De allereerste blogpost op deze site, lang geleden in juli 2012, sprak over de beste benaderingen voor lopende totalen. Sindsdien is mij meerdere keren gevraagd hoe ik het probleem zou aanpakken als de lopende totalen complexer zouden zijn, met name als ik lopende totalen voor meerdere entiteiten moest berekenen, bijvoorbeeld de bestellingen van elke klant.
In het oorspronkelijke voorbeeld werd een fictief geval gebruikt van een stad die snelheidsboetes uitdeelde; het lopende totaal was simpelweg het optellen en bijhouden van het aantal snelheidsbekeuringen per dag (ongeacht aan wie het kaartje was uitgegeven of voor hoeveel het was). Een complexer (maar praktischer) voorbeeld zou het aggregeren van de actuele totale waarde van snelheidsboetes, gegroepeerd op rijbewijs, per dag kunnen zijn. Laten we ons de volgende tabel voorstellen:
MAAK TABEL dbo.SpeedingTickets( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL); MAAK UNIEKE INDEX x OP dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Je zou kunnen vragen, DECIMAL(7,2) , echt? Hoe snel gaan deze mensen? In Canada is het bijvoorbeeld niet zo moeilijk om een snelheidsboete van $ 10.000 te krijgen.
Laten we nu de tabel vullen met enkele voorbeeldgegevens. Ik zal hier niet op alle details ingaan, maar dit zou ongeveer 6.000 rijen moeten opleveren die meerdere chauffeurs en meerdere ticketbedragen vertegenwoordigen over een periode van een maand:
;WITH TicketAmounts(ID,Value) AS ( -- 10 willekeurige ticketbedragen SELECTEER i,p FROM ( VALUES(1,32,75),(2,75), (3,109),(4,175),(5,295), (6,68,50),(7,125),(8,145),(9,199),(10,250) ) AS v(i,p)),LicenseNumbers(LicenseNumber,[newid]) AS ( -- 1000 willekeurige licentienummers SELECT TOP ( 1000) 7000000 + nummer, n =NEWID() FROM [master].dbo.spt_values WHERE number TUSSEN 1 EN 999999 ORDER BY n),JanuaryDates([day]) AS ( -- elke dag in januari 2014 SELECTEER TOP (31) DATEADD(DAY, number, '20140101') FROM [master].dbo.spt_values WHERE [type] =N'P' ORDER BY number),Tickets(LicenseNumber,[day],s) AS( -- match *some* licenties tot dagen dat ze tickets kregen SELECT DISTINCT l.LicenseNumber, d.[day], s =RTRIM(l.LicenseNumber) FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d WHERE CHECKSUM(NEWID()) % 100 =l.LicenseNumber % 100 AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%') OR (RTRIM(l.LicenseNumber+1) LIKE ' %' + RECHTS( CONVERT(CHAR(8), d.[day], 112),1) + '%'))INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)SELECT t.LicenseNumber, t.[day], ta.Value FROM Tickets AS t INNER JOIN TicketAmounts AS ta ON ta.ID =CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1)) BESTELLEN BY t.[dag], t .Licentienummer;
Dit lijkt misschien een beetje te ingewikkeld, maar een van de grootste uitdagingen die ik vaak heb bij het opstellen van deze blogposts, is het construeren van een geschikte hoeveelheid realistische "willekeurige" / willekeurige gegevens. Als je een betere methode hebt voor het willekeurig verzamelen van gegevens, gebruik dan in ieder geval mijn gemompel niet als voorbeeld - ze zijn perifeer op het punt van dit bericht.
Benaderingen
Er zijn verschillende manieren om dit probleem in T-SQL op te lossen. Hier zijn zeven benaderingen, samen met de bijbehorende plannen. Ik heb technieken zoals cursors (omdat ze onmiskenbaar langzamer zullen zijn) en op datum gebaseerde recursieve CTE's weggelaten (omdat ze afhankelijk zijn van aaneengesloten dagen).
