In dit artikel gaan we een schraper bouwen voor een echte freelance optreden waarbij de klant een Python-programma wil om gegevens uit Stack Overflow te schrapen om nieuwe vragen te pakken (titel van de vraag en URL). Geschraapte gegevens moeten dan worden opgeslagen in MongoDB. Het is vermeldenswaard dat Stack Overflow een API heeft, die kan worden gebruikt om toegang te krijgen tot de exacte dezelfde gegevens. De klant wilde echter een schraper, dus een schraper kreeg hij.
Gratis bonus: Klik hier om een Python + MongoDB-projectskelet met volledige broncode te downloaden die u laat zien hoe u toegang krijgt tot MongoDB vanuit Python.
Updates:
- 01/03/2014 - De spin is geherstructureerd. Bedankt, @kissgyorgy.
- 18/02/2015 - Deel 2 toegevoegd.
- 09/06/2015 - Bijgewerkt naar de nieuwste versie van Scrapy en PyMongo - proost!
Lees zoals altijd de gebruiksvoorwaarden/service van de site en respecteer de robots.txt bestand voordat u met een schraaptaak begint. Zorg ervoor dat u zich houdt aan ethische scrapingpraktijken door de site niet in korte tijd met talloze verzoeken te overspoelen. Behandel elke site die u schrapt alsof het uw eigen site is .
Installatie
We hebben de Scrapy-bibliotheek (v1.0.3) samen met PyMongo (v3.0.3) nodig voor het opslaan van de gegevens in MongoDB. Je moet ook MongoDB installeren (niet gedekt).
Scrapy
Als je OSX of een beetje Linux gebruikt, installeer dan Scrapy met pip (met je virtualenv geactiveerd):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Als u een Windows-computer gebruikt, moet u een aantal afhankelijkheden handmatig installeren. Raadpleeg de officiële documentatie voor gedetailleerde instructies, evenals deze YouTube-video die ik heb gemaakt.
Nadat Scrapy is ingesteld, verifieert u uw installatie door deze opdracht in de Python-shell uit te voeren:
>>>>>> import scrapy
>>>
Als je geen foutmelding krijgt, ben je klaar om te gaan!
PyMongo
Installeer vervolgens PyMongo met pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Nu kunnen we beginnen met het bouwen van de crawler.
Scrapy-project
Laten we een nieuw Scrapy-project starten:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Dit creëert een aantal bestanden en mappen die een standaard boilerplate bevatten zodat u snel aan de slag kunt:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Gegevens specificeren
De items.py bestand wordt gebruikt om opslag "containers" te definiëren voor de gegevens die we van plan zijn te schrapen.
De StackItem() klasse erft van Item (docs), die in feite een aantal vooraf gedefinieerde objecten heeft die Scrapy al voor ons heeft gebouwd:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Laten we enkele items toevoegen die we eigenlijk willen verzamelen. Voor elke vraag heeft de klant de titel en URL nodig. Dus update items.py zoals zo:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Maak de spin
Maak een bestand met de naam stack_spider.py in de map "spinnen". Dit is waar de magie gebeurt - bijvoorbeeld, waar we Scrapy vertellen hoe de exacte te vinden gegevens waarnaar we op zoek zijn. Zoals je je kunt voorstellen, is dit specifiek naar elke afzonderlijke webpagina die u wilt schrapen.
Begin met het definiëren van een klasse die erft van Scrapy's Spider en vervolgens zo nodig attributen toe te voegen:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
De eerste paar variabelen spreken voor zich (docs):
namedefinieert de naam van de spin.allowed_domainsbevat de basis-URL's voor de domeinen die de spider mag crawlen.start_urlsis een lijst met URL's van waaruit de spider kan beginnen met crawlen. Alle volgende URL's beginnen met de gegevens die de spider downloadt van de URL's instart_urls.
