Een van de grootste zorgen bij het omgaan met en beheren van databases is de complexiteit van gegevens en omvang. Vaak maken organisaties zich zorgen over hoe ze met groei moeten omgaan en hoe ze de groei-impact moeten beheren, omdat het databasebeheer faalt. Complexiteit brengt zorgen met zich mee die in eerste instantie niet werden aangepakt en niet werden gezien, of over het hoofd zouden kunnen worden gezien, omdat de technologie die momenteel wordt gebruikt in staat zal zijn zichzelf aan te pakken. Het beheer van een complexe en grote database moet dienovereenkomstig worden gepland, vooral wanneer het type gegevens dat u beheert of verwerkt naar verwachting enorm zal groeien, ofwel geanticipeerd ofwel op een onvoorspelbare manier. Het belangrijkste doel van planning is om ongewenste rampen te voorkomen, of laten we zeggen:blijf niet in rook op! In deze blog gaan we in op het efficiënt beheren van grote databases.
Gegevensgrootte doet ertoe
De grootte van de database is van belang omdat het een impact heeft op de prestaties en de beheermethodologie. Hoe de gegevens worden verwerkt en opgeslagen, zal bijdragen aan het beheer van de database, wat zowel van toepassing is op gegevens in transit als op gegevens in rust. Voor veel grote organisaties zijn data goud, en de groei van data kan een drastische verandering in het proces veroorzaken. Daarom is het essentieel om vooraf plannen te hebben om groeiende gegevens in een database te verwerken.
In mijn ervaring met het werken met databases, ben ik getuige geweest van klanten die problemen hadden met prestatiestraffen en het beheren van extreme gegevensgroei. Er rijzen vragen of de tabellen moeten worden genormaliseerd of de tabellen moeten worden gedenormaliseerd.
Tabellen normaliseren
Normalisering van tabellen handhaaft de gegevensintegriteit, vermindert redundantie en maakt het gemakkelijk om de gegevens te ordenen op een efficiëntere manier om te beheren, analyseren en extraheren. Werken met genormaliseerde tabellen levert efficiëntie op, vooral bij het analyseren van de gegevensstroom en het ophalen van gegevens via SQL-instructies of het werken met programmeertalen zoals C/C++, Java, Go, Ruby, PHP of Python-interfaces met de MySQL-connectoren.
Hoewel problemen met genormaliseerde tabellen prestatieverlies met zich meebrengen en de query's kunnen vertragen vanwege reeksen joins bij het ophalen van de gegevens. Terwijl gedenormaliseerde tabellen, is alles wat u moet overwegen voor optimalisatie afhankelijk van de index of de primaire sleutel om gegevens in de buffer op te slaan voor sneller ophalen dan het uitvoeren van zoekopdrachten op meerdere schijven. Gedenormaliseerde tabellen vereisen geen joins, maar het offert de gegevensintegriteit op en de databasegrootte wordt steeds groter.
Als uw database groot is, overweeg dan om een DDL (Data Definition Language) voor uw databasetabel in MySQL/MariaDB te gebruiken. Als u een primaire of unieke sleutel voor uw tabel wilt toevoegen, moet u de tabel opnieuw opbouwen. Het wijzigen van een kolomgegevenstype vereist ook het opnieuw opbouwen van een tabel, aangezien het toe te passen algoritme alleen ALGORITHM=COPY is.
Als je dit in je productieomgeving doet, kan dat een uitdaging zijn. Verdubbel de uitdaging als uw tafel enorm is. Stel je een miljoen of een miljard rijen voor. U kunt een ALTER TABLE-instructie niet rechtstreeks op uw tabel toepassen. Dat kan al het inkomende verkeer blokkeren dat toegang nodig heeft tot de tabel waarop u momenteel de DDL toepast. Dit kan echter worden verzacht door pt-online-schema-change of the great gh-ost te gebruiken. Desalniettemin vereist het monitoring en onderhoud tijdens het proces van DDL.
Sharden en partitioneren
Met sharding en partitionering helpt het de gegevens te scheiden of te segmenteren op basis van hun logische identiteit. Bijvoorbeeld door te scheiden op basis van datum, alfabetische volgorde, land, staat of primaire sleutel op basis van het opgegeven bereik. Dit helpt uw databasegrootte beheersbaar te zijn. Houd uw database zo groot dat deze beheersbaar is voor uw organisatie en uw team. Eenvoudig op te schalen indien nodig of eenvoudig te beheren, vooral wanneer zich een ramp voordoet.
Als we zeggen beheersbaar, denk dan ook aan de capaciteitsbronnen van uw server en ook aan uw technische team. Met weinig engineers kun je niet met grote en grote data werken. Werken met big data zoals 1000 databases met grote aantallen datasets vraagt enorm veel tijd. Vakmanschap en expertise is een must. Als kosten een probleem zijn, is dat het moment waarop u gebruik kunt maken van services van derden die beheerde services of betaald advies of ondersteuning bieden voor dergelijke technische werkzaamheden.
