van de feitentabel (zij het met een bitmapfilter toegepast).
De feitentabellen in deze voorbeelddatabase bevatten standaard geen niet-geclusterde indexen op de externe sleutels van de feitentabel, dus we moeten er een paar toevoegen:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Met deze indexen kunnen we beginnen te zien hoe indexkruisingen kunnen worden gebruikt om de efficiëntie te verbeteren. De eerste stap is het vinden van rij-ID's voor feitentabel voor elk afzonderlijk predikaat. De volgende query's passen een enkelvoudig dimensiepredikaat toe en komen vervolgens terug in de feitentabel om rij-ID's te vinden (geclusterde indexsleutels van de feitentabel):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; De queryplannen tonen een scan van de kleine dimensietabel, gevolgd door zoekopdrachten met behulp van de niet-geclusterde index van de feitentabel om rij-ID's te vinden (onthoud dat niet-geclusterde indexen altijd de basistabelclustersleutel of heap-RID bevatten):
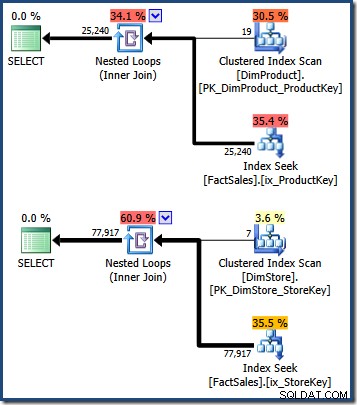
Het snijpunt van deze twee sets geclusterde indexsleutels van feitentabel identificeert de rijen die door de oorspronkelijke query moeten worden geretourneerd. Zodra we deze rij-ID's hebben, hoeven we alleen maar het Verkoopbedrag op te zoeken in elke rij met feitentabel en de som te berekenen.
Handmatige indexkruising zoeken
Als je dat allemaal samenvoegt in een query, krijg je het volgende:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
De FORCESEEK hint is er om ervoor te zorgen dat we point-lookups naar de feitentabel krijgen. Zonder dit kiest de optimizer ervoor om de feitentabel te scannen, en dat is precies wat we willen vermijden. De MAXDOP 1 hint helpt alleen om het uiteindelijke plan redelijk groot te houden voor weergavedoeleinden (klik om het op ware grootte te zien):
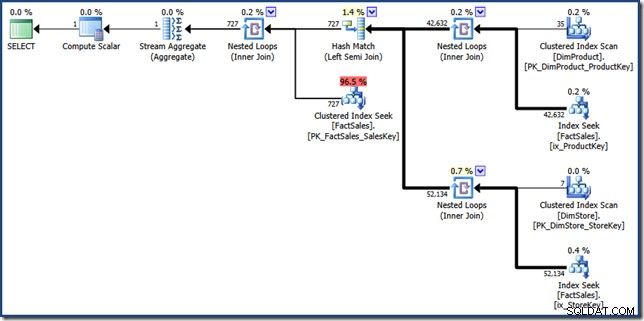
De onderdelen van het handmatige indexkruisingsplan zijn vrij eenvoudig te identificeren. De twee niet-geclusterde index-zoekopdrachten voor feitentabel aan de rechterkant produceren de twee sets rij-ID's voor feitentabel. De hash-join vindt het snijpunt van deze twee sets. De geclusterde index-zoekopdracht in de feitentabel vindt de verkoopbedragen voor deze rij-ID's. Ten slotte berekent de Stream Aggregate het totale bedrag.
Dit queryplan voert relatief weinig opzoekingen uit in de niet-geclusterde en geclusterde indexen van de feitentabel. Als de query selectief genoeg is, kan dit een goedkopere uitvoeringsstrategie zijn dan de feitentabel volledig te scannen. De voorbeelddatabase van Contoso BI is relatief klein, met slechts 3,4 miljoen rijen in de tabel met verkoopfeiten. Voor grotere feitentabellen kan het verschil tussen een volledige scan en een paar honderd zoekopdrachten erg groot zijn. Helaas introduceert de handmatige herschrijving enkele ernstige kardinaliteitsfouten, wat resulteert in een plan met geschatte kosten van 46.5 eenheden .