XPath-kiezers
Vervolgens gebruikt Scrapy XPath-selectors om gegevens van een website te extraheren. Met andere woorden, we kunnen bepaalde delen van de HTML-gegevens selecteren op basis van een bepaald XPath. Zoals vermeld in de documentatie van Scrapy:"XPath is een taal voor het selecteren van knooppunten in XML-documenten, die ook met HTML kan worden gebruikt."
U kunt eenvoudig een specifiek Xpath vinden met de ontwikkelaarstools van Chrome. Inspecteer eenvoudig een specifiek HTML-element, kopieer het XPath en pas het vervolgens aan (indien nodig):
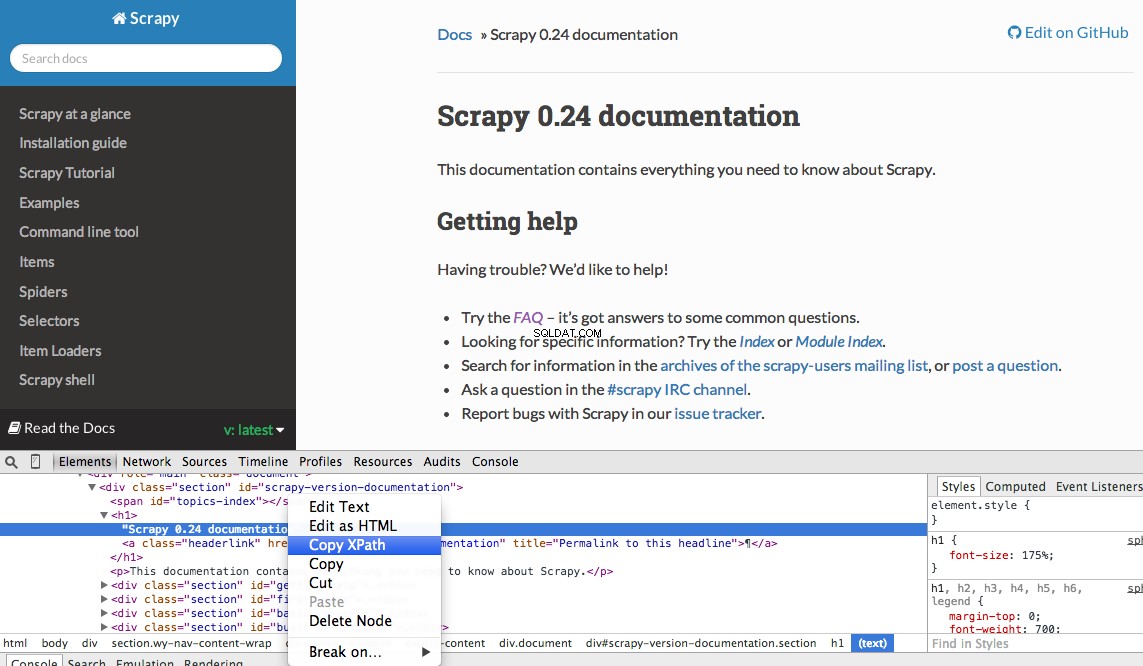
Developer Tools biedt u ook de mogelijkheid om XPath-selectors in de JavaScript-console te testen met behulp van $x - d.w.z. $x("//img") :
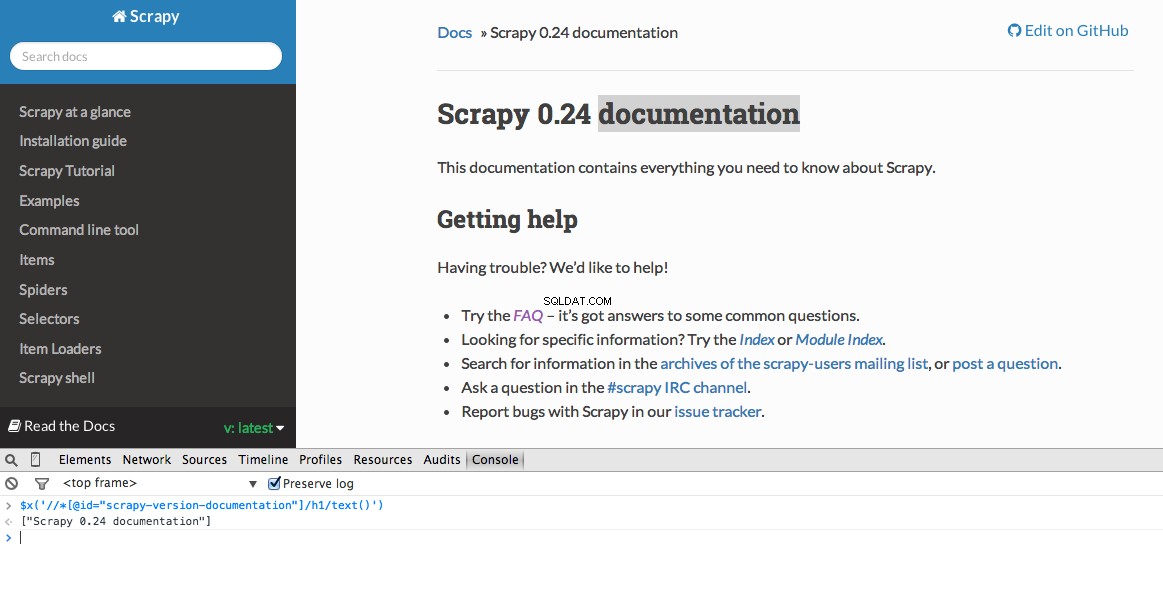
Nogmaals, we vertellen Scrapy in feite waar te beginnen met het zoeken naar informatie op basis van een gedefinieerde XPath. Laten we naar de Stack Overflow-site in Chrome navigeren en de XPath-selectors zoeken.
Klik met de rechtermuisknop op de eerste vraag en selecteer "Inspect Element":
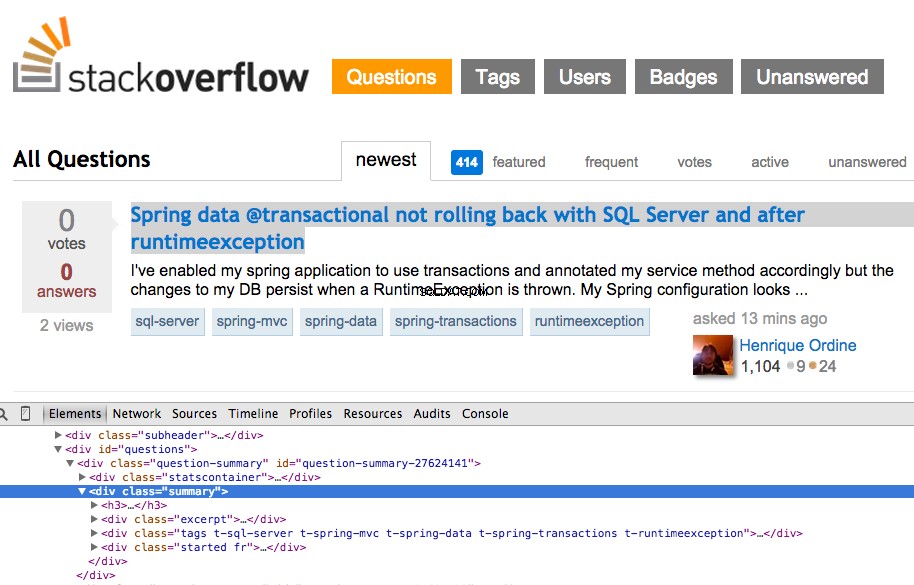
Pak nu de XPath voor de <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] en test het vervolgens in de JavaScript-console:
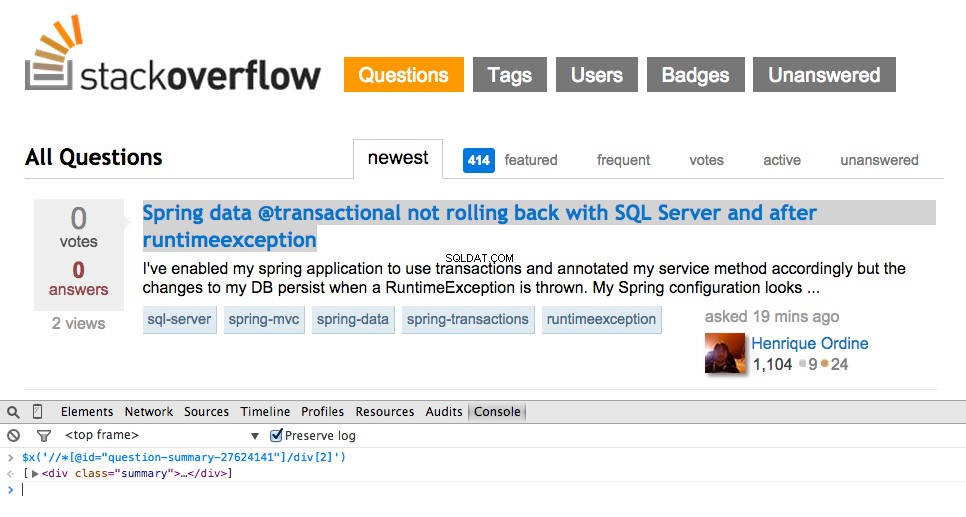
