UPDATE:2 september 2021 (Oorspronkelijk gepubliceerd op 26 juli 2012.)
Veel dingen veranderen in de loop van een paar grote versies van ons favoriete databaseplatform. SQL Server 2016 bracht ons STRING_SPLIT, een native functie die de noodzaak voor veel van de aangepaste oplossingen die we eerder nodig hadden, overbodig maakt. Het is ook snel, maar het is niet perfect. Het ondersteunt bijvoorbeeld alleen een scheidingsteken van één teken en het retourneert niets om de volgorde van de invoerelementen aan te geven. Ik heb verschillende artikelen geschreven over deze functie (en STRING_AGG, die in SQL Server 2017 is aangekomen) sinds dit bericht is geschreven:
- Prestatieverrassingen en aannames:STRING_SPLIT()
- STRING_SPLIT() in SQL Server 2016:follow-up #1
- STRING_SPLIT() in SQL Server 2016:follow-up #2
- SQL Server Split String-vervangingscode met STRING_SPLIT
- Het vergelijken van methoden voor het splitsen / samenvoegen van tekenreeksen
- Oude problemen oplossen met de nieuwe STRING_AGG- en STRING_SPLIT-functies van SQL Server
- Omgaan met het scheidingsteken van één teken in de STRING_SPLIT-functie van SQL Server
- Help met STRING_SPLIT verbeteringen
- Een manier om STRING_SPLIT in SQL Server te verbeteren – en jij kunt helpen
Ik ga de onderstaande inhoud hier achterlaten voor het nageslacht en historische relevantie, en ook omdat een deel van de testmethodologie relevant is voor andere problemen, afgezien van het splitsen van strings, maar bekijk enkele van de bovenstaande referenties voor informatie over hoe je zou moeten splitsen strings in moderne, ondersteunde versies van SQL Server - evenals dit bericht, waarin wordt uitgelegd waarom het splitsen van strings misschien geen probleem is dat je wilt dat de database in de eerste plaats oplost, nieuwe functie of niet.
- Snaren splitsen:nu met minder T-SQL
Ik weet dat veel mensen zich vervelen van het "split strings"-probleem, maar het lijkt nog steeds bijna dagelijks voor te komen op forum- en vraag- en antwoordsites zoals Stack Overflow. Dit is het probleem waarbij mensen een string als deze willen doorgeven:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Binnen de procedure willen ze zoiets als dit doen:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Dit werkt niet omdat @FavoriteTeams een enkele string is, en het bovenstaande vertaalt zich in:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server gaat daarom proberen een team te vinden met de naam Patriots,Red Sox,Bruins , en ik gok dat er niet zo'n team is. Wat ze hier echt willen is het equivalent van:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Maar aangezien er geen arraytype is in SQL Server, is dit helemaal niet hoe de variabele wordt geïnterpreteerd - het is nog steeds een eenvoudige, enkele tekenreeks die toevallig enkele komma's bevat. Afgezien van het twijfelachtige schemaontwerp, moet in dit geval de door komma's gescheiden lijst worden "gesplitst" in individuele waarden - en dit is de vraag die vaak aanleiding geeft tot veel "nieuw" debat en commentaar over de beste oplossing om precies dat te bereiken.
Het antwoord lijkt bijna altijd te zijn dat u CLR moet gebruiken. Als je CLR niet kunt gebruiken - en ik weet dat er velen van jullie zijn die dat niet kunnen, vanwege het bedrijfsbeleid, de puntige baas of koppigheid - dan gebruik je een van de vele tijdelijke oplossingen die er zijn. En er zijn veel oplossingen.
Maar welke moet je gebruiken?
