Nou, het analyseren van de verspreiding van het SARS-CoV-2 coronavirus was niet mijn droom use case . Maar op basis van de reacties op Ferry Djaja's Tracking Coronavirus COVID-19 Near Real Time with SAP HANA XSA-artikel besloot ik mijn twee groszy ook toe te voegen.
[Bijgewerkt op 30-03-20 met de gewijzigde links naar de brongegevens; en de nieuwe kaartuitvoer op basis van de nieuwe gegevensgranulariteit. Bedankt Douglas Maltby voor je reactie!]
In zijn blogpost gebruikte Ferry JavaScript in SAP HANA XSA om de gegevens uit CSV-bestanden te halen die dagelijks door de Johns Hopkins University worden bijgewerkt.
Ik wil u graag laten zien hoe u met slechts een paar regels code deze bestanden kunt ophalen en in SAP HANA kunt laden dankzij SAP HANA Python Client API voor Machine Learning (hana_ml pakket).
Sommige mensen waren aan het eind in de war met de visualisatie op de kaart - houd er rekening mee dat dit artikel zich richt op technische use-cases die verschillende componenten verbinden, niet op het doen van diepgaande analyse van coronavirusgegevens.
Python-omgeving ophalen, b.v. Jupiter
Ik zal daarvoor Jupyter in de Docker-container gebruiken. Kijk eens naar mijn vorige bericht Containers begrijpen (deel 05):gedeelde bestanden tussen de host en containers als je niet weet hoe je ermee moet beginnen. Je kunt ook dezelfde stappen hieronder uitvoeren vanuit elke andere Python-omgeving.
Dus ik heb mijn container myjupyter01 rennen. Ik ben verbonden met de Jupyter UI zoals beschreven in de vorige blog.