Subquery #1
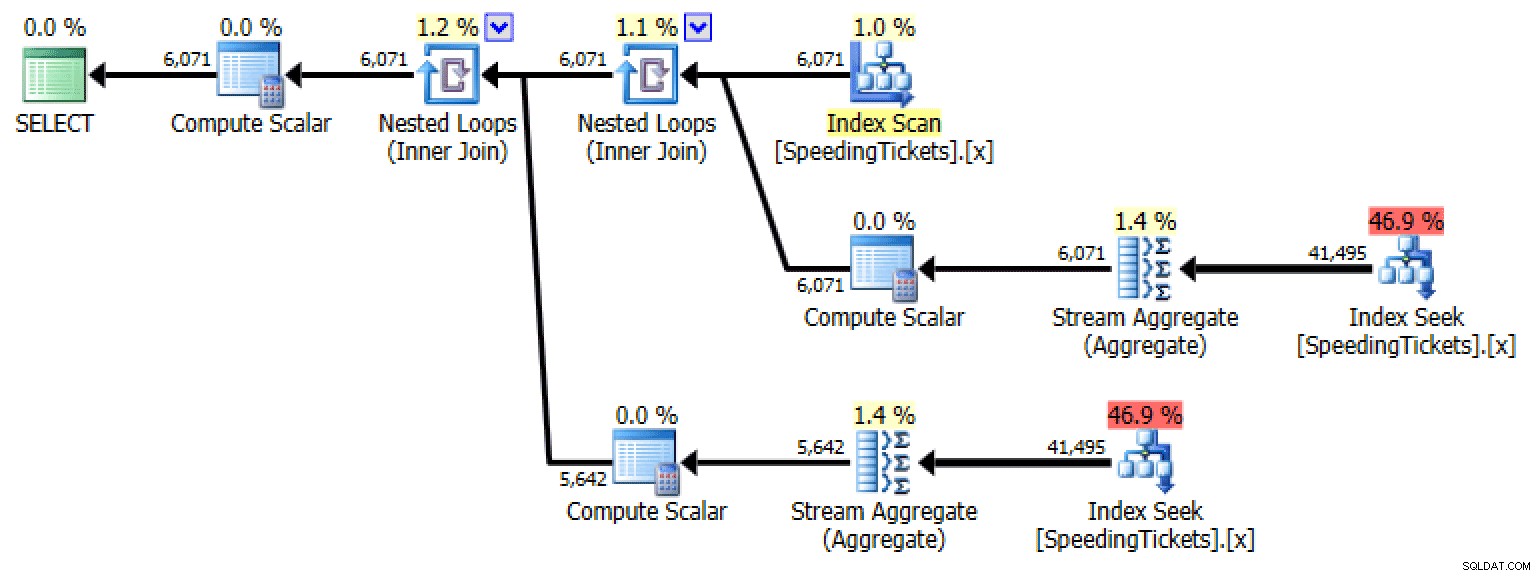
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =TicketAmount + COALESCE( ( SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets AS s WHERE s.LicenseNumber =o.LicenseNumber AND s.IncidentDate
Plan voor subquery #1Subquery #2
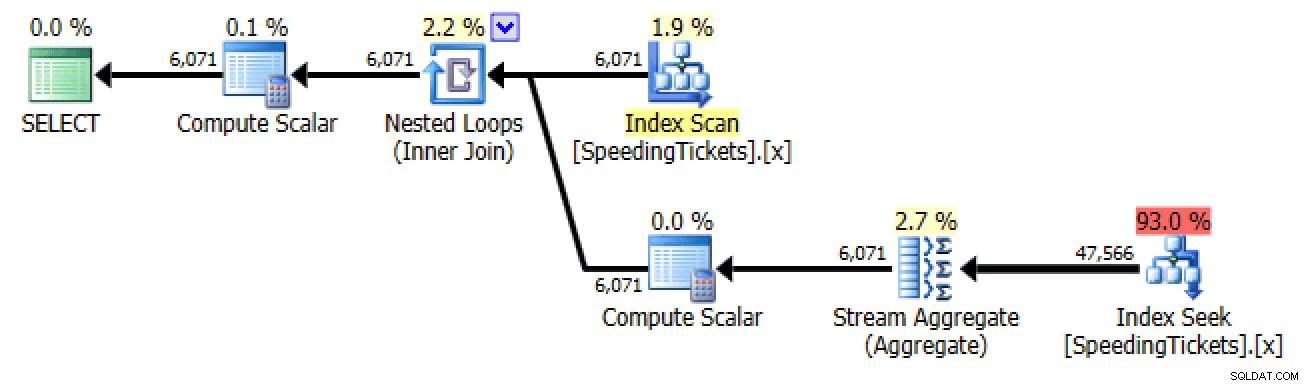
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =( SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets WHERE LicenseNumber =t.LicenseNumber AND IncidentDate <=t.IncidentDate )FROM dbo.SpeedingTickets AS tORDER BY LicenseNumber, Incident BYe>
Plan voor subquery #2Zelf lid worden
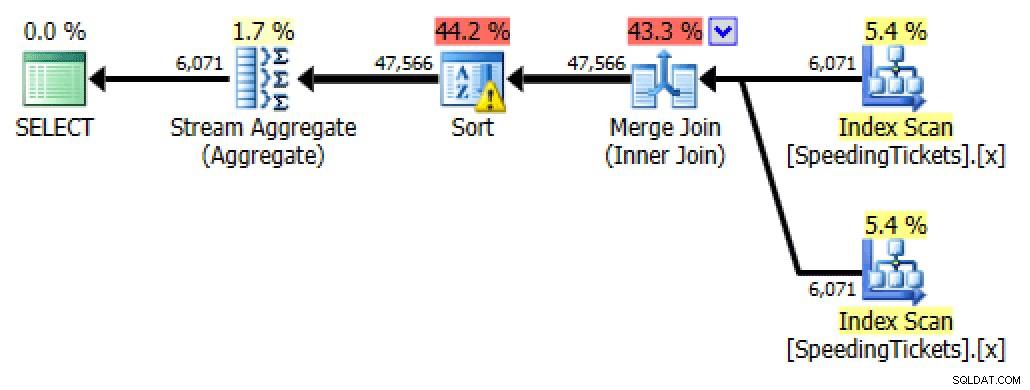
SELECTEER t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FROM dbo.SpeedingTickets AS t1INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNumber1ense t2. t2.IncidentDateGROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmountORDER BY t1.LicenseNumber, t1.IncidentDate;
Plan voor self-joinBuitenste toepassing
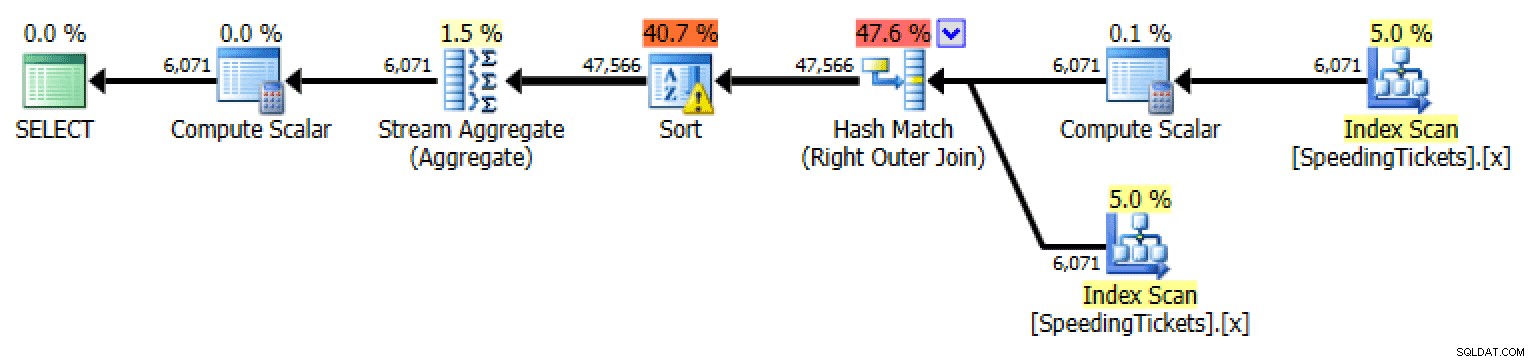
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FROM dbo.SpeedingTickets AS t1OUTER APPLY(SELECT TicketAmount FROM dbo.SpeedingTickets WHERE LicenseNumberenseNumber =t1.LicDateNumber IncidentDate) AS t2GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmountORDER BY t1.LicenseNumber, t1.IncidentDate;
