Een prestatieafstemming kan uiteindelijk vele wendingen nemen terwijl u eraan werkt - het hangt allemaal af van wat het probleem is en wat de gegevens u vertellen. Op sommige dagen komt het terecht op een specifieke zoekopdracht, of een reeks zoekopdrachten, die kan worden verbeterd met indexen - nieuwe of wijzigingen aan bestaande indexen. Een van mijn favoriete onderdelen van tuning is het werken met indexen en terwijl ik aan dit bericht dacht, kwam ik in de verleiding om indextuning als een "gemakkelijkere" taak te bestempelen ... maar dat is het echt niet.
Ik beschouw index-tuning als een kunst en een wetenschap. Je moet proberen te denken als de optimizer, en je moet het tabelschema en de query (of query's) die je probeert af te stemmen begrijpen. Beide zijn datagedreven en vallen dus in de categorie wetenschap. De kunstcomponent komt om de hoek kijken als je denkt aan de andere indexen op de tafel, en alle de andere zoekopdrachten die betrekking hebben op de tabel die kan worden beïnvloed door indexwijzigingen.
Stap 1:Identificeer de vraag en bekijk het plan
Wanneer ik een zoekopdracht identificeer die baat zou kunnen hebben bij een index, krijg ik meteen het plan. Ik haal het uitvoeringsplan vaak uit de plancache of de Query Store en gebruik vervolgens SSMS om het uitvoeringsplan plus runtime-statistieken (ook bekend als het werkelijke uitvoeringsplan) te krijgen. Vaak is de vorm van die twee plannen hetzelfde; maar het is geen garantie, daarom zie ik beide graag.
Het plan kan een ontbrekende indexaanbeveling hebben, het kan een geclusterde indexscan hebben (of heap-scan als er geen geclusterde index is), het kan een niet-geclusterde index gebruiken maar vervolgens een zoekopdracht uitvoeren om extra kolommen op te halen. Elk van deze problemen afzonderlijk oplossen klinkt vrij eenvoudig. Voeg gewoon de ontbrekende index toe, toch? Als er een scan is van een geclusterde index of heap, maak dan de index die ik nodig heb voor de query en klaar? Of als er een index wordt gebruikt, maar deze gaat naar de tabel om de extra kolommen te krijgen, voegt u de kolommen gewoon aan die index toe?
Het is meestal niet zo eenvoudig, en zelfs als dat zo is, doorloop ik nog steeds het proces dat ik hier schets.
Stap 2:Bepaal welke tafel(s) u wilt bekijken
Nu ik mijn vraag heb, moet ik uitzoeken welke tabellen niet correct zijn geïndexeerd. Naast het reviewen van het plan, schakel ik ook IO- en TIME-statistieken in SSMS in. Dit is waarschijnlijk ouderwets van mij, omdat uitvoeringsplannen bij elke release steeds meer informatie bevatten - inclusief duur en IO-nummers per operator, maar ik hou van de IO-statistieken omdat ik snel de uitlezingen voor elke tabel kan zien. Voor query's die complex zijn met meerdere joins, of subquery's, of CTE's, of geneste weergaven, inzicht in waar de IO en/of tijd wordt besteed in de querydrives waar ik mijn tijd doorbreng. Waar mogelijk vanaf dit punt, neem ik de grotere, complexe query en verdeel ik deze tot het deel dat het grootste probleem veroorzaakt.
Als er bijvoorbeeld een query is die samenkomt met 10 tabellen en twee subquery's heeft, helpt het plan (samen met informatie over IO en duur) me te identificeren waar het probleem zich voordoet. Dan zal ik dat deel van de query eruit halen - de problematische tabel en misschien een paar andere waaraan het wordt toegevoegd - en me daarop concentreren. Soms is het alleen de subquery, dus begin ik daar.
Stap 3:Bekijk bestaande indexen
Met de query (of een deel van de query) gedefinieerd, concentreer ik me op de bestaande indexen voor de betrokken tabellen. Voor deze stap vertrouw ik op Kimberly's versie van sp_helpindex. Ik geef de voorkeur aan haar versie boven de standaard sp_helpindex omdat het ook INCLUDE kolommen en de filterdefinitie vermeldt (als die bestaat). Afhankelijk van het aantal indexen dat voor een tabel verschijnt, zal ik deze vaak kopiëren en in Excel plakken, en dan rangschikken op basis van de indexsleutel en vervolgens de opgenomen kolommen. Hierdoor kan ik eventuele overtolligheden snel vinden.