Ik ga de prestaties van een paar oplossingen vergelijken - en me concentreren op de vraag die iedereen altijd stelt:"Wat is het snelst?" Ik ga de discussie over *alle* mogelijke methoden niet uitweiden, omdat er al verschillende zijn geëlimineerd vanwege het feit dat ze eenvoudigweg niet schalen. En ik zal dit in de toekomst misschien opnieuw bezoeken om de impact op andere statistieken te onderzoeken, maar voor nu ga ik me alleen concentreren op de duur. Dit zijn de kanshebbers die ik ga vergelijken (met SQL Server 2012, 11.00.2316, op een Windows 7 VM met 4 CPU's en 8 GB RAM):
CLR
Als je CLR wilt gebruiken, moet je zeker code lenen van collega MVP Adam Machanic voordat je erover denkt om je eigen te schrijven (ik heb eerder geblogd over het opnieuw uitvinden van het wiel, en het is ook van toepassing op gratis codefragmenten zoals deze). Hij besteedde veel tijd aan het verfijnen van deze CLR-functie om een string efficiënt te ontleden. Als u momenteel een CLR-functie gebruikt en dit is het niet, raad ik u ten zeerste aan deze in te zetten en te vergelijken - ik heb het getest met een veel eenvoudigere, op VB gebaseerde CLR-routine die functioneel equivalent was, maar de VB-benadering presteerde ongeveer drie keer slechter dan die van Adam.
Dus nam ik de functie van Adam, compileerde de code naar een DLL (met behulp van csc) en implementeerde alleen dat bestand op de server. Daarna heb ik de volgende assembly en functie aan mijn database toegevoegd:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Dit is de typische functie die ik gebruik voor eenmalige scenario's waarbij ik weet dat de invoer "veilig" is, maar die ik niet aanbeveel voor productieomgevingen (daarover hieronder meer).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Een zeer sterke waarschuwing moet meegaan met de XML-aanpak:het kan alleen worden gebruikt als u kunt garanderen dat uw invoerstring geen illegale XML-tekens bevat. Eén naam met <,> of &en de functie ontploft. Dus ongeacht de prestaties, als je deze aanpak gaat gebruiken, houd dan rekening met de beperkingen - het moet niet worden beschouwd als een haalbare optie voor een generieke stringsplitter. Ik neem het op in deze samenvatting omdat je misschien een geval hebt waarin je kunt vertrouw de invoer - het is bijvoorbeeld mogelijk om te gebruiken voor door komma's gescheiden lijsten met gehele getallen of GUID's.
Getallentabel
Deze oplossing maakt gebruik van een Numbers-tabel, die u zelf moet bouwen en invullen. (We vragen al tijden om een ingebouwde versie.) De Numbers-tabel zou genoeg rijen moeten bevatten om de lengte van de langste string die je gaat splitsen te overschrijden. In dit geval gebruiken we 1.000.000 rijen:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Het gebruik van gegevenscompressie zal het aantal vereiste pagina's drastisch verminderen, maar u moet deze optie uiteraard alleen gebruiken als u Enterprise Edition gebruikt. In dit geval vereist de gecomprimeerde gegevens 1360 pagina's, tegenover 2102 pagina's zonder compressie - ongeveer een besparing van 35%. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Algemene tabeluitdrukking
Deze oplossing gebruikt een recursieve CTE om elk deel van de string uit de "rest" van het vorige deel te extraheren. Als recursieve CTE met lokale variabelen zul je merken dat dit een functie met meerdere instructies moest zijn, in tegenstelling tot de andere die allemaal inline zijn.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
De splitter van Jeff Moden Een functie gebaseerd op de splitter van Jeff Moden met kleine wijzigingen om langere strings te ondersteunen
Op SQLServerCentral presenteerde Jeff Moden een splitsfunctie die wedijverde met de prestaties van CLR, dus ik dacht dat het alleen maar eerlijk was om een variatie op te nemen met een vergelijkbare benadering in deze samenvatting. Ik moest een paar kleine wijzigingen in zijn functie aanbrengen om onze langste reeks (500.000 tekens) te kunnen verwerken, en maakte ook de naamgevingsconventies vergelijkbaar:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Even terzijde, voor degenen die de oplossing van Jeff Moden gebruiken, zou je kunnen overwegen om een Numbers-tabel te gebruiken zoals hierboven, en te experimenteren met een kleine variatie op de functie van Jeff:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Hiermee worden iets hogere waarden ingeruild voor een iets lagere CPU, dus het kan beter zijn, afhankelijk van of uw systeem al CPU- of I/O-gebonden is.)
