Organisaties maken gebruik van infrastructuur in de cloud omdat deze snelheid, flexibiliteit en schaalbaarheid biedt. U kunt zich voorstellen dat we met slechts een klik een nieuwe database-instantie kunnen starten en het een paar minuten duurt voordat deze klaar is, we kunnen de toepassing ook sneller implementeren dan in vergelijking met een on-prem-omgeving.
Tenzij u de eigen cloudservice van MongoDB gebruikt, bieden de grote cloudproviders geen beheerde MongoDB-service, dus het is niet echt een bewerking met één klik om een enkele instantie of cluster te implementeren. De gebruikelijke manier is om VM's te laten draaien en ze vervolgens hierop te implementeren. De implementatie moet van A tot Z worden verzorgd - we moeten de instantie voorbereiden, de databasesoftware installeren, enkele configuraties afstemmen en de instantie beveiligen. Deze taken zijn essentieel, hoewel ze niet altijd goed worden opgevolgd - met mogelijk desastreuze gevolgen.
Automatisering speelt een belangrijke rol bij het verzekeren van alle taken vanaf installatie, configuratie, verharding en totdat de databaseservice gereed is. In deze blog bespreken we implementatieautomatisering voor MongoDB.
Software Orchestrator
Er zijn veel nieuwe softwaretools waarmee technici hun infrastructuur kunnen implementeren en beheren. Configuratiebeheer helpt engineers om sneller en effectiever te implementeren, waardoor de implementatietijd voor nieuwe services wordt verkort. Populaire opties zijn Ansible, Saltstack, Chef en Puppet. Elk product heeft voor- en nadelen, maar ze werken allemaal erg goed en zijn enorm populair. Het implementeren van een stateful-service zoals een MongoDB ReplicaSet of Sharded Cluster kan een beetje uitdagender zijn, omdat dit multi-serverconfiguraties zijn en de tools slechte ondersteuning bieden voor incrementele en cross-node-coördinatie. Implementatieprocedures vereisen meestal orkestratie over knooppunten, waarbij taken in een specifieke volgorde worden uitgevoerd.
MongoDB-implementatietaken om te automatiseren
Het inzetten van een MongoDB-server omvat een aantal zaken; voeg MongoDB-repository toe aan lokaal, installeer MongoDB-pakket, configureer poort, gebruikersnaam en start de service.
Taak:MongoDB installeren
- name: install mongoDB
apt:
name: mongodb
state: present
update_cache: yes
Taak:kopieer de mongod.conf uit het configuratiebestand.
- name: copy config file
copy:
src: mongodb.conf
dest: /etc/mongodb.conf
owner: root
group: root
mode: 0644
notify:
- restart mongodbTaak:maak MongoDB-limietconfiguratie:
- name: create /etc/security/limits.d/mongodb.conf
copy:
src: security-mongodb.conf
dest: /etc/security/limits.d/mongodb.conf
owner: root
group: root
mode: 0644
notify:
- restart mongodbTaak:swappiness configureren
- name: config vm.swappiness
sysctl:
name: vm.swappiness
value: '10'
state: presentTaak:TCP Keepalive-tijd configureren
- name: config net.ipv4.tcp_keepalive_time
sysctl:
name: net.ipv4.tcp_keepalive_time
value: '120'
state: presentTaak:zorg ervoor dat MongoDB automatisch start
- name: Ensure mongodb is running and and start automatically on reboots
systemd:
name: mongodb
enabled: yes
state: startedWe kunnen al deze taken combineren in één playbook en het playbook uitvoeren om de implementatie te automatiseren. Als we een Ansible-playbook vanaf de console uitvoeren:
$ ansible-playbook -b mongoInstall.ymlWe zullen de voortgang van de implementatie van ons Ansible-script zien, de uitvoer zou ongeveer als volgt moeten zijn:
PLAY [ansible-mongo] **********************************************************
GATHERING FACTS ***************************************************************
ok: [10.10.10.11]
TASK: [install mongoDB] *******************************************************
ok: [10.10.10.11]
TASK: [copy config file] ******************************************************
ok: [10.10.10.11]
TASK: [create /etc/security/limits.d/mongodb.conf]*****************************
ok: [10.10.10.11]
TASK: [config vm.swappiness] **************************************************
ok: [10.10.10.11]
TASK: [config net.ipv4.tcp_keepalive_time]*************************************
ok: [10.10.10.11]
TASK: [config vm.swappiness] **********************************************
ok: [10.10.10.11]
PLAY RECAP ********************************************************************
[10.10.10.11] : ok=6 changed=1 unreachable=0 failed=0Na de implementatie kunnen we de MongoDB-service op de doelserver controleren.