Installeer hana_ml
De Jupyter-image die ik gebruikte uit het Docker Hub-register was jupyter/minimal-notebook . Het bevat al enkele populaire gegevensverwerkingspakketten, zoals pandas .
Maar daarnaast moet ik hana_ml . installeren , die — in de huidige versie 1.0.8 — beschikbaar is in de PyPI-repository:https://pypi.org/project/hana-ml/.
Het commando om de installatie uit te voeren is python -m pip install hana_ml , maar omdat ik het vanuit Jupyter-notebook met Python3-kernel gebruik, moet ik het uitvoeren met ! aan het begin:
!python -m pip install hana_ml
Het is duidelijk dat deze installatiestap maar één keer hoeft te worden uitgevoerd. Het is niet nodig om het opnieuw in dezelfde container uit te voeren, b.v. bij het herladen van de nieuwste bestanden.
Gebruik pandas om bestanden met gegevens te importeren
Laten we dezelfde drie bestanden importeren (confirmed , deaths , recovered ) van https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series zoals Ferry in zijn voorbeeld gebruikte.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
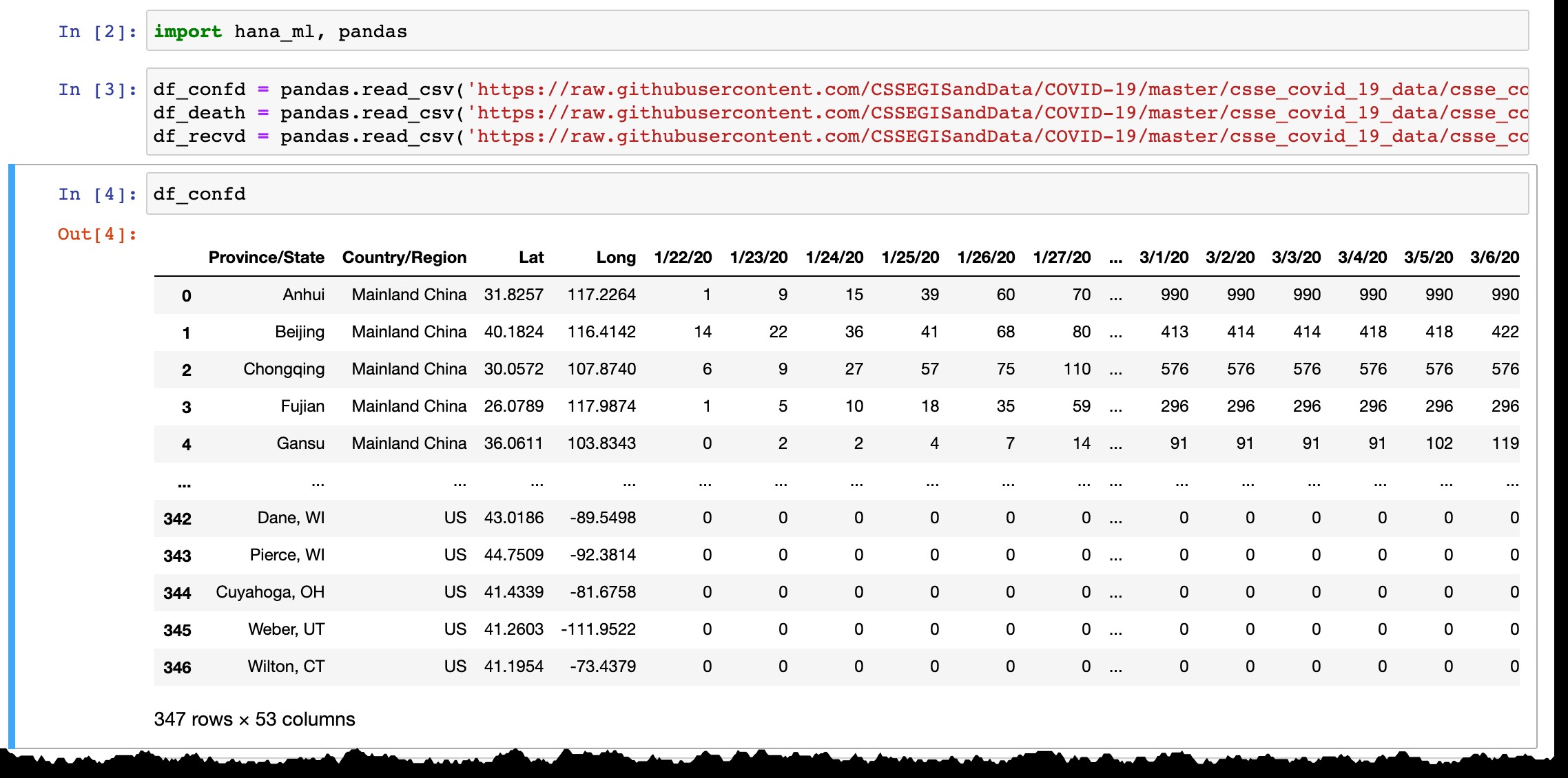
Zoals je kunt zien aan de preview van het Pandas-dataframe, worden alleen landen of provincies met bevestigde gevallen weergegeven, en elke dag wordt de nieuwe kolom toegevoegd met de laatste gegevens van de vorige dag. Regels worden toegevoegd wanneer de eerste case(s) is/zijn bevestigd in de nieuwe regio.
Gebruik pandas om het dataframe opnieuw te formatteren
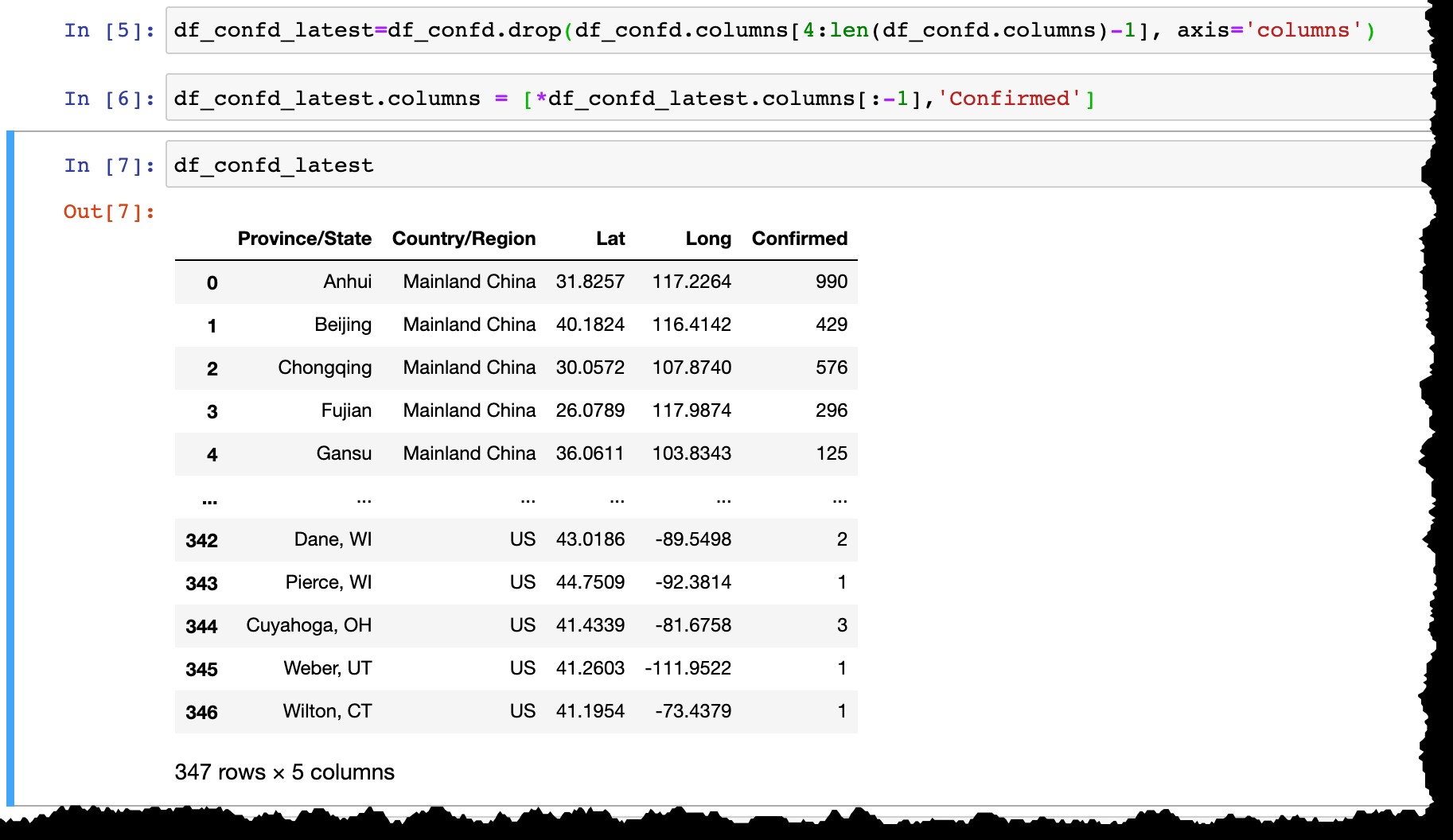
Laten we, voordat we de gegevens in SAP HANA bewaren:
- Verwijder alle datumkolommen behalve de laatste,
- Hernoem de laatste kolom vanaf de huidige datum (zoals de
3/10/20van vandaag naarConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Gebruik hana_ml om gegevens in SAP HANA-tabel te behouden
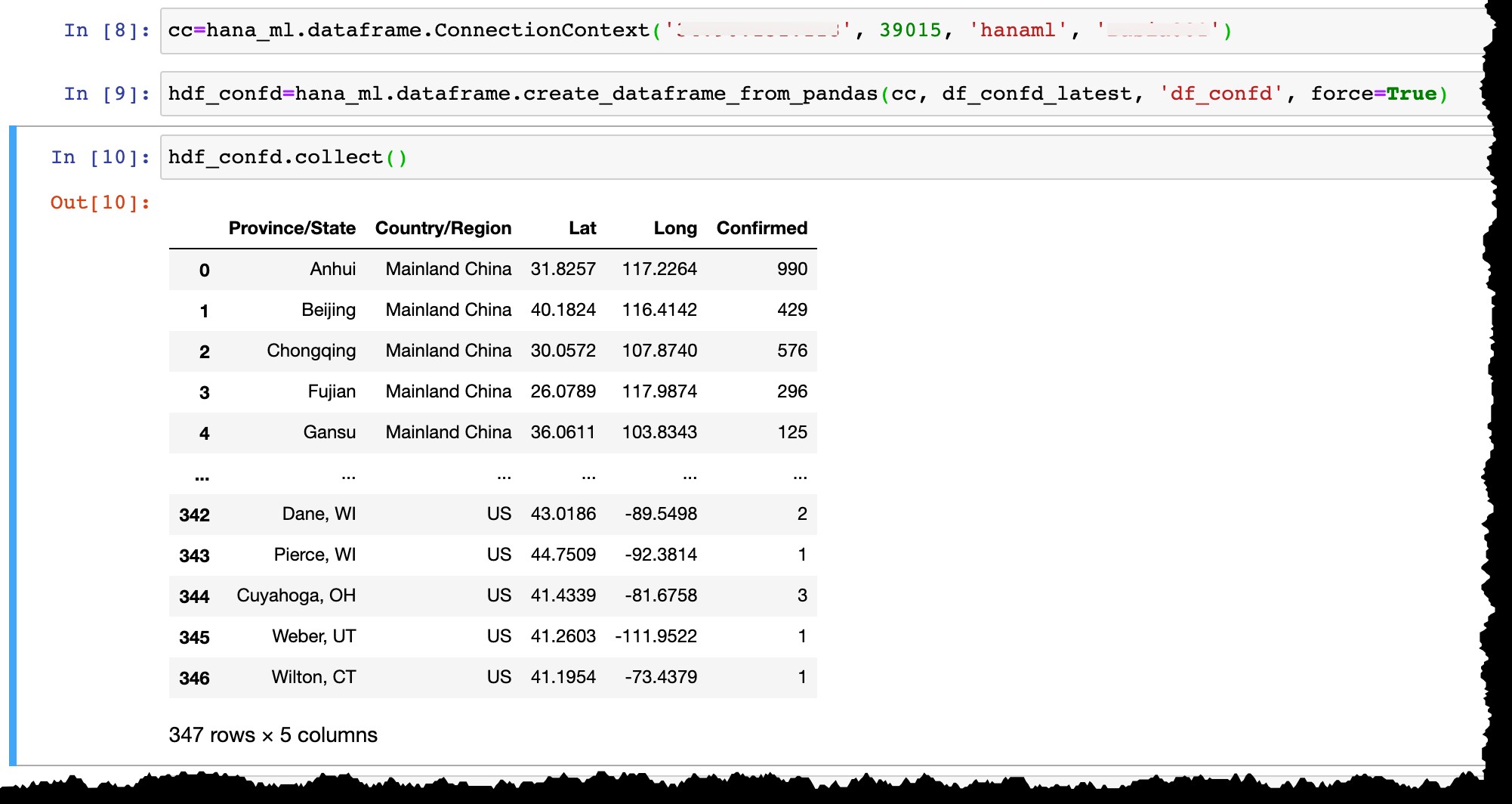
Laat me nu verbinding maken met mijn exemplaar van SAP HANA Express met de gebruiker hanaml die daar al bestaat…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
...en converteer het Pandas-dataframe df_confd_latest in een HANA-dataframe hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Zodra het HANA-dataframe is gemaakt:
- Er wordt een fysieke kolomtabel gemaakt in HANA en gegevens uit het Panda's-dataframe worden daar ingevoegd,
- HANA-dataframe
hdf_confdin Python slaat geen gegevens op uw laptop op, maar verwijst alleen naar een tabelHANAML.df_confdin SAP HANA-servergeheugen en alle Python-bewerkingen op het HANA-dataframe worden fysiek uitgevoerd in HANA db zonder gegevens tussen de server en een client te verplaatsen, - Om het resultaat van bewerkingen weer te geven, moeten we
collect(). toepassen methode om HANA-dataframe naar Panda's te converteren (en als resultaat om gegevens van HANA db-server naar de lokale client te brengen).
Gebruik DBeaver om gegevens in SAP HANA te controleren...
U herinnert zich misschien dat ik DBeaver al gebruikte - de gratis databasetool die SAP HANA ondersteunt - in mijn vorige post "GeoArt met SAP HANA en DBeaver".
Ik gebruik het nu weer, en inderdaad kan ik de tabel df_confd . vinden in het schema HANAML met alle gegevens uit het bron-Pandas-dataframe.
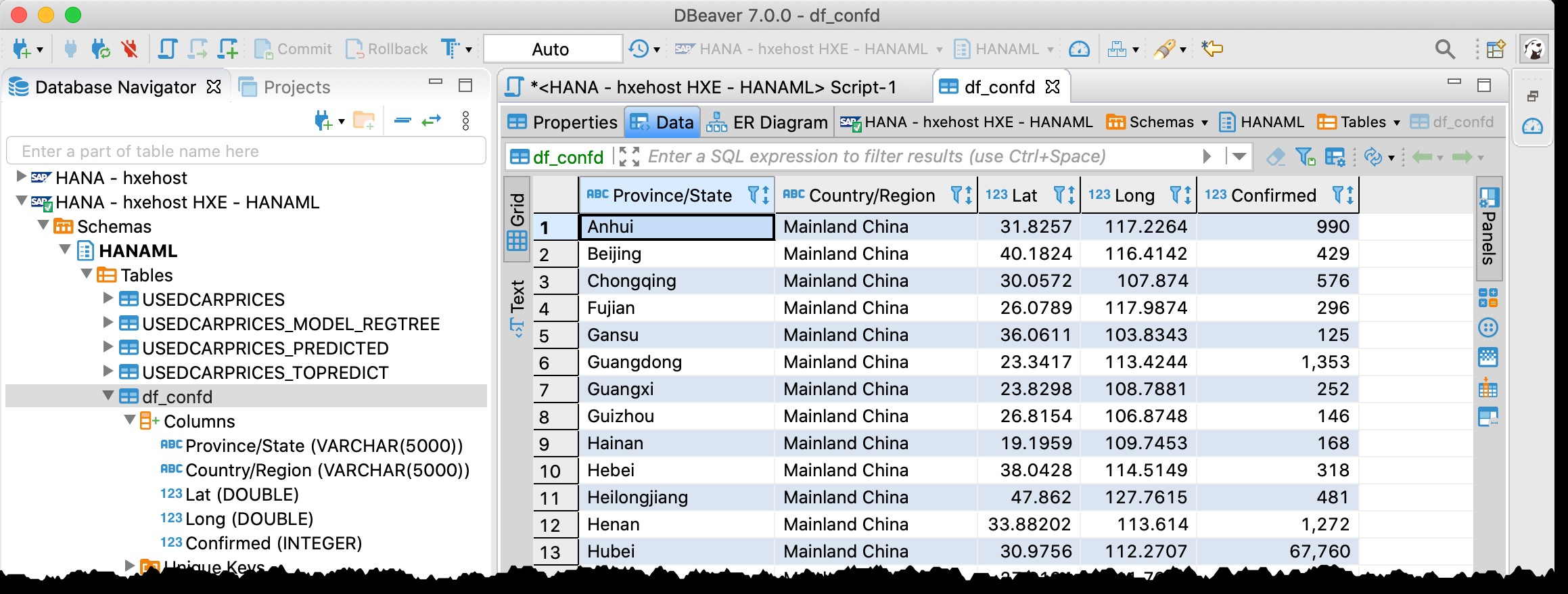
...en maak een ruimtelijke preview
Omdat de tabel breedte- en lengtegraadkolommen bevat, kan ik de getroffen landen/staten rechtstreeks vanuit DBeaver visualiseren met de volgende SQL met behulp van Spatial data preview.
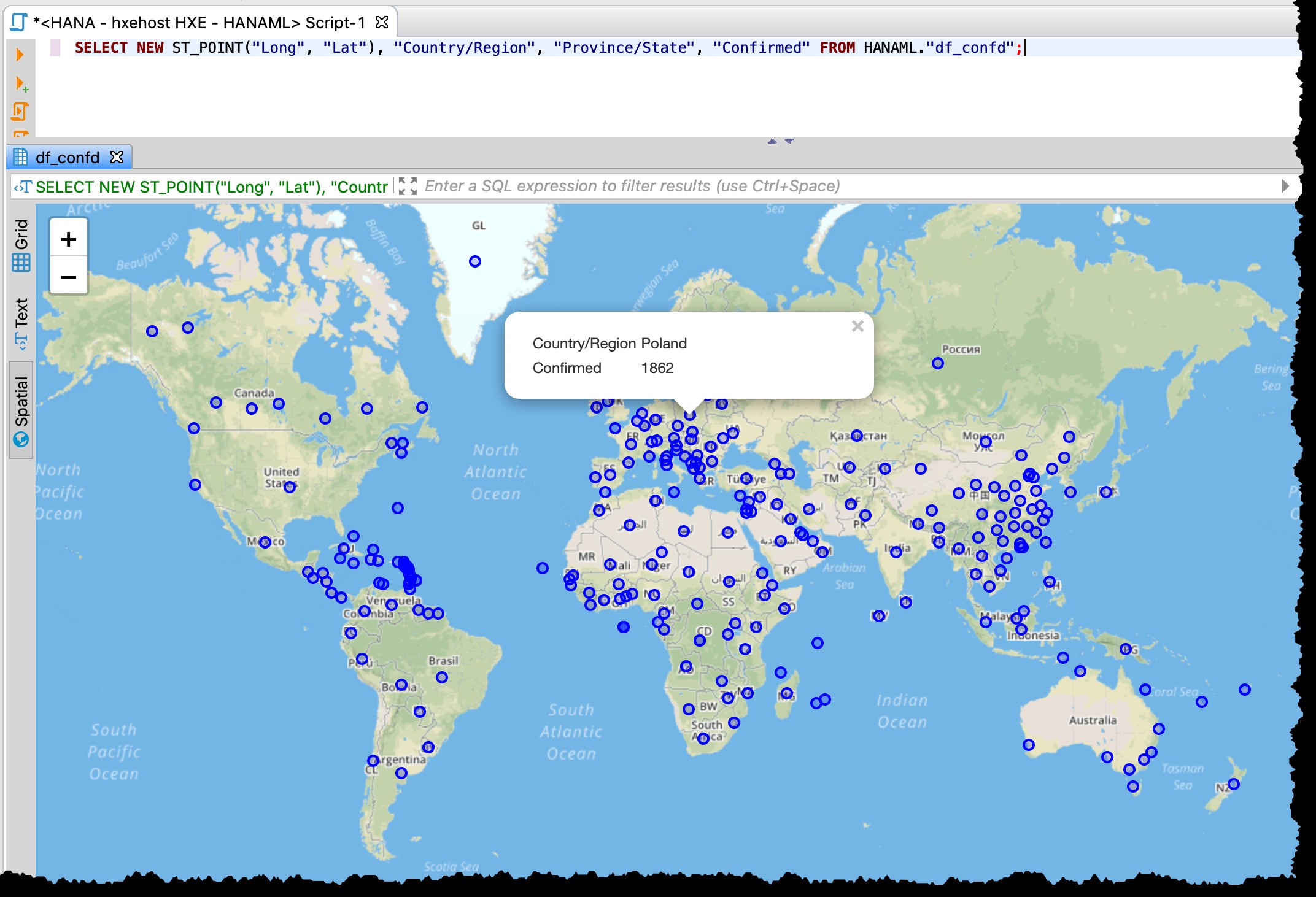
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Ik moest de kaartprojectie wijzigen in EPSG:4326 om deze punten op de kaart te krijgen. En DBeaver laat me de rest van de recordgegevens zien wanneer ik op een punt klik.
[Hieronder is de oude screenshot van 2020-03-11, die ook de verschillende granulariteit van b.v. Amerikaanse gegevens die destijds werden gebruikt]
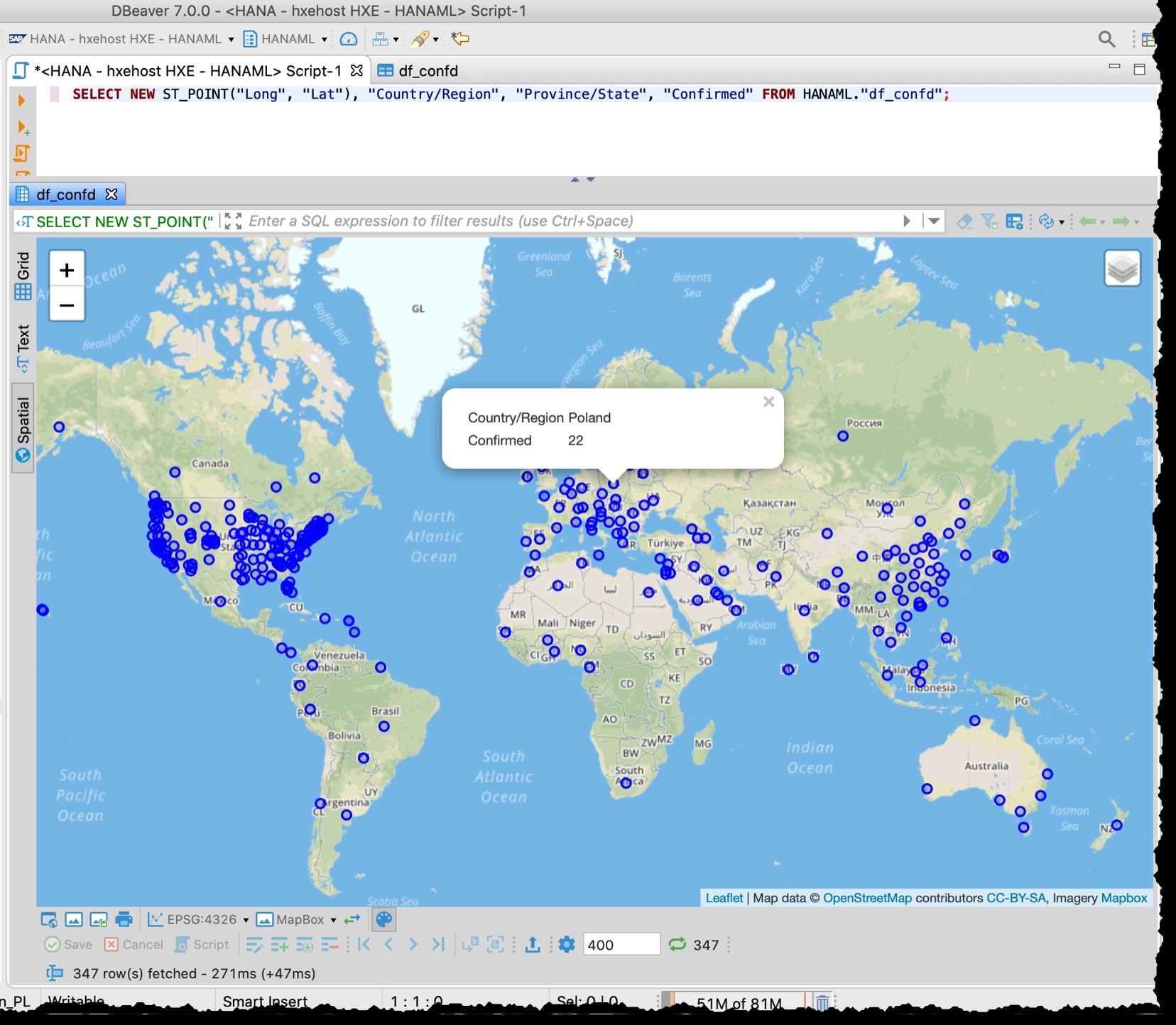
De ruimtelijke preview van DBeaver is geen volledig hulpmiddel voor geospatiale visuele verkenning. Toch is het goed genoeg om de getroffen landen/regio's te zien (afhankelijk van de granulariteit in de bronbestanden).
Mocht je meer willen weten over hana_ml …
… dan zou ik zeker aanraden om Hands-On Tutorial:Machine Learning push-down naar SAP HANA met Python van Andreas Forster te bekijken.
HANA ML maakt deel uit van het nieuwe onderwerp "Advanced Analytics with SAP HANA" voor CodeJam-evenementen. Helaas hebben we vanwege de situatie met het coronavirus de eerste georganiseerd door Jakob Flaman in Bern deze maand moeten annuleren. Een andere wordt georganiseerd door Ewelina Pękała op 27 mei in Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Hopelijk wordt de situatie tegen die tijd normaal en hoeven we deze ook niet te annuleren.