Tekensets en sortering
Tekensets en sorteringen zijn van invloed op de gegevensopslag en prestaties, vooral op de gegeven tekenset en geselecteerde sorteringen. Elke tekenset en sortering heeft zijn doel en vereist meestal verschillende lengtes. Als u tabellen heeft waarvoor andere tekensets en sorteringen nodig zijn vanwege tekencodering, moeten de gegevens worden opgeslagen en verwerkt voor uw database en tabellen of zelfs met kolommen.
Dit beïnvloedt hoe u uw database effectief kunt beheren. Het heeft invloed op uw gegevensopslag en ook op de prestaties, zoals eerder vermeld. Als u de soorten tekens begrijpt die door uw toepassing moeten worden verwerkt, let dan op de tekenset en sorteringen die moeten worden gebruikt. LATIJNSE typen tekensets zullen meestal volstaan voor het alfanumerieke type tekens dat moet worden opgeslagen en verwerkt.
Als het onvermijdelijk is, helpen sharding en partitionering om de gegevens op zijn minst te verminderen en te beperken om te voorkomen dat er teveel gegevens op uw databaseserver worden opgeslagen. Het beheren van zeer grote gegevens op een enkele databaseserver kan van invloed zijn op de efficiëntie, met name voor back-updoeleinden, rampen en herstel, of gegevensherstel in geval van gegevensbeschadiging of gegevensverlies.
Databasecomplexiteit beïnvloedt prestaties
Een grote en complexe database heeft meestal een factor als het gaat om prestatieverlies. Complex betekent in dit geval dat de inhoud van uw database bestaat uit wiskundige vergelijkingen, coördinaten of numerieke en financiële records. Mix deze records nu met zoekopdrachten die agressief gebruikmaken van de wiskundige functies die eigen zijn aan de database. Bekijk de voorbeeld SQL-query (compatibel met MySQL/MariaDB) hieronder,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Bedenk dat deze zoekopdracht wordt toegepast op een tabel met een bereik van een miljoen rijen. Er is een grote kans dat dit de server kan blokkeren, en het kan veel resources kosten, waardoor de stabiliteit van uw productiedatabasecluster in gevaar komt. Betrokken kolommen worden meestal geïndexeerd om deze query te optimaliseren en te laten presteren. Het toevoegen van indexen aan de kolommen waarnaar wordt verwezen voor optimale prestaties, garandeert echter niet de efficiëntie van het beheer van uw grote databases.
Bij het omgaan met complexiteit is de efficiëntere manier om rigoureus gebruik van complexe wiskundige vergelijkingen en agressief gebruik van deze ingebouwde complexe rekencapaciteit te vermijden. Dit kan worden bediend en getransporteerd via complexe berekeningen met behulp van backend-programmeertalen in plaats van met behulp van de database. Als u complexe berekeningen heeft, waarom slaat u deze vergelijkingen dan niet op in de database, haalt u de query's op en organiseert u deze in een gemakkelijker te analyseren of debuggen wanneer dat nodig is.
Gebruikt u de juiste database-engine?
Een gegevensstructuur beïnvloedt de prestaties van de databaseserver op basis van de combinatie van de gegeven query en de records die worden gelezen of opgehaald uit de tabel. De database-engines binnen MySQL/MariaDB ondersteunen InnoDB en MyISAM die B-Trees gebruiken, terwijl NDB- of Memory-database-engines Hash Mapping gebruiken. Deze datastructuren hebben hun asymptotische notatie, die de prestaties uitdrukken van de algoritmen die door deze datastructuren worden gebruikt. We noemen deze in Computer Science als Big O-notatie die de prestaties of complexiteit van een algoritme beschrijft. Aangezien InnoDB en MyISAM B-Trees gebruiken, gebruikt het O(log n) om te zoeken. Terwijl Hash Tables of Hash Maps O(n) gebruiken. Beide delen het gemiddelde en het slechtste geval voor zijn prestaties met zijn notatie.
Terug naar de specifieke engine, gezien de gegevensstructuur van de engine, heeft de query die moet worden toegepast op basis van de doelgegevens die moeten worden opgehaald, natuurlijk invloed op de prestaties van uw databaseserver. Hash-tabellen kunnen geen bereik ophalen, terwijl B-Trees zeer efficiënt is voor dit soort zoekopdrachten en ook grote hoeveelheden gegevens aankan.
Met behulp van de juiste engine voor de gegevens die u opslaat, moet u bepalen welk type zoekopdracht u toepast voor deze specifieke gegevens die u opslaat. Wat voor soort logica deze gegevens moeten formuleren wanneer ze worden omgezet in een bedrijfslogica.
Omgaan met duizenden of duizenden databases, het gebruik van de juiste engine in combinatie van uw zoekopdrachten en gegevens die u wilt ophalen en opslaan, zal goede prestaties opleveren. Aangezien u uw vereisten voor het doel ervan voor de juiste database-omgeving vooraf hebt bepaald en geanalyseerd.