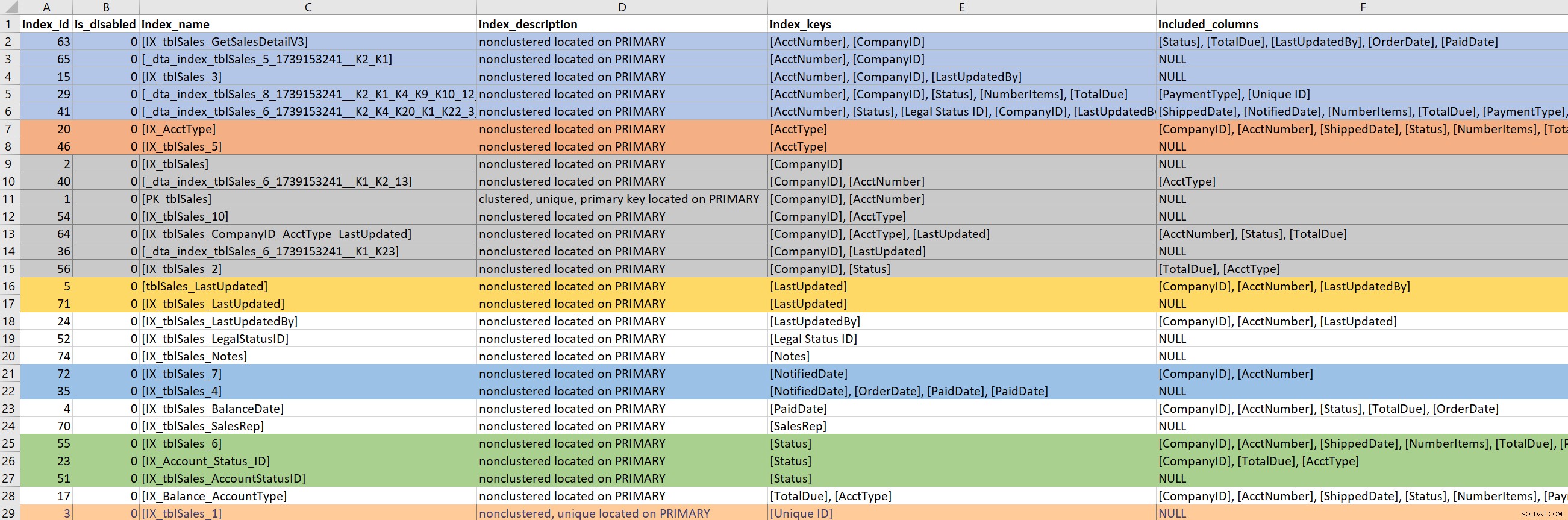
Op basis van de bovenstaande voorbeelduitvoer zijn er zeven indexen die beginnen met CompanyID, vijf die beginnen met AcctNumber en enkele andere mogelijke ontslagen. Hoewel het ideaal lijkt om er maar één . te hebben index die leidt naar een bepaalde kolom (bijv. CompanyID), voor sommige zoekpatronen is dat niet genoeg.
Als ik naar bestaande indexen kijk, is het heel gemakkelijk om door een konijnenhol te gaan. Ik kijk naar de uitvoer hierboven en begin meteen te vragen waarom er zeven indexen zijn die beginnen met CompanyID, en ik wil weten wie ze heeft gemaakt, en waarom en voor welke zoekopdracht. Maar... als mijn problematische vraag geen gebruik maakt van CompanyID, kan het mij dan schelen? Ja... want over het algemeen ben ik er om de prestaties te verbeteren, en als dat betekent dat ik onderweg naar andere indexen moet kijken, dan is dat maar zo. Maar dit is waar het gemakkelijk is om de tijd (en het ware doel) uit het oog te verliezen.
Als mijn problematische zoekopdracht een index nodig heeft die leidt naar PaidDate, heb ik maar met één bestaande index te maken. Als mijn problematische zoekopdracht een index nodig heeft die leidt op AcctNumber, wordt het lastig. Als bestaande indexen een soort van zoekopdracht dekken, en ik wil een index uitbreiden (meer kolommen toevoegen) of consolideren (twee of misschien drie indexen samenvoegen tot één), dan moet ik me erin verdiepen.
