[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]
In deel 3 van deze serie liet ik twee oplossingen zien om te voorkomen dat een IDENTITY . groter wordt kolom – een die je gewoon tijd kost, en een andere die IDENTITY verlaat allemaal samen. De eerste voorkomt dat je te maken krijgt met externe afhankelijkheden zoals externe sleutels, maar de laatste lost dat probleem nog steeds niet op. In dit bericht wilde ik de aanpak beschrijven die ik zou volgen als ik absoluut naar bigint moest verhuizen. , moest de uitvaltijd tot een minimum beperken en had voldoende tijd om te plannen.
Vanwege alle potentiële blokkers en de noodzaak van minimale verstoring, kan de aanpak als een beetje complex worden beschouwd, en het wordt alleen maar meer als extra exotische functies worden gebruikt (bijvoorbeeld partitionering, In-Memory OLTP of replicatie) .
Op een zeer hoog niveau is de benadering om een set schaduwtabellen te maken, waarbij alle invoegingen naar een nieuwe kopie van de tabel worden geleid (met het grotere gegevenstype), en het bestaan van de twee sets tabellen is even transparant mogelijk aan de applicatie en zijn gebruikers.
Op een meer gedetailleerd niveau zou de reeks stappen als volgt zijn:
- Maak schaduwkopieën van de tabellen, met de juiste gegevenstypen.
- Wijzig de opgeslagen procedures (of ad-hoccode) om bigint voor parameters te gebruiken. (Hierdoor kunnen wijzigingen nodig zijn die verder gaan dan de parameterlijst, zoals lokale variabelen, tijdelijke tabellen, enz., maar dit is hier niet het geval.)
- Hernoem de oude tabellen en maak weergaven met die namen die de oude en nieuwe tabellen verenigen.
- Die weergaven hebben in plaats van triggers om DML-bewerkingen op de juiste manier naar de juiste tabel(len) te leiden, zodat gegevens nog steeds kunnen worden gewijzigd tijdens de migratie.
- Hiervoor moet ook SCHEMABINDING worden verwijderd uit geïndexeerde weergaven, bestaande weergaven moeten verbindingen hebben tussen nieuwe en oude tabellen en procedures die afhankelijk zijn van SCOPE_IDENTITY() moeten worden gewijzigd.
- Migreer de oude gegevens in delen naar de nieuwe tabellen.
- Opruimen, bestaande uit:
- De tijdelijke weergaven verwijderen (waardoor de IN PLAATS VAN triggers worden verwijderd).
- De nieuwe tabellen hernoemen naar de originele namen.
- De opgeslagen procedures herstellen om terug te keren naar SCOPE_IDENTITY().
- De oude, nu lege tafels laten vallen.
- SCHEMABINDING terugzetten op geïndexeerde weergaven en opnieuw geclusterde indexen maken.
U kunt waarschijnlijk veel van de weergaven en triggers vermijden als u alle gegevenstoegang kunt regelen via opgeslagen procedures, maar aangezien dat scenario zeldzaam is (en onmogelijk 100% te vertrouwen), zal ik de moeilijkere route laten zien.
Initieel schema
Laten we aannemen dat we dit schema hebben om deze aanpak zo eenvoudig mogelijk te houden, terwijl we toch veel van de blokkers aanpakken die ik eerder in de serie noemde:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Dus een eenvoudige personeelstabel, met een geclusterde IDENTITY-kolom, een niet-geclusterde index, een berekende kolom op basis van de IDENTITY-kolom, een geïndexeerde weergave en een afzonderlijke HR/vuiltabel met een externe sleutel terug naar de personeelstabel (ik ik moedig dat ontwerp niet per se aan, ik gebruik het alleen voor dit voorbeeld). Dit zijn allemaal dingen die dit probleem ingewikkelder maken dan het zou zijn als we een op zichzelf staande, onafhankelijke tabel hadden.
Met dat schema hebben we waarschijnlijk enkele opgeslagen procedures die dingen als CRUD doen. Deze zijn meer ter documentatie dan wat dan ook; Ik ga wijzigingen aanbrengen in het onderliggende schema, zodat het wijzigen van deze procedures minimaal zou moeten zijn. Dit is om het feit te simuleren dat het wijzigen van ad-hoc SQL vanuit uw applicaties misschien niet mogelijk is, en misschien niet nodig is (nou ja, zolang u geen ORM gebruikt die tabel versus weergave kan detecteren).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Laten we nu 5 rijen met gegevens toevoegen aan de originele tabellen:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Stap 1 – nieuwe tabellen
Hier maken we een nieuw paar tabellen, waarbij de originelen worden gespiegeld, behalve het gegevenstype van de EmployeeID-kolommen, de initiële seed voor de IDENTITY-kolom en een tijdelijk achtervoegsel op de namen:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Stap 2 – procedureparameters corrigeren
De procedures hier (en mogelijk uw ad-hoccode, tenzij deze al het grotere integer-type gebruikt) zullen een zeer kleine wijziging nodig hebben, zodat ze in de toekomst EmployeeID-waarden boven de bovengrenzen van een geheel getal kunnen accepteren. Hoewel je zou kunnen beweren dat als je deze procedures gaat wijzigen, je ze gewoon naar de nieuwe tafels kunt wijzen, probeer ik te beweren dat je het uiteindelijke doel kunt bereiken met *minimale* inbreuk op de bestaande, permanente code.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Stap 3 – weergaven en triggers
Helaas kan dit niet *alles* stilzwijgend worden gedaan. We kunnen de meeste bewerkingen parallel uitvoeren zonder het gelijktijdig gebruik te beïnvloeden, maar vanwege de SCHEMABINDING moet de geïndexeerde weergave worden gewijzigd en de index later opnieuw worden gemaakt.