Automatisch Star Join Index-kruispunt met zoekopdrachten
Gelukkig hoeven we niet te beslissen of de query die we schrijven selectief genoeg is om deze handmatige herschrijving te rechtvaardigen. Dankzij de star-join-optimalisaties voor selectieve zoekopdrachten kan de query-optimizer deze optie voor ons verkennen, met behulp van de gebruiksvriendelijkere originele query-syntaxis:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
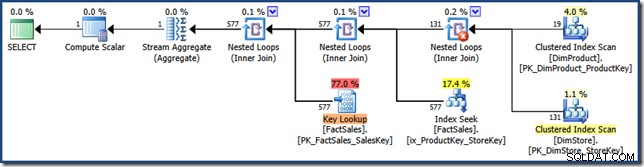
AND DP.ProductName LIKE N'%MP3%'; De optimizer produceert het volgende uitvoeringsplan met een geschatte kostprijs van 1,64 eenheden (klik om te vergroten):
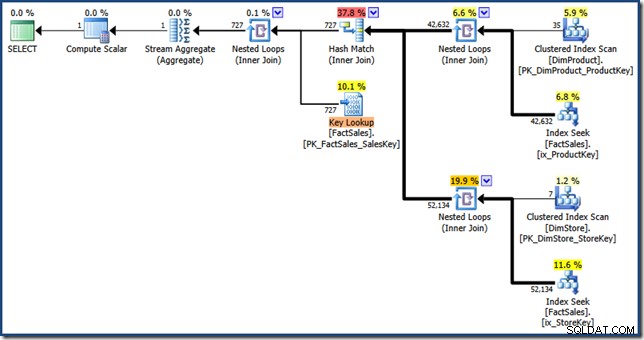
De verschillen tussen dit plan en de handmatige versie zijn:het indexkruispunt is een inner join in plaats van een semi join; en de geclusterde index-lookup wordt weergegeven als een Key Lookup in plaats van een Clustered Index Seek. Met het risico om het punt te vermoeien, als de feitentabel een hoop zou zijn, zou de sleutelzoekopdracht een RID-zoekopdracht zijn.
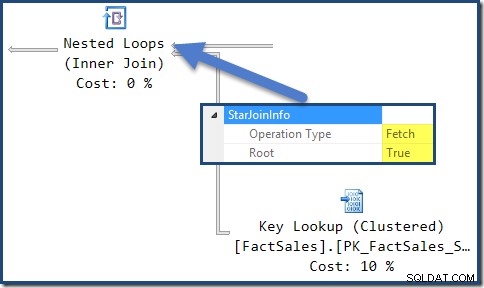
De StarJoinInfo-eigenschappen
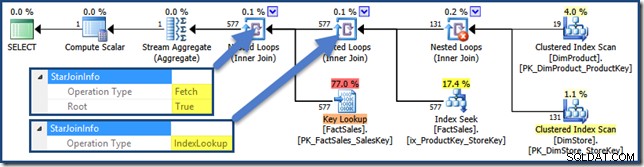
De joins in dit plan hebben allemaal een StarJoinInfo structuur. Om het te zien, klikt u op een join-iterator en kijkt u in het venster SSMS-eigenschappen. Klik op de pijl links van de StarJoinInfo element om het knooppunt uit te breiden.
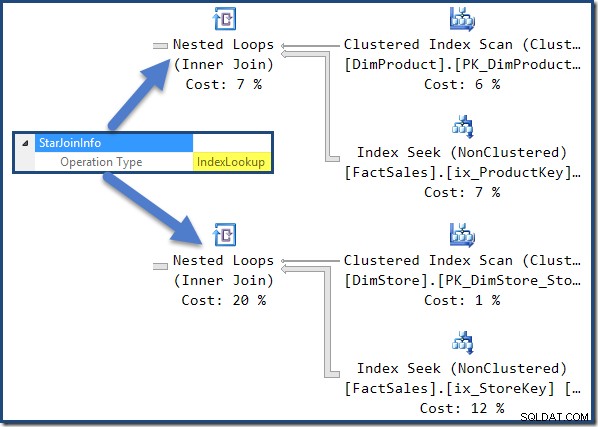
De niet-geclusterde feitentabel aan de rechterkant van het plan zijn Index Lookups gebouwd door de optimizer:
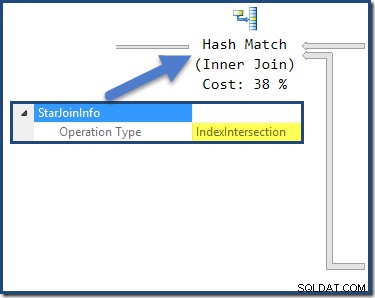
De hash-join heeft een StarJoinInfo structuur die laat zien dat het een indexkruising uitvoert (opnieuw vervaardigd door de optimizer):
De StarJoinInfo voor de meest linkse Nested Loops-joinshows is deze gegenereerd om rijen met feitentabel per rij-ID op te halen. Het bevindt zich aan de basis van de door de optimalisatie gegenereerde star join-subboom:
Cartesiaanse producten en index zoeken met meerdere kolommen
De indexkruisingsplannen die worden beschouwd als onderdeel van de optimalisaties voor star join zijn handig voor selectieve query's op feitentabellen waarbij niet-geclusterde indexen met één kolom bestaan op externe sleutels van feitentabellen (een veelvoorkomende ontwerppraktijk).