Automatisering van implementatie van MongoDB met behulp van ClusterControl GUI
Er zijn twee manieren om MongoDB te implementeren met ClusterControl. We kunnen het gebruiken vanaf het dashboard van ClusterControl, het is GUI-gebaseerd en heeft slechts 2 dialogen nodig totdat het een nieuwe taak activeert voor een nieuwe implementatie van MongoDB.
Eerst moeten we de SSH-gebruiker en het wachtwoord invullen, vul de clusternaam in zoals hieronder weergegeven:
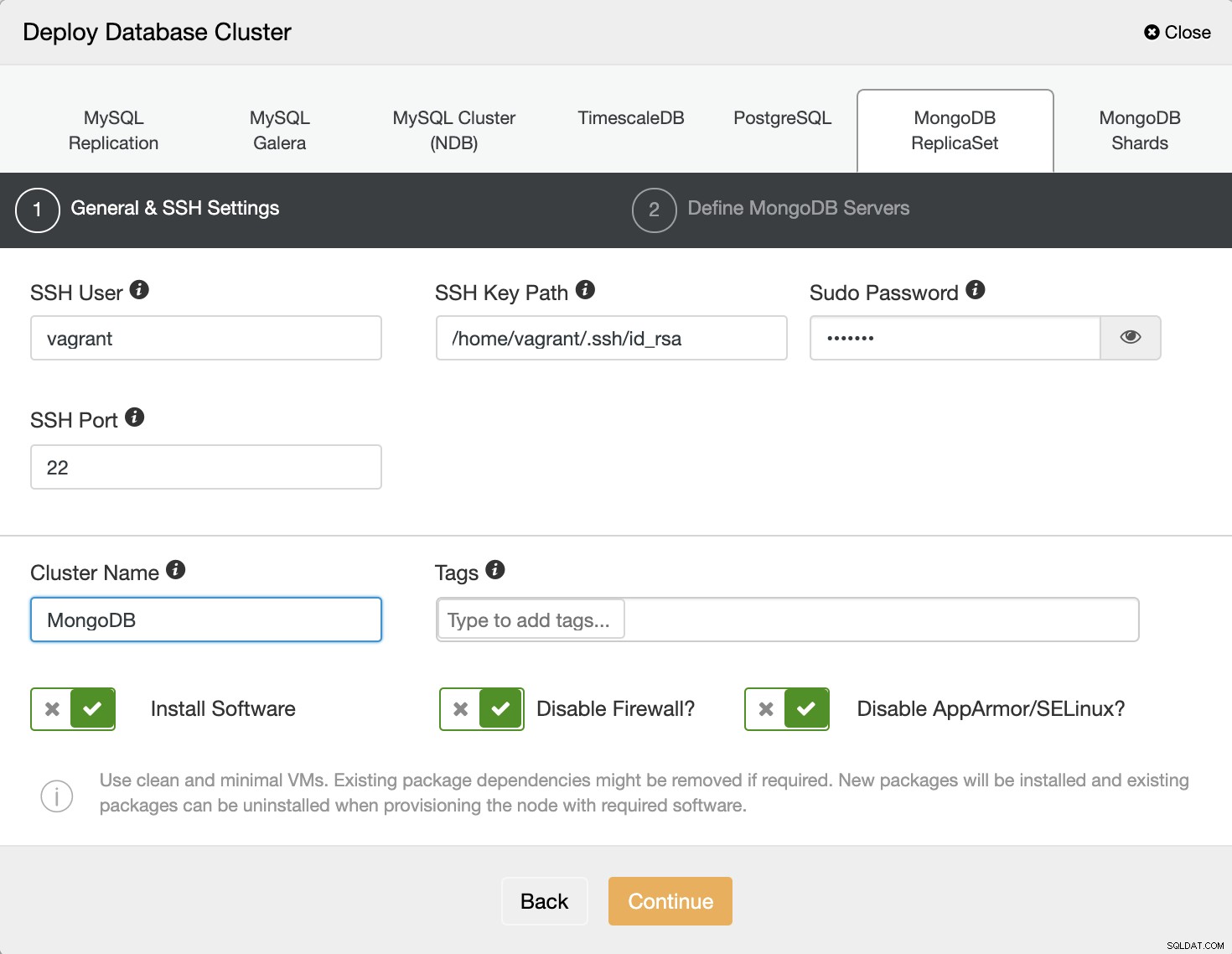
Kies vervolgens de leverancier en versie van MongoDB, definieer de gebruiker en wachtwoord, en de laatste is vul het doel-IP-adres
