In een recente tip beschreef ik een scenario waarin een SQL Server 2016-instantie leek te worstelen met checkpointtijden. Het foutenlogboek werd gevuld met een alarmerend aantal FlushCache-vermeldingen zoals deze:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Ik was een beetje verbijsterd door dit probleem, aangezien het systeem zeker niet traag was - veel kernen, 3 TB geheugen en XtremIO-opslag. En geen van deze FlushCache-berichten is ooit gekoppeld aan de veelbetekenende 15 seconden I/O-waarschuwingen in het foutenlogboek. Maar als je daar een heleboel databases met veel transacties op stapelt, kan de verwerking van checkpoints behoorlijk traag worden. Niet zozeer vanwege de directe I/O, maar meer afstemming die moet worden gedaan met een enorm aantal vuile pagina's (niet alleen van toegewijde transacties) verspreid over zo'n grote hoeveelheid geheugen en mogelijk wachtend op de luie schrijver (omdat er maar één is voor de hele instantie).
Ik heb een aantal zeer waardevolle berichten snel "opgefrist":
- Hoe werken checkpoints en wat wordt er gelogd?
- Databasecontrolepunten (SQL-server)
- Wat doet checkpoint voor tempdb?
- Een SQL Server DBA-mythe per dag:(15/30) checkpoint schrijft alleen pagina's van vastgelegde transacties
- FlushCache-berichten zijn mogelijk geen echte IO-blokkade
- Indirect Checkpoint en tempdb – de goede, de slechte en de niet-renderende planner
- De doelhersteltijd van een database wijzigen
- Hoe het werkt:wanneer wordt het FlushCache-bericht toegevoegd aan het SQL Server-foutlogboek?
- Wijzigingen in het gedrag van SQL Server 2016 Checkpoint
- Target Recovery Interval en indirect checkpoint – nieuwe standaard van 60 seconden in SQL Server 2016
- SQL 2016 – Het werkt gewoon sneller:Indirect Checkpoint Standaard
- SQL-server:groot RAM- en DB-controlepunt
Ik besloot al snel dat ik de duur van de checkpoints wilde bijhouden voor een paar van deze meer lastige databases, voor en na het wijzigen van hun doelherstelinterval van 0 (de oude manier) in 60 seconden (de nieuwe manier). In januari leende ik een Extended Events-sessie van een vriendin en mede-Canadese Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Ik markeerde de tijd dat ik elke database veranderde en analyseerde vervolgens de resultaten van de Extended Events-gegevens met behulp van een query die in de oorspronkelijke tip was gepubliceerd. De resultaten toonden aan dat na de overstap naar indirecte checkpoints, elke database ging van checkpoints van gemiddeld 30 seconden naar checkpoints van gemiddeld minder dan een tiende van een seconde (en in de meeste gevallen ook veel minder checkpoints). Er valt veel uit deze afbeelding te halen, maar dit zijn de ruwe gegevens die ik heb gebruikt om mijn argument te presenteren (klik om te vergroten):
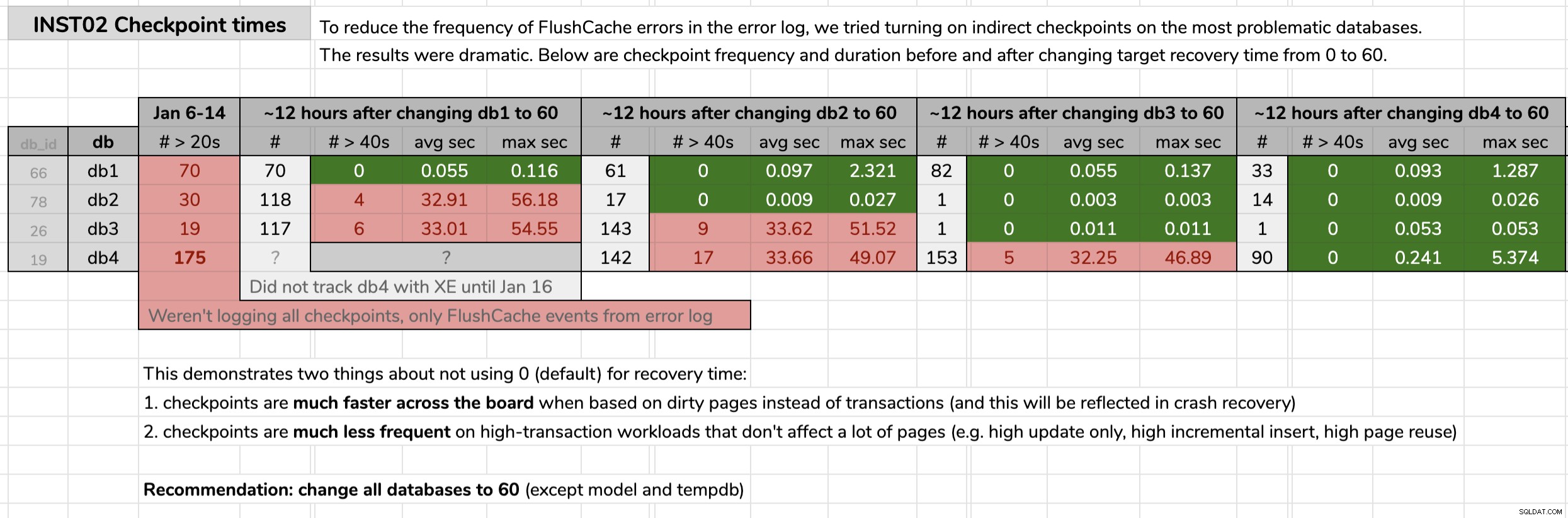 Mijn bewijs
Mijn bewijs
Toen ik mijn zaak in deze problematische databases eenmaal had bewezen, kreeg ik groen licht om dit in al onze gebruikersdatabases in onze omgeving te implementeren. Eerst in dev en daarna in productie, heb ik het volgende uitgevoerd via een CMS-query om een indicatie te krijgen van het aantal databases waar we het over hadden:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Enkele opmerkingen over de zoekopdracht:
database_id > 4
Ik wildemasterniet aanraken helemaal niet, en ik wildetempdbniet veranderen maar omdat we niet de nieuwste SQL Server 2017 CU gebruiken (zie KB #4497928 om een reden dat details belangrijk zijn). Dit laatste sluitmodeluit , ook omdat het veranderen van het model invloed zou hebben optempdbbij de volgende failover/herstart. Ik hadmsdbkunnen veranderen , en misschien ga ik dat ooit nog eens doen, maar mijn focus lag hier op gebruikersdatabases.
[state] / is_read_only / is_in_standby
We moeten ervoor zorgen dat de databases die we proberen te wijzigen, online zijn en niet alleen-lezen (ik heb er een gevonden die momenteel was ingesteld op alleen-lezen, en zal daar later op terug moeten komen).
>OUTER APPLY (...)
We willen onze acties beperken tot databases die ofwel de primaire in een AG zijn of helemaal niet in een AG (en ook rekening moeten houden met gedistribueerde AG's, waar we primair en lokaal kunnen zijn maar nog steeds niet beschrijfbaar zijn) . Als je toevallig de controle op een secundair uitvoert, kun je het probleem daar niet oplossen, maar je zou er nog steeds een waarschuwing over moeten krijgen. Dank aan Erik Darling voor het helpen met deze logica, en Taylor Martell voor het motiveren van verbeteringen.
- Als je instances hebt met oudere versies zoals SQL Server 2008 R2 (ik heb er een gevonden!), moet je dit een beetje aanpassen, aangezien de
target_recovery_time_in_secondskolom bestaat daar niet. Ik moest dynamische SQL gebruiken om dit in één geval te omzeilen, maar je zou ook tijdelijk kunnen verplaatsen of verwijderen waar die instanties in je CMS-hiërarchie vallen. Je zou ook niet lui kunnen zijn zoals ik, en de code in Powershell uitvoeren in plaats van een CMS-queryvenster, waar je databases met een willekeurig aantal eigenschappen gemakkelijk kunt filteren voordat je ooit problemen krijgt met compileren.
In productie waren er 102 exemplaren (ongeveer de helft) en in totaal 1.590 databases die de oude instelling gebruikten. Alles stond op SQL Server 2017, dus waarom was deze instelling zo wijdverbreid? Omdat ze zijn gemaakt voordat indirecte controlepunten de standaard werden in SQL Server 2016. Hier is een voorbeeld van de resultaten:
 Gedeeltelijke resultaten van CMS-query.
Gedeeltelijke resultaten van CMS-query.
Daarna heb ik de CMS-query opnieuw uitgevoerd, deze keer met sys.sp_executesql onbecommentarieerd. Het duurde ongeveer 12 minuten om dat in alle 1.590 databases uit te voeren. Binnen het uur kreeg ik al meldingen van mensen die een significante daling van de CPU zagen op sommige van de drukkere instanties.
Ik heb nog meer te doen. Ik moet bijvoorbeeld de potentiële impact op tempdb . testen , en of er enig gewicht is in onze use-case voor de horrorverhalen die ik heb gehoord. En we moeten ervoor zorgen dat de 60 seconden-instelling deel uitmaakt van onze automatisering en alle verzoeken om databases te maken, vooral die welke zijn gescript of hersteld vanaf back-ups.