MongoDB-zones
Om MongoDB-zones te begrijpen, moeten we eerst begrijpen wat een zone is:een groep shards op basis van een specifieke set tags.
MongoDB-zones helpen bij de distributie van chunks op basis van tags, over shards. Al het werk (lezen en schrijven) met betrekking tot documenten binnen een zone wordt gedaan op shards die overeenkomen met die zone.
Er kunnen verschillende scenario's zijn waarin sharded-clusters (op zones gebaseerd) zeer nuttig kunnen blijken te zijn. Laten we zeggen:
- Een applicatie, die geografisch gedistribueerd is, kan zowel de frontend als de datastore nodig hebben
- Een applicatie heeft een n-tier architectuur zodat sommige records worden opgehaald van hardware met een hogere laag (lage latentie), terwijl andere kunnen worden opgehaald van hardware met een lage laag (hoge latentie induceren)
Voordelen van het gebruik van MongoDB-zones
Met behulp van MongoDB Zones kunnen DBA's gelaagde opslagoplossingen maken die de gegevenslevenscyclus ondersteunen, met veelgebruikte gegevens die in het geheugen worden opgeslagen, minder gebruikte gegevens op de server en op het juiste moment gearchiveerde gegevens die offline worden gehaald.
Zones instellen
In shardclusters kunt u zones maken die een groep shards vertegenwoordigen en een of meer bereiken van shardsleutelwaarden aan die zone koppelen. MongoDB stuurt alle lees- en schrijfbewerkingen die binnen een zonebereik komen alleen naar die shards binnen de zone. U kunt elke zone koppelen aan een of meer shards in het cluster en een shard kan aan een willekeurig aantal zones worden gekoppeld.
Enkele van de meest voorkomende implementatiepatronen waarbij zones kunnen worden toegepast, zijn als volgt:
- Isoleer een specifieke subset van gegevens op een specifieke set shards.
- Door ervoor te zorgen dat de meest relevante gegevens zich bevinden op shards die zich geografisch het dichtst bij de applicatieservers bevinden.
- Routeer gegevens naar de shards op basis van de prestaties van de shardhardware.
De volgende afbeelding illustreert een shard-cluster met drie shards en twee zones. De A-zone vertegenwoordigt een bereik met een ondergrens van 0 en een bovengrens van 10. De B-zone toont een bereik met een ondergrens van 10 en een bovengrens van 20. Shards ROOD en BLAUW hebben de A-zone. Shard BLUE heeft ook de B-zone. Aan Shard GREEN zijn geen zones gekoppeld. Het cluster bevindt zich in een stabiele toestand en er zijn geen brokken die een van de zones schenden
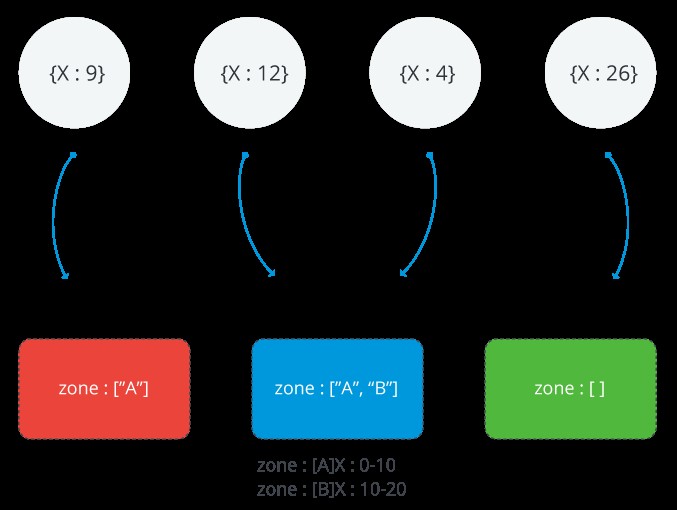
Bereik van een MongoDB-zone
Elke zone omvat een of meer bereiken van Shard-sleutelwaarden. Elk bereik dat een zone bestrijkt, is altijd inclusief de ondergrens en exclusief de bovengrens.
ONTHOUD: Zones kunnen geen bereiken delen en ze mogen geen overlappende bereiken hebben.
Shards toevoegen aan een zone
sh.addShardTag() methode wordt gebruikt om zones toe te voegen aan een shard. Een enkele shard kan meerdere zones hebben en meerdere shards kunnen ook dezelfde zone hebben. Het volgende voorbeeld voegt de zone A toe aan één shard.
sh.addShardTag("shard0000", "A")Shards naar een zone verwijderen
Om een zone uit een shard te verwijderen, wordt de methode sh.removeShardTag() gebruikt. In het volgende voorbeeld wordt zone A uit een scherf verwijderd.
sh.removeShardTag("shard0002", "A")Tips voor MongoDB-zones
Houd documenten eenvoudig
MongoDB is een schemavrije database. Dit betekent dat er standaard geen vooraf gedefinieerd schema is. In nieuwere versies kunnen we een vooraf gedefinieerd schema toevoegen, maar dit is niet verplicht. Onderschat de moeilijkheden die zich voordoen bij het werken met documenten en arrays niet, aangezien het erg moeilijk kan worden om uw gegevens te ontleden in het applicatie-/ETL-proces. Bovendien kunnen arrays de replicatieprestaties schaden:voor elke wijziging in de array worden alle arraywaarden gerepliceerd.
Beste hardware is niet altijd de beste optie