Plan voor buitentoepassingSUM OVER() met RANGE (alleen 2012+)
SELECTEER LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER (VERDELING OP Licentienummer ORDER OP IncidentDate RANGE ONGEBONDEN VOORAFGAANDE) VANAF dbo.SpeedingTickets ORDER OP Licentienummer, IncidentDate;
Plan voor SUM OVER() met RANGESUM OVER() met RIJEN (alleen 2012+)
SELECTEER LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER (VERDELING OP Licentienummer ORDER OP IncidentDate RIJEN ONGEBONDEN VOORAFGAANDE) VANUIT dbo.SpeedingTickets ORDER OP Licentienummer, IncidentDate;
Plan voor SUM OVER() met RIJENSet-gebaseerde iteratie
Met dank aan Hugo Kornelis (@Hugo_Kornelis) voor hoofdstuk #4 in SQL Server MVP Deep Dives Volume #1, combineert deze benadering een set-gebaseerde benadering en een cursorbenadering.
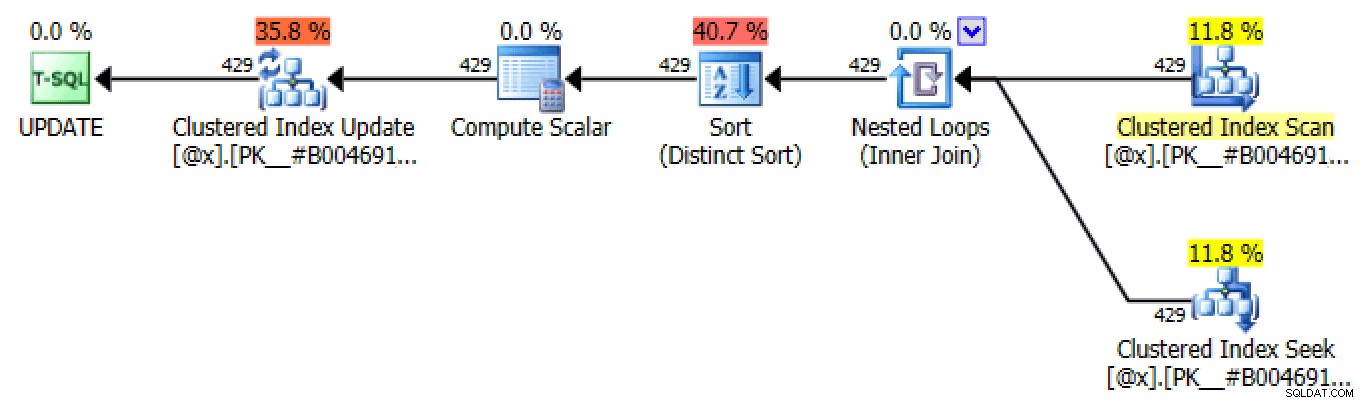
DECLARE @x TABLE( LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL, RunningTotal DECIMAL(7,2) NOT NULL, rn INT NOT NULL, PRIMARY KEY(LicenseNumber, IncidentDate) ); INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount, ROW_NUMBER() OVER (VERDELING OP Licentienummer ORDER OP IncidentDate) VANAF dbo.SpeedingTickets; VERKLAREN @rn INT =1, @rc INT =1; WHILE @rc> 0BEGIN SET @rn +=1; UPDATE [current] SET RunningTotal =[last].RunningTotal + [current].TicketAmount FROM @x AS [current] INNER JOIN @x AS [last] ON [current].LicenseNumber =[last].LicenseNumber AND [last]. rn =@rn - 1 WAAR [huidig].rn =@rn; SET @rc =@@ROWCOUNT;END SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal VAN @x ORDER BY LicenseNumber, IncidentDate;Vanwege zijn aard produceert deze aanpak veel identieke plannen tijdens het bijwerken van de tabelvariabele, die allemaal vergelijkbaar zijn met de plannen voor self-join en outer Apply, maar die een seek kunnen gebruiken:
Een van de vele UPDATE-plannen die zijn geproduceerd via set-gebaseerde iteratieHet enige verschil tussen elk plan in elke iteratie is het aantal rijen. Bij elke opeenvolgende iteratie moet het aantal betrokken rijen gelijk blijven of dalen, aangezien het aantal betrokken rijen bij elke iteratie het aantal chauffeurs vertegenwoordigt met tickets op dat aantal dagen (of, meer precies, het aantal dagen op die "rang").