Gezondheidscontrole
Om er zeker van te zijn dat we op de goede weg zijn, kunnen we verifiëren dat alle vijf de functies de verwachte resultaten opleveren:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
En in feite zijn dit de resultaten die we in alle vijf de gevallen zien...

De testgegevens
Nu we weten dat de functies zich gedragen zoals verwacht, kunnen we naar het leuke gedeelte gaan:de prestaties testen met verschillende aantallen strings die in lengte variëren. Maar eerst hebben we een tafel nodig. Ik heb het volgende eenvoudige object gemaakt:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Ik heb deze tabel gevuld met een reeks tekenreeksen van verschillende lengtes, om ervoor te zorgen dat ongeveer dezelfde gegevensset voor elke test zou worden gebruikt - eerst 10.000 rijen met een tekenreeks van 50 tekens en vervolgens 1.000 rijen met een tekenreeks van 500 tekens , 100 rijen waar de tekenreeks 5.000 tekens lang is, 10 rijen waar de tekenreeks 50.000 tekens lang is, enzovoort tot 1 rij van 500.000 tekens. Ik deed dit zowel om dezelfde hoeveelheid algemene gegevens die door de functies worden verwerkt te vergelijken, als om te proberen mijn testtijden enigszins voorspelbaar te houden.
Ik gebruik een #temp-tabel zodat ik eenvoudig GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Het maken en vullen van deze tabel duurde ongeveer 20 seconden op mijn computer, en de tabel vertegenwoordigt ongeveer 6 MB aan gegevens (ongeveer 500.000 tekens maal 2 bytes, of 1 MB per string_type, plus rij- en indexoverhead). Geen enorme tabel, maar hij moet groot genoeg zijn om eventuele verschillen in prestatie tussen de functies te benadrukken.
De testen
Met de functies op hun plaats en de tafel goed gevuld met grote snaren om op te kauwen, kunnen we eindelijk een aantal echte tests uitvoeren om te zien hoe de verschillende functies presteren ten opzichte van echte gegevens. Om de prestaties te meten zonder rekening te houden met netwerkoverhead, gebruikte ik SQL Sentry Plan Explorer, waarbij ik elke reeks tests 10 keer uitvoerde, de duurstatistieken verzamelde en het gemiddelde nam.
De eerste test trok eenvoudigweg de items uit elke reeks als een set:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
De resultaten laten zien dat naarmate de snaren groter worden, het voordeel van CLR echt schittert. Aan de onderkant waren de resultaten gemengd, maar nogmaals, de XML-methode zou een asterisk moeten hebben ernaast, omdat het gebruik ervan afhangt van het vertrouwen op XML-veilige invoer. Voor dit specifieke geval presteerde de Numbers-tabel consequent het slechtst:
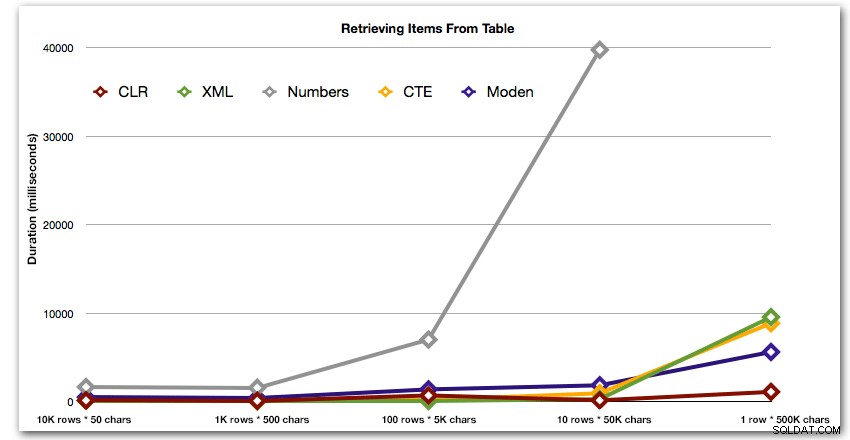
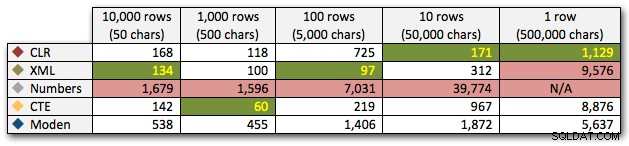
Duur, in milliseconden
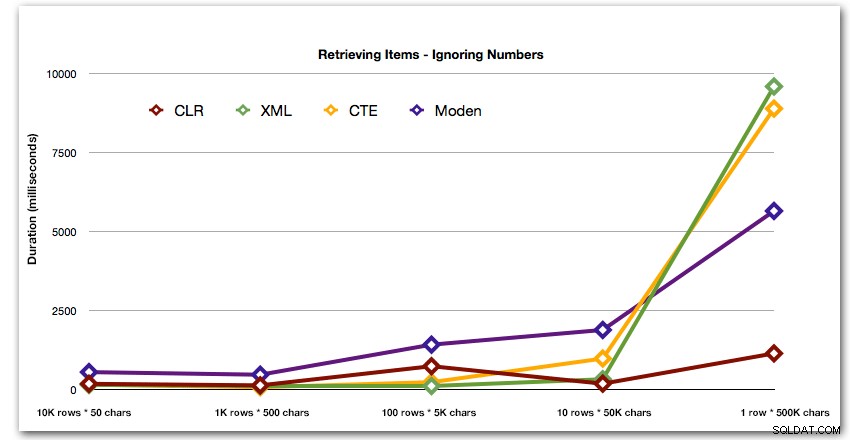
Na de hyperbolische prestatie van 40 seconden voor de getallentabel tegen 10 rijen van 50.000 tekens, liet ik het voor de laatste test vallen. Om de relatieve prestaties van de vier beste methoden in deze test beter te laten zien, heb ik de Numbers-resultaten helemaal uit de grafiek verwijderd:
Laten we vervolgens vergelijken wanneer we een zoekopdracht uitvoeren met de door komma's gescheiden waarde (bijv. de rijen retourneren waar een van de tekenreeksen 'foo' is). We gebruiken opnieuw de vijf bovenstaande functies, maar we zullen het resultaat ook vergelijken met een zoekopdracht die tijdens runtime is uitgevoerd met LIKE in plaats van ons bezig te houden met splitsen.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Deze resultaten laten zien dat CLR voor kleine strings eigenlijk de langzaamste was, en dat de beste oplossing het uitvoeren van een scan met LIKE is, zonder de moeite te nemen om de gegevens op te splitsen. Opnieuw liet ik de Numbers-tabeloplossing uit de 5e benadering vallen, toen het duidelijk was dat de duur ervan exponentieel zou toenemen naarmate de string groter werd:
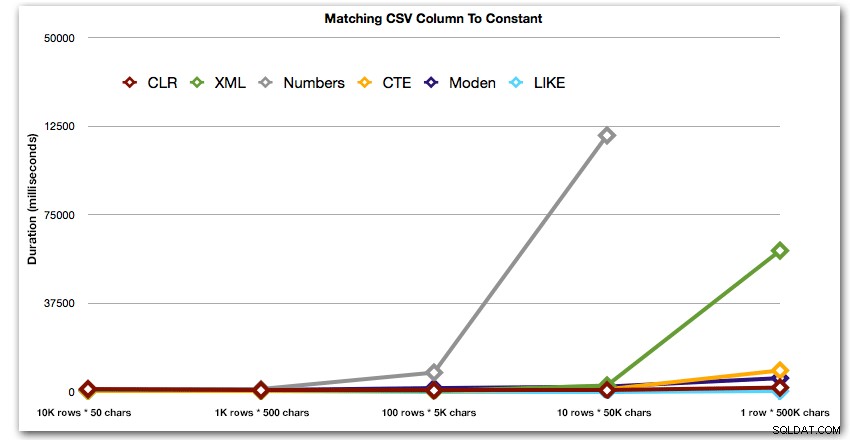
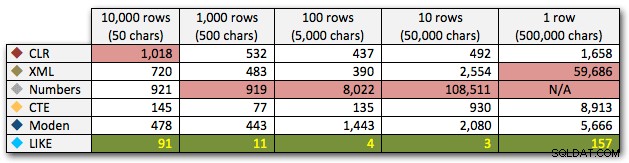
Duur, in milliseconden
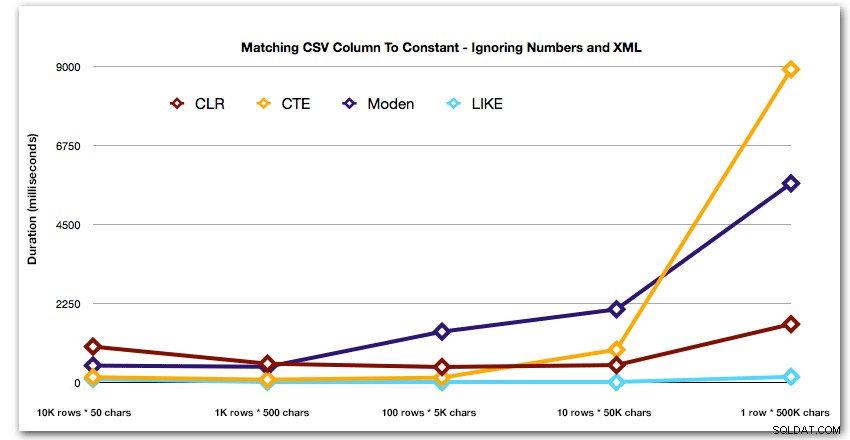
En om de patronen voor de top 4 resultaten beter te demonstreren, heb ik de Numbers- en XML-oplossingen uit de grafiek verwijderd:
Laten we vervolgens kijken naar het repliceren van de use-case vanaf het begin van dit bericht, waar we proberen alle rijen in één tabel te vinden die bestaan in de lijst die wordt doorgegeven. Net als bij de gegevens in de tabel die we hierboven hebben gemaakt, hebben we ga strings maken die in lengte variëren van 50 tot 500.000 karakters, ze opslaan in een variabele en dan een gemeenschappelijke catalogusweergave controleren op bestaande in de lijst.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Deze resultaten laten zien dat, voor dit patroon, verschillende methoden hun duur exponentieel zien toenemen naarmate de tekenreeks groter wordt. Aan de onderkant houdt XML goed gelijke tred met CLR, maar dit verslechtert ook snel. CLR is hier consequent de duidelijke winnaar:
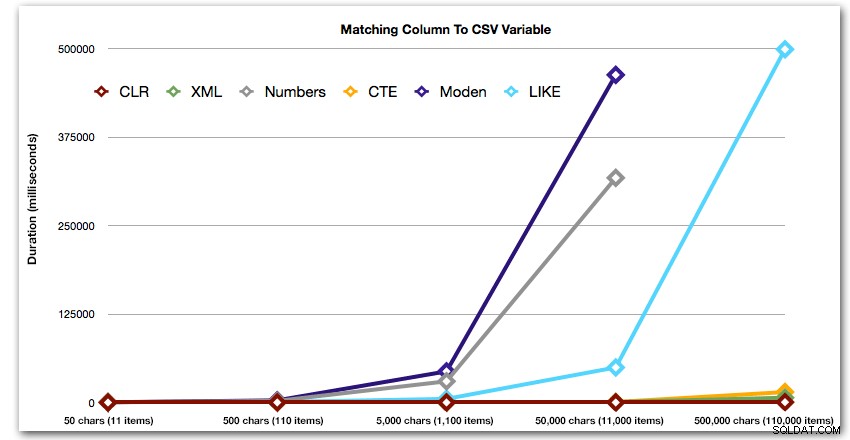
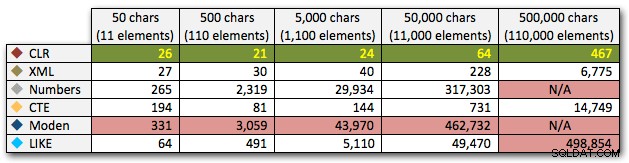
Duur, in milliseconden
En opnieuw zonder de methoden die in termen van duur exploderen:
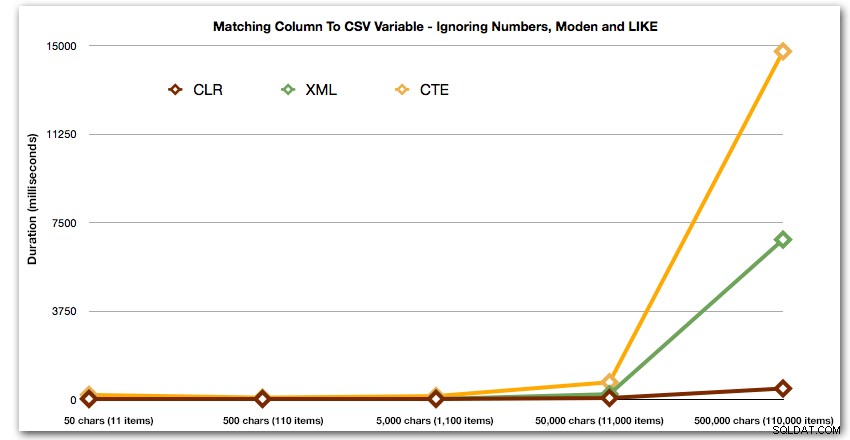
Laten we tot slot de kosten vergelijken van het ophalen van de gegevens uit een enkele variabele van verschillende lengte, waarbij we de kosten van het lezen van gegevens uit een tabel negeren. We genereren opnieuw strings van verschillende lengtes, van 50 – 500.000 karakters, en retourneren de waarden dan gewoon als een set:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Deze resultaten laten ook zien dat CLR vrij vlak is in termen van duur, tot 110.000 items in de set, terwijl de andere methoden een behoorlijk tempo aanhouden tot enige tijd na 11.000 items:
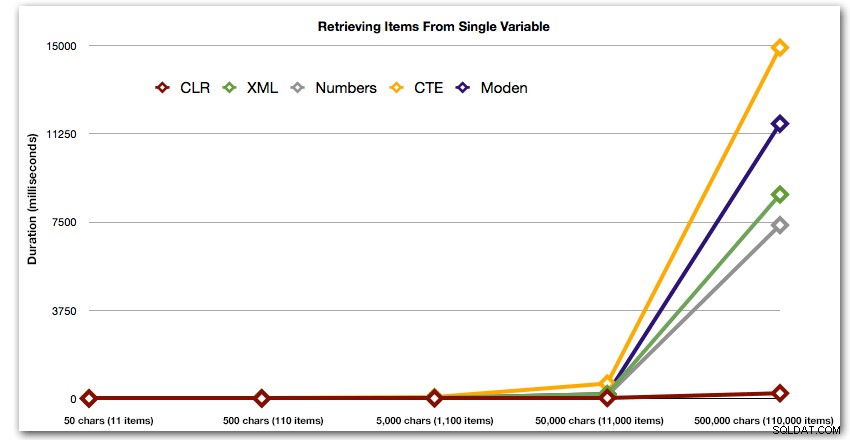
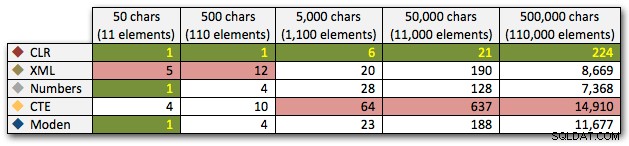
Duur, in milliseconden
Conclusie
In bijna alle gevallen presteert de CLR-oplossing duidelijk beter dan de andere benaderingen - in sommige gevallen is het een overweldigende overwinning, vooral als de snaarmaten groter worden; in een paar andere is het een fotofinish die beide kanten op kan vallen. In de eerste test zagen we dat XML en CTE beter presteerden dan CLR aan de lage kant, dus als dit een typische use-case is * en * u zeker weet dat uw strings in het bereik van 1 - 10.000 tekens liggen, kan een van die benaderingen een betere optie zijn. Als je stringgroottes minder voorspelbaar zijn, is CLR waarschijnlijk nog steeds je beste gok in het algemeen - je verliest een paar milliseconden aan de lage kant, maar je wint heel veel aan de hoge kant. Dit zijn de keuzes die ik zou maken, afhankelijk van de taak, met de tweede plaats gemarkeerd voor gevallen waarin CLR geen optie is. Merk op dat XML alleen mijn voorkeursmethode is als ik weet dat de invoer XML-veilig is; dit zijn misschien niet per se je beste alternatieven als je minder vertrouwen hebt in je inbreng.
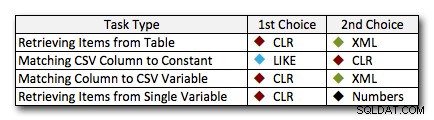
De enige echte uitzondering waarbij CLR niet mijn keuze over de hele linie is, is het geval waarin je door komma's gescheiden lijsten in een tabel opslaat en vervolgens rijen vindt waar een gedefinieerde entiteit in die lijst staat. In dat specifieke geval zou ik waarschijnlijk eerst aanraden om het schema opnieuw te ontwerpen en correct te normaliseren, zodat die waarden afzonderlijk worden opgeslagen, in plaats van het te gebruiken als een excuus om CLR niet te gebruiken voor splitsing.
Als u CLR om andere redenen niet kunt gebruiken, is er geen duidelijke "tweede plaats" die door deze tests wordt onthuld; mijn antwoorden hierboven waren gebaseerd op de totale schaal en niet op een specifieke tekenreeksgrootte. Elke oplossing hier was tweede in ten minste één scenario - dus hoewel CLR duidelijk de keuze is wanneer je het kunt gebruiken, wat je zou moeten gebruiken als je dat niet kunt, is meer een "het hangt ervan af"-antwoord - je moet beoordelen op basis van uw use case(s) en de bovenstaande tests (of door uw eigen tests te construeren) welk alternatief het beste voor u is.
Addendum:een alternatief voor splitsen in de eerste plaats
De bovenstaande benaderingen vereisen geen wijzigingen aan uw bestaande toepassing(en), ervan uitgaande dat ze al een door komma's gescheiden tekenreeks samenstellen en deze naar de database gooien om ermee om te gaan. Een optie die u zou moeten overwegen, als een van beide CLR geen optie is en/of u de toepassing(en) kunt wijzigen, is het gebruik van Table-Valued Parameters (TVP's). Hier is een snel voorbeeld van het gebruik van een TVP in de bovenstaande context. Maak eerst een tabeltype met een enkele tekenreekskolom:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Dan kan de opgeslagen procedure deze TVP als invoer nemen en meedoen met de inhoud (of op andere manieren gebruiken - dit is slechts één voorbeeld):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Nu in uw C#-code, bijvoorbeeld, in plaats van een door komma's gescheiden tekenreeks te maken, een gegevenstabel te vullen (of een compatibele verzameling te gebruiken die uw set waarden al zou kunnen bevatten):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Je zou dit kunnen beschouwen als een prequel op een vervolgbericht.
Natuurlijk gaat dit niet goed samen met JSON en andere API's - in de eerste plaats is dit vaak de reden dat een door komma's gescheiden tekenreeks wordt doorgegeven aan SQL Server.