Juiste tools om grote databases te beheren
Het is erg moeilijk en moeilijk om een zeer grote database te beheren zonder een solide platform waarop u kunt vertrouwen. Zelfs met goede en bekwame database-engineers is de databaseserver die u gebruikt technisch gezien vatbaar voor menselijke fouten. Eén fout bij het wijzigen van uw configuratieparameters en variabelen kan resulteren in een drastische wijziging waardoor de prestaties van de server afnemen.
Het maken van een back-up naar uw database op een zeer grote database kan soms een uitdaging zijn. Er zijn gevallen dat de back-up om vreemde redenen kan mislukken. Doorgaans mislukken query's die de server waarop de back-up wordt uitgevoerd, kunnen blokkeren. Anders moet u de oorzaak ervan onderzoeken.
Het gebruik van automatisering zoals Chef, Puppet, Ansible, Terraform of SaltStack kan worden gebruikt als uw IaC om snellere taken uit te voeren. Terwijl u ook andere tools van derden gebruikt om u te helpen bij het bewaken en leveren van grafische afbeeldingen van hoge kwaliteit. Waarschuwings- en alarmmeldingssystemen zijn ook erg belangrijk om u op de hoogte te stellen van problemen die kunnen optreden van waarschuwings- tot kritieke statusniveau. Dit is waar ClusterControl erg handig is in dit soort situaties.
ClusterControl biedt gemak bij het beheren van een groot aantal databases of zelfs met shard-type omgevingen. Het is duizend keer getest en geïnstalleerd en is tegengekomen in producties met alarmen en meldingen aan de DBA's, technici of DevOps die de database-omgeving bedienen. Variërend van enscenering of ontwikkeling, QA's, tot productieomgeving.
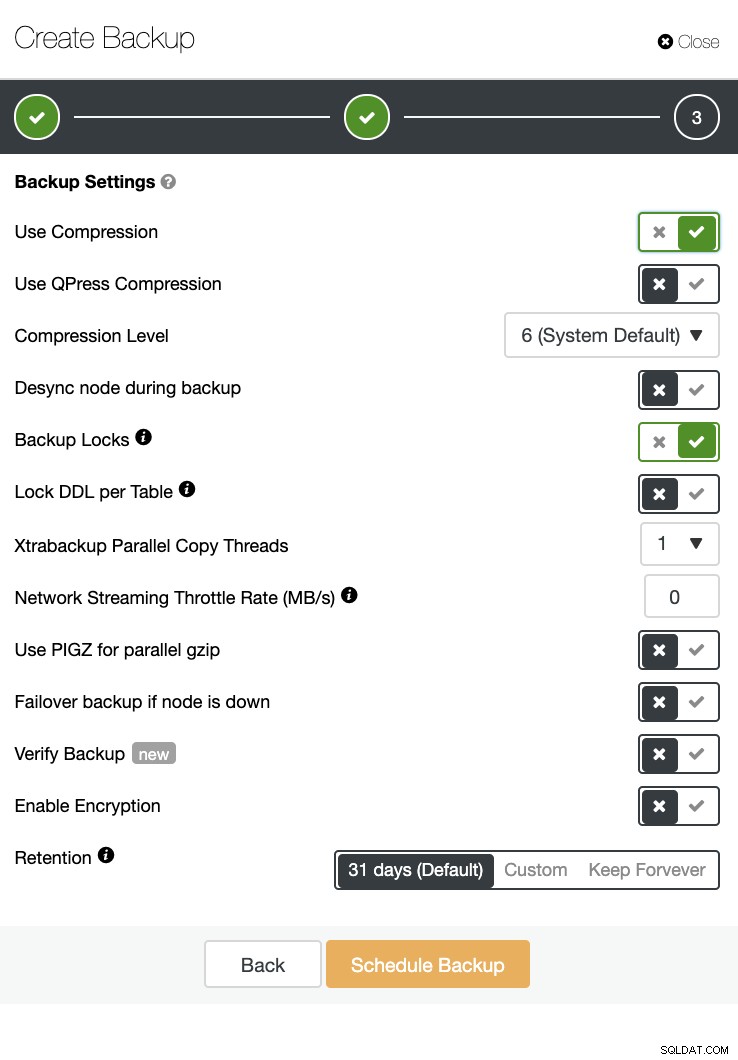
ClusterControl kan ook een back-up en herstel uitvoeren. Zelfs met grote databases kan het efficiënt en gemakkelijk te beheren zijn, omdat de gebruikersinterface planning biedt en ook opties heeft om deze naar de cloud te uploaden (AWS, Google Cloud en Azure).
Er is ook een back-upverificatie en veel opties zoals codering en compressie. Zie bijvoorbeeld de onderstaande schermafbeelding (een back-up maken voor MySQL met Xtrabackup):
Conclusie
Het beheren van grote databases zoals duizend of meer kan efficiënt worden gedaan, maar het moet van tevoren worden bepaald en voorbereid. Het gebruik van de juiste tools zoals automatisering of zelfs een abonnement op managed services helpt enorm. Hoewel dit kosten met zich meebrengt, kan de doorlooptijd van de service en het budget dat moet worden besteed aan het aantrekken van bekwame technici worden verminderd zolang de juiste tools beschikbaar zijn.