Prestatieresultaten
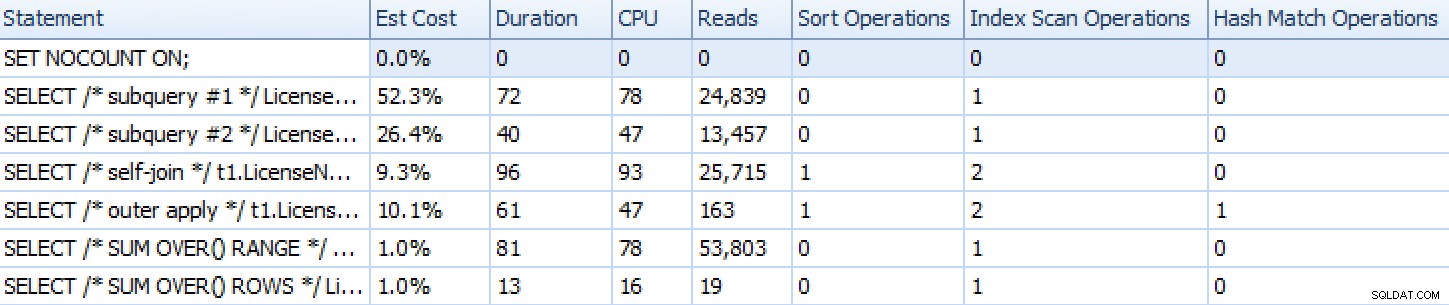
Hier is hoe de benaderingen zich opstapelden, zoals weergegeven door SQL Sentry Plan Explorer, met uitzondering van de set-gebaseerde iteratiebenadering die, omdat deze uit veel individuele instructies bestaat, niet goed vertegenwoordigt in vergelijking met de rest.