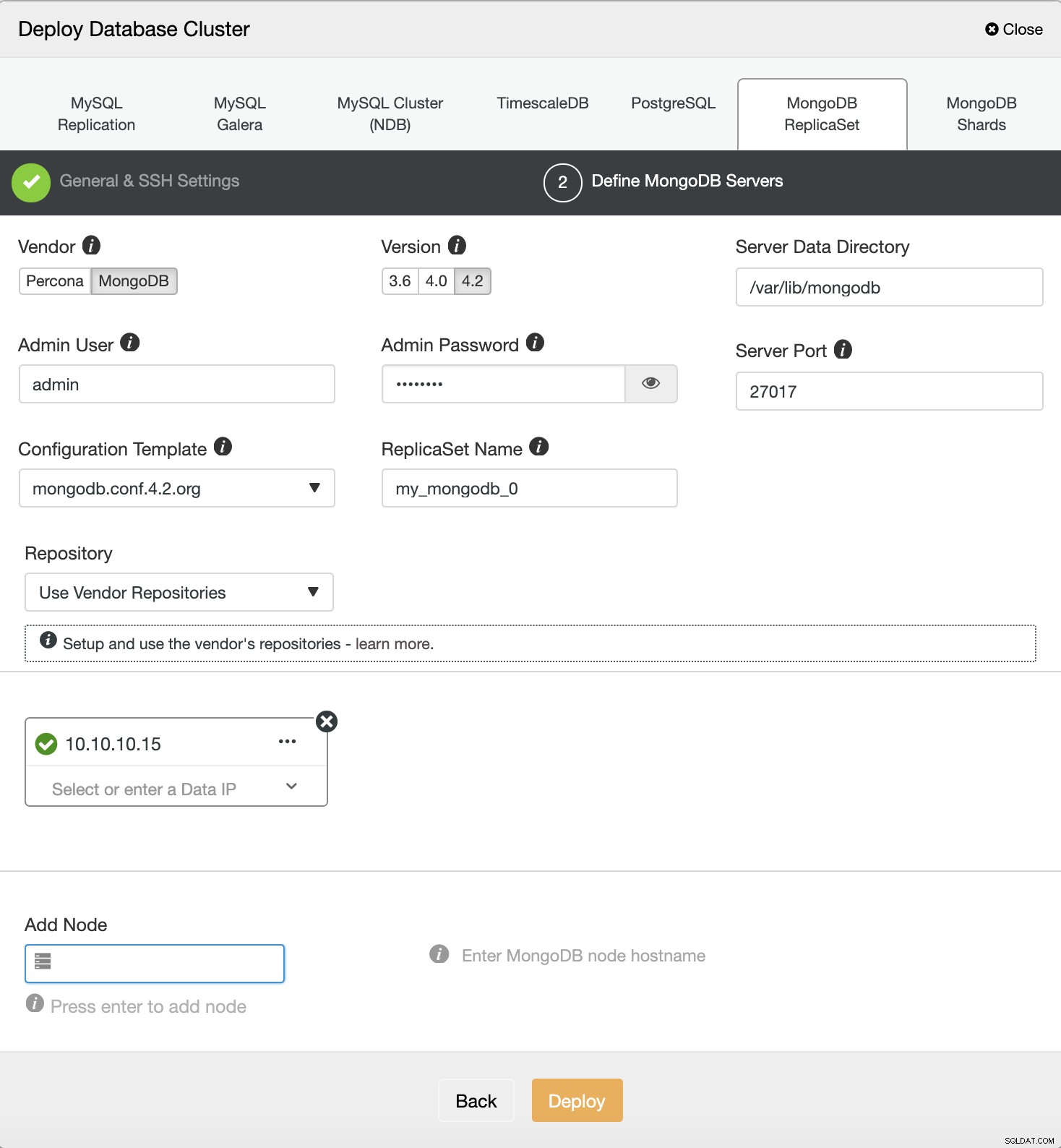
Automatisering van implementatie van MongoDB met s9s CLI
Vanuit de opdrachtregelinterface kan men de s9s-tools gebruiken. De implementatie van MongoDB met s9s is slechts een opdracht van één regel, zoals hieronder:
$ s9s cluster --create --cluster-type=mongodb --nodes="10.10.10.15" --vendor=percona --provider-version=4.2 --db-admin-passwd="12qwaszx" --os-user=vagrant --cluster-name="MongoDB" --wait
Create Mongo Cluster
/ Job 183 FINISHED [██████████] 100% Job finished.
Dus het inzetten van MongoDB, of het nu een ReplicaSet of een Sharded Cluster is, is heel eenvoudig en wordt volledig geautomatiseerd door ClusterControl.