Zoals je kunt zien, selecteert het gewoon die één vraag. We moeten dus de XPath wijzigen om alles te pakken te krijgen vragen. Om het even welke ideeën? Het is eenvoudig://div[@class="summary"]/h3 . Wat betekent dit? In wezen zegt dit XPath:Pak alle <h3> elementen die kinderen zijn van een <div> die een klasse heeft van summary . Test deze XPath uit in de JavaScript-console.
Merk op hoe we de werkelijke XPath-uitvoer van Chrome Developer Tools niet gebruiken. In de meeste gevallen is de uitvoer slechts een nuttige terzijde, die u over het algemeen in de goede richting wijst voor het vinden van de werkende XPath.
Laten we nu de stack_spider.py . updaten script:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
De gegevens extraheren
We moeten nog steeds de gewenste gegevens ontleden en schrapen, die vallen binnen <div class="summary"><h3> . Nogmaals, update stack_spider.py zoals zo:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Samen met de Scrapy-stacktracering, zou u 50 vraagtitels en URL's moeten zien uitgevoerd. U kunt de uitvoer naar een JSON-bestand renderen met dit kleine commando:
$ scrapy crawl stack -o items.json -t json
We hebben onze Spider nu geïmplementeerd op basis van onze gegevens die we zoeken. Nu moeten we de geschraapte gegevens opslaan in MongoDB.
Bewaar de gegevens in MongoDB
Elke keer dat een item wordt geretourneerd, willen we de gegevens valideren en vervolgens toevoegen aan een Mongo-collectie.
De eerste stap is het maken van de database die we van plan zijn te gebruiken om al onze gecrawlde gegevens op te slaan. Open settings.py en specificeer de pijplijn en voeg de database-instellingen toe:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Pijpleidingbeheer
We hebben onze spider ingesteld om de HTML te crawlen en te ontleden, en we hebben onze database-instellingen ingesteld. Nu moeten we de twee met elkaar verbinden via een pijplijn in pipelines.py .
Verbinden met database
Laten we eerst een methode definiëren om daadwerkelijk verbinding te maken met de database:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Hier maken we een klasse, MongoDBPipeline() , en we hebben een constructorfunctie om de klasse te initialiseren door de Mongo-instellingen te definiëren en vervolgens verbinding te maken met de database.
Verwerk de gegevens
Vervolgens moeten we een methode definiëren om de geparseerde gegevens te verwerken:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
We maken een verbinding met de database, pakken de gegevens uit en slaan deze vervolgens op in de database. Nu kunnen we opnieuw testen!
Test
Voer nogmaals de volgende opdracht uit in de map "stack":
$ scrapy crawl stack
OPMERKING :zorg ervoor dat je de Mongo-daemon - mongod . hebt - draait in een ander terminalvenster.