Het is soms ook zinvol om indexen met meerdere kolommen te maken op externe sleutels van feitentabel, voor vaak opgevraagde combinaties. De ingebouwde selectieve optimalisaties voor sterquery's bevatten ook een herschrijving voor dit scenario. Om te zien hoe dit werkt, voegt u de volgende index met meerdere kolommen toe aan de feitentabel:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Stel de testquery opnieuw samen:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Het zoekplan bevat geen indexkruispunt meer (klik om te vergroten):
De hier gekozen strategie is om elk predikaat toe te passen op de dimensietabellen, het cartesiaanse product van de resultaten te nemen en dat te gebruiken om in beide sleutels van de index met meerdere kolommen te zoeken. Het queryplan voert vervolgens een Key Lookup uit in de feitentabel met behulp van rij-ID's, precies zoals eerder gezien.
Het queryplan is vooral interessant omdat het drie functies combineert die vaak als slechte dingen worden beschouwd (volledige scans, cartesiaanse producten en belangrijke zoekacties) in een prestatie optimalisatie . Dit is een geldige strategie wanneer het product van de twee dimensies naar verwachting erg klein zal zijn.
Er is geen StarJoinInfo voor het cartesiaanse product, maar de andere joins hebben wel informatie (klik om te vergroten):
Indexfilter
Terugverwijzend naar het showplan-schema, is er nog een andere StarJoinInfo operatie die we moeten dekken:
Het Index Filter waarde wordt gezien met joins die als selectief genoeg worden beschouwd om de moeite waard te zijn om uit te voeren voordat de feitentabel wordt opgehaald. Joins die niet selectief genoeg zijn, worden uitgevoerd na het ophalen en hebben geen StarJoinInfo structuur.
Om een indexfilter te zien met onze testquery, moeten we een derde join-tabel aan de mix toevoegen, de niet-geclusterde feitentabelindexen die tot nu toe zijn gemaakt, verwijderen en een nieuwe toevoegen:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Het zoekplan is nu (klik om te vergroten):
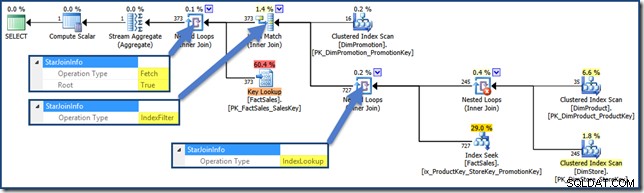
Een Heap Index Intersection Query Plan
Voor de volledigheid is hier een script om een heap-kopie van de feitentabel te maken met de twee niet-geclusterde indexen die nodig zijn om het herschrijven van de index-intersectieoptimalisatie mogelijk te maken:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Het uitvoeringsplan voor deze query heeft dezelfde functies als voorheen, maar de indexkruising wordt uitgevoerd met behulp van RID's in plaats van geclusterde indexsleutels uit de feitentabel, en de laatste ophaalactie is een RID-zoekopdracht (klik om uit te vouwen):
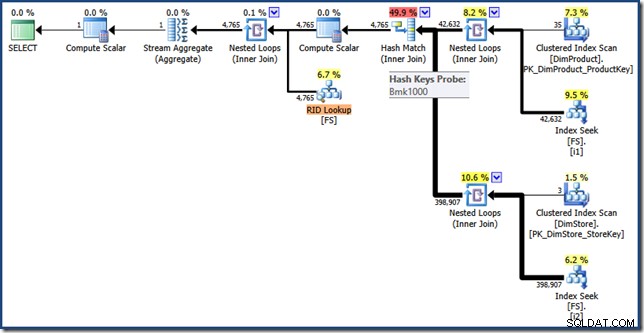
Laatste gedachten
De herschrijvingen van de optimalisatie die hier worden weergegeven, zijn gericht op zoekopdrachten die een relatief klein aantal rijen retourneren van een grote feiten tabel. Deze herschrijvingen zijn sinds 2005 beschikbaar in alle edities van SQL Server.
Hoewel bedoeld om selectieve ster- (en sneeuwvlok)-schemaquery's in datawarehousing te versnellen, kan het optimalisatieprogramma deze technieken overal toepassen waar het een geschikte set tabellen en joins detecteert. De heuristiek die wordt gebruikt om sterquery's te detecteren, is vrij breed, dus u kunt planvormen tegenkomen met StarJoinInfo structuren in zowat elk type database. Elke tabel van een redelijke omvang (zeg 100 pagina's of meer) met verwijzingen naar kleinere (dimensie-achtige) tabellen is een potentiële kandidaat voor deze optimalisaties (merk op dat expliciete externe sleutels niet zijn vereist).
Voor degenen onder u die van dergelijke dingen genieten, de optimalisatieregel die verantwoordelijk is voor het genereren van selectieve star-join-patronen van een logische n-table-join heet StarJoinToIdxStrategy (star join naar indexstrategie).