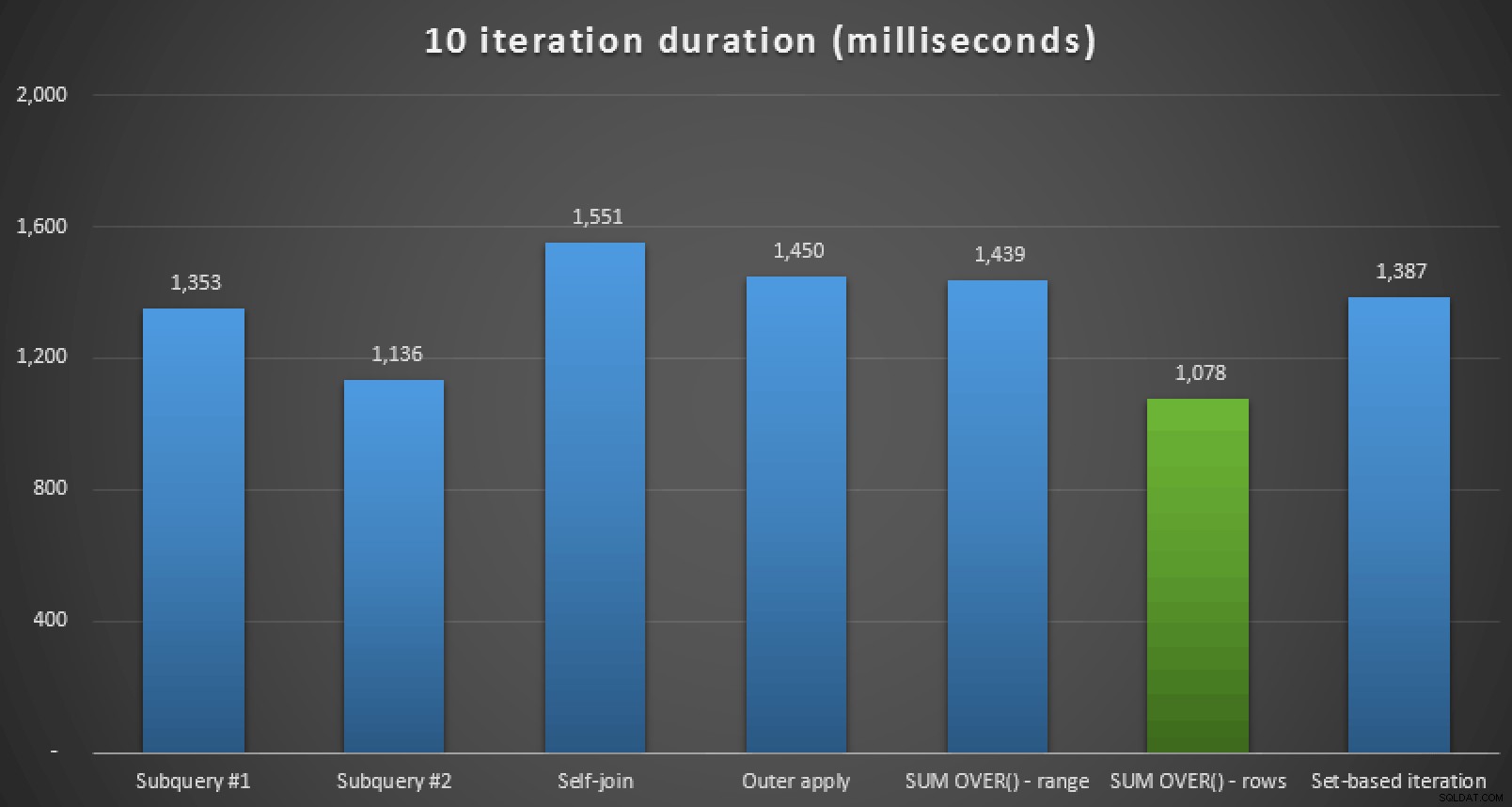
Runtime-statistieken van Plan Explorer voor zes van de zeven benaderingenNaast het bekijken van de plannen en het vergelijken van runtime-statistieken in Plan Explorer, heb ik ook de onbewerkte runtime gemeten in Management Studio. Hier zijn de resultaten van het 10 keer uitvoeren van elke query, waarbij u er rekening mee houdt dat dit ook de weergavetijd in SSMS omvat:
Runtimeduur, in milliseconden, voor alle zeven benaderingen (10 iteraties )Dus als u SQL Server 2012 of beter gebruikt, lijkt de beste aanpak
SUM OVER()te zijn. met behulp vanROWS UNBOUNDED PRECEDING. Als u geen SQL Server 2012 gebruikt, leek de tweede subquery-aanpak optimaal te zijn in termen van runtime, ondanks het hoge aantal reads in vergelijking met bijvoorbeeld deOUTER APPLYvraag. In alle gevallen dient u deze benaderingen, aangepast aan uw schema, natuurlijk te toetsen aan uw eigen systeem. Uw gegevens, indexen en andere factoren kunnen ertoe leiden dat een andere oplossing het meest optimaal is in uw omgeving.Andere complexiteiten
Nu geeft de unieke index aan dat elke combinatie van licentienummer + incidentdatum één cumulatief totaal zal bevatten, voor het geval een specifieke bestuurder meerdere tickets op een bepaalde dag krijgt. Deze bedrijfsregel helpt onze logica een beetje te vereenvoudigen, waardoor er geen tie-breaker nodig is om deterministische lopende totalen te produceren.