Hoera! We hebben onze gecrawlde gegevens met succes in de database opgeslagen:
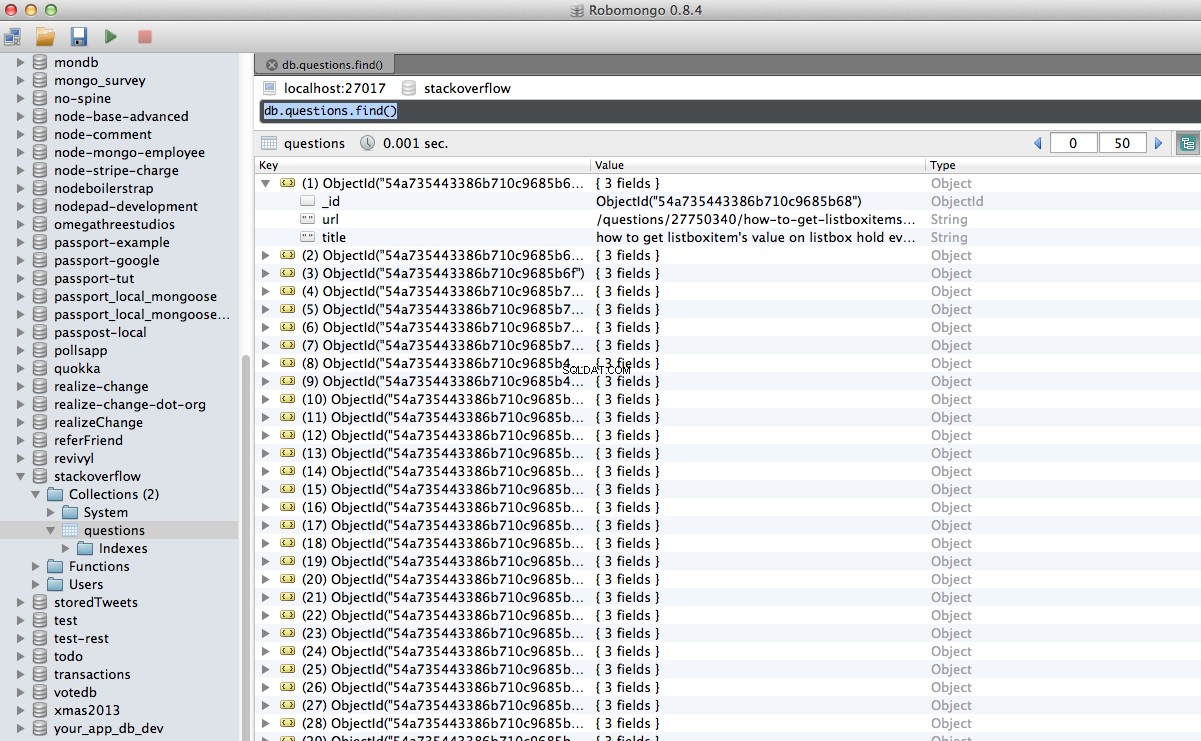
Conclusie
Dit is een vrij eenvoudig voorbeeld van het gebruik van Scrapy om een webpagina te crawlen en te schrapen. Het eigenlijke freelance-project vereiste dat het script de pagineringslinks volgde en elke pagina schrapte met behulp van de CrawlSpider (docs), wat super eenvoudig te implementeren is. Probeer dit zelf te implementeren en laat hieronder een opmerking achter met de link naar de Github-repository voor een snelle codebeoordeling.
Hulp nodig? Begin met dit script, dat bijna voltooid is. Bekijk dan deel 2 voor de volledige oplossing!
Gratis bonus: Klik hier om een Python + MongoDB-projectskelet met volledige broncode te downloaden die u laat zien hoe u toegang krijgt tot MongoDB vanuit Python.
U kunt de volledige broncode downloaden van de Github-repository. Reageer hieronder met vragen. Bedankt voor het lezen!