Stap 4:Gebruiksstatistieken indexeren
Ik merk dat veel mensen de statistieken van het indexgebruik niet doorlopend vastleggen. Dit is jammer, want ik vind de gegevens nuttig bij het beslissen welke indexen moeten worden bewaard en welke moeten worden verwijderd of samengevoegd. In het geval dat ik geen historische gebruiksstatistieken heb, controleer ik in ieder geval hoe het gebruik er momenteel uitziet (sinds de laatste herstart van de service):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
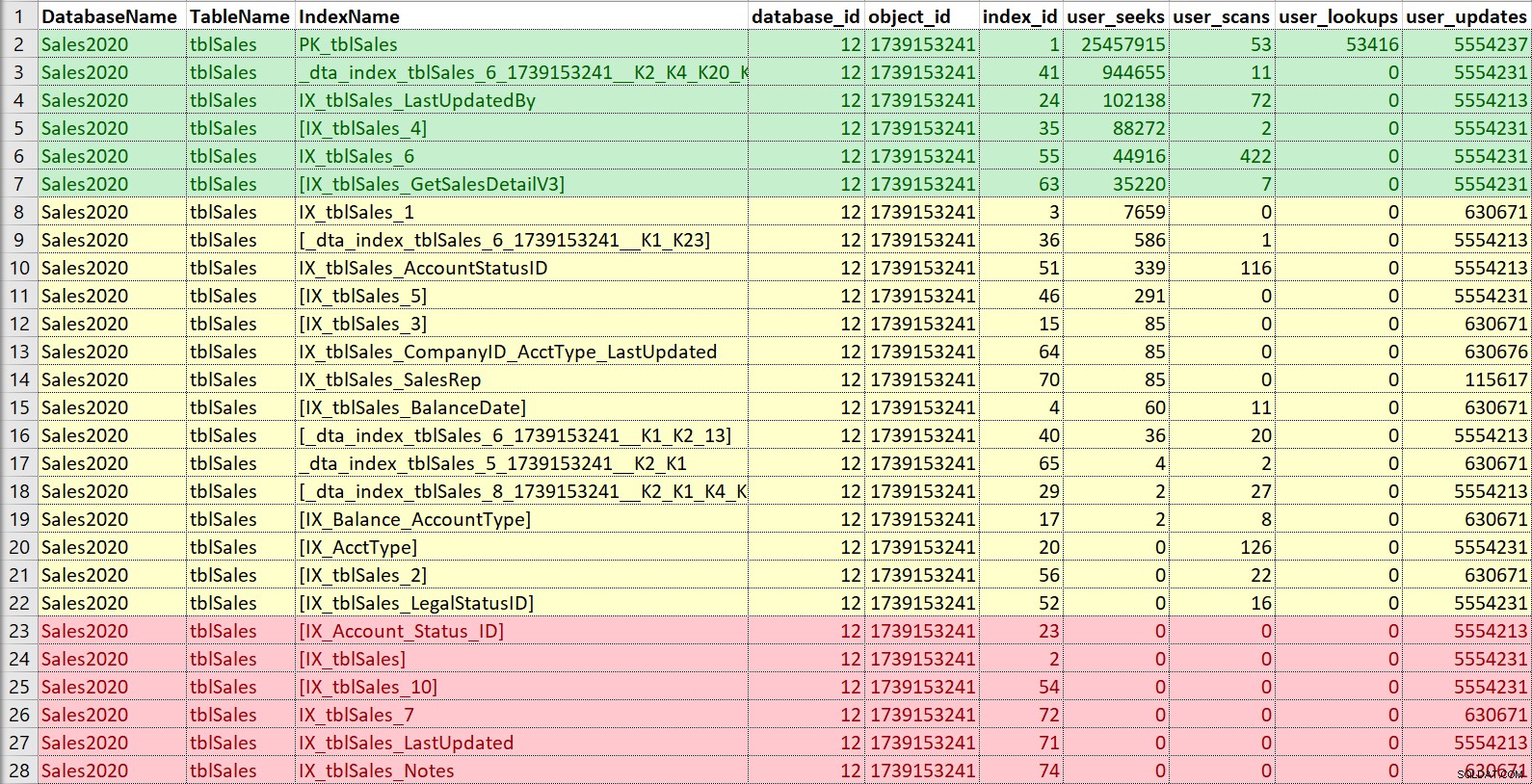
Nogmaals, ik vind het leuk om dit in Excel te zetten, te sorteren op zoeken en vervolgens te scannen, en ook kennis te nemen van updates. Voor dit voorbeeld zijn de indexen in rood die zonder zoekacties, scans of opzoekingen... alleen updates. Dat zijn kandidaten om te worden uitgeschakeld en mogelijk te laten vallen, als ze echt niet worden gebruikt (nogmaals, het hebben van een gebruiksgeschiedenis zou hier helpen). De indexen in het groen worden zeker gebruikt, ik wil die behouden (hoewel ze in sommige gevallen misschien kunnen worden aangepast). Die in het geel... sommige worden een beetje gebruikt, andere worden amper gebruikt. Nogmaals, geschiedenis zou hier nuttig zijn, of context van anderen - soms kan een index cruciaal zijn voor een rapport of proces dat niet altijd wordt uitgevoerd.
Als ik alleen op zoek ben naar het wijzigen of toevoegen van een nieuwe index, in plaats van echt opschonen en consolideren, dan houd ik me vooral bezig met indexen die lijken op wat ik wil toevoegen of wijzigen. Ik zal er echter voor zorgen dat ik de klant op de gebruiksinformatie zal wijzen en, als de tijd het toelaat, zal helpen met de algemene indexeringsstrategie voor de tafel.
Wat nu?
We zijn nog niet klaar! Dit is deel 1 van mijn benadering van indexafstemming, en mijn volgende aflevering zal de rest van mijn stappen opsommen. Als u in de tussentijd geen indexgebruiksstatistieken vastlegt, kunt u dat instellen met behulp van de bovenstaande zoekopdracht of een andere variant. Ik zou aanraden om gebruiksstatistieken vast te leggen voor alle gebruikersdatabases, niet alleen een specifieke tabel en database zoals ik hierboven heb gedaan, dus wijzig het predikaat indien nodig. En tot slot, als onderdeel van die geplande taak om die informatie naar een tabel te snappen, vergeet niet nog een stap om de tabel op te schonen nadat de gegevens er al een tijdje zijn (ik bewaar ze minstens zes maanden; sommigen zeggen misschien een jaar is noodzakelijk).