Als je gevallen hebt waarin je meerdere rijen hebt voor een bepaalde combinatie van Licentienummer + IncidentDate, kun je de band verbreken door een andere kolom te gebruiken die de combinatie uniek maakt (uiteraard zou de brontabel niet langer een unieke beperking hebben op die twee kolommen) . Merk op dat dit zelfs mogelijk is in gevallen waarin de
DATEkolom is eigenlijkDATETIME– veel mensen gaan ervan uit dat datum/tijd-waarden uniek zijn, maar dit is zeker niet altijd gegarandeerd, ongeacht de granulariteit.In mijn geval zou ik de
IDENTITY. kunnen gebruiken kolom,IncidentID; hier is hoe ik elke oplossing zou aanpassen (erkennend dat er misschien betere manieren zijn; gewoon ideeën weggooien):/* --------- subquery #1 --------- */ SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =TicketAmount + COALESCE( ( SELECT SUM(TicketAmount) FROM dbo. SpeedingTickets AS s WHERE s.LicenseNumber =o.LicenseNumber AND (s.IncidentDate=t2.IncidentDate -- deze regel toegevoegd:AND t1.IncidentID>=t2.IncidentIDGROUP BY t1, .License .TicketAmountORDER BY t1.Licentienummer, t1.IncidentDate; /* --------- buitenste toepassen --------- */ SELECTEER t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FROM dbo.SpeedingTickets AS t1OUTER APPLY(SELECT TicketAmount FROM dbo.SpeedingTickets WHERE LicenseNumber =t1.LicenseNumber AND IncidentDate <=t1.IncidentDate -- deze regel toegevoegd:AND IncidentID <=t1.IncidentID) AS t2GROUP BY t1.LicenseIncident,DateT1. DOOR t1.LicenseNumber, t1.IncidentDate; /* --------- SUM() OVER met RANGE --------- */ SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER (VERDELING OP Licentienummer ORDER DOOR IncidentDate, IncidentID-BEREIK ONGEBONDEN VOORAFGAANDE -- deze kolom toegevoegd ^^^^^^^^^^^^ ) VANUIT dbo.SpeedingTickets ORDER OP Licentienummer, IncidentDate; /* --------- SUM() OVER met ROWS --------- */ SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER (VERDELING OP Licentienummer ORDER DOOR IncidentDate, IncidentID RIJEN ONGEBONDEN VOORAFGAANDE -- deze kolom toegevoegd ^^^^^^^^^^^^ ) VANUIT dbo.SpeedingTickets ORDER OP Licentienummer, IncidentDate; /* --------- set-gebaseerde iteratie --------- */ DECLARE @x TABLE( -- deze kolom toegevoegd en de PK:IncidentID INT PRIMARY KEY, LicenseNumber INT gemaakt NOT NULL, IncidentDate DATUM NIET NULL, TicketAmount DECIMAL(7,2) NOT NULL, RunningTotal DECIMAL(7,2) NOT NULL, rn INT NOT NULL); -- de extra kolom toegevoegd aan de INSERT/SELECT:INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount, ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate , IncidentID) -- en deze tie-breaker-kolom toegevoegd ------------------------------^^^^^^^^ ^^^^ VAN dbo.SpeedingTickets; -- de rest van de set-gebaseerde iteratie-oplossing bleef ongewijzigd Een andere complicatie die u kunt tegenkomen, is wanneer u niet op zoek bent naar de hele tabel, maar naar een subset (in dit geval bijvoorbeeld de eerste week van januari). U moet aanpassingen maken door
WHERE. toe te voegen clausules, en houd die predikaten in gedachten wanneer u ook gecorreleerde subquery's heeft.