Dit geldt voor alle andere objecten die SCHEMABINDING gebruiken en verwijzen naar een van onze tabellen. Ik raad aan om het aan het begin van de bewerking te wijzigen in een niet-geïndexeerde weergave en de index slechts één keer opnieuw op te bouwen nadat alle gegevens zijn gemigreerd, in plaats van meerdere keren in het proces (aangezien tabellen meerdere keren worden hernoemd). Wat ik in feite ga doen, is de weergave wijzigen om de nieuwe en oude versies van de tabel Werknemers voor de duur van het proces samen te voegen.
Een ander ding dat we moeten doen, is de opgeslagen procedure Employee_Add wijzigen om tijdelijk @@IDENTITY te gebruiken in plaats van SCOPE_IDENTITY(). Dit komt omdat de INSTEAD OF-trigger die nieuwe updates voor "Werknemers" afhandelt, geen zichtbaarheid heeft van de SCOPE_IDENTITY()-waarde. Dit veronderstelt natuurlijk dat de tabellen geen after-triggers hebben die van invloed zijn op @@IDENTITY. Hopelijk kunt u deze query's wijzigen in een opgeslagen procedure (waarbij u de INSERT eenvoudig naar de nieuwe tabel kunt wijzen), of uw toepassingscode hoeft in de eerste plaats niet op SCOPE_IDENTITY() te vertrouwen.
We gaan dit doen onder SERIALIZABLE, zodat er geen transacties proberen binnen te sluipen terwijl de objecten in beweging zijn. Dit is een reeks grotendeels alleen metadata-bewerkingen, dus het zou snel moeten gaan.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Stap 4 – Migreer oude gegevens naar nieuwe tabel
We gaan gegevens in brokken migreren om de impact op zowel gelijktijdigheid als het transactielogboek te minimaliseren, waarbij we de basistechniek lenen van een oude post van mij, "Break grote verwijderingsbewerkingen in brokken." We gaan deze batches ook in SERIALIZABLE uitvoeren, wat betekent dat je voorzichtig moet zijn met de batchgrootte, en ik heb de foutafhandeling voor de beknoptheid weggelaten.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Resultaten:
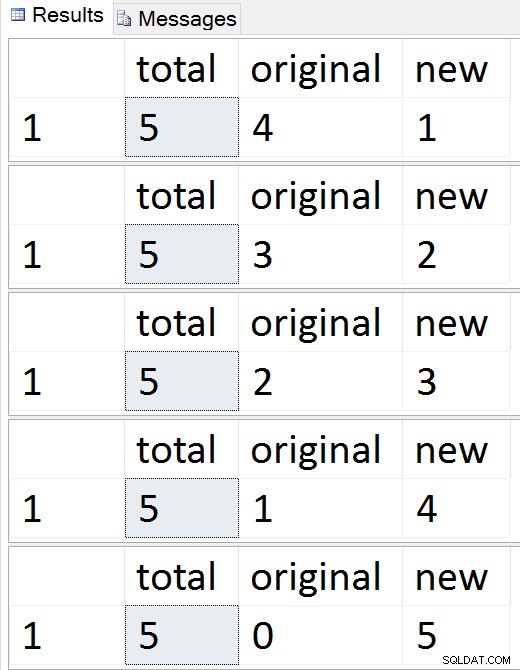 Bekijk de rijen één voor één migreren
Bekijk de rijen één voor één migreren
Op elk moment tijdens die reeks kunt u invoegingen, updates en verwijderingen testen en deze moeten op de juiste manier worden behandeld. Zodra de migratie is voltooid, kunt u doorgaan naar de rest van het proces.
Stap 5 – Opruimen
Er is een reeks stappen nodig om de objecten die tijdelijk zijn gemaakt op te schonen en om Employees / EmployeeFile te herstellen als echte, eersteklas burgers. Veel van deze commando's zijn gewoon metadatabewerkingen - met uitzondering van het maken van de geclusterde index op de geïndexeerde weergave, zouden ze allemaal onmiddellijk moeten zijn.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO Op dit punt zou alles weer normaal moeten werken, hoewel u misschien typische onderhoudsactiviteiten wilt overwegen na grote schemawijzigingen, zoals het bijwerken van statistieken, het opnieuw opbouwen van indexen of het verwijderen van plannen uit de cache.
Conclusie
Dit is een vrij complexe oplossing voor wat een eenvoudig probleem zou moeten zijn. Ik hoop dat SQL Server het op een gegeven moment mogelijk maakt om dingen te doen zoals het toevoegen/verwijderen van de IDENTITY-eigenschap, het opnieuw opbouwen van indexen met nieuwe doelgegevenstypen en het wijzigen van kolommen aan beide zijden van een relatie zonder de relatie op te offeren. In de tussentijd zou ik graag willen horen of deze oplossing je helpt, of dat je een andere aanpak hebt.
Een dikke pluim voor James Lupolt (@jlupoltsql) voor het helpen van mijn gezond verstand om mijn aanpak te controleren en het tot de ultieme test te brengen op een van zijn eigen, echte tafels. (Het ging goed. Bedankt James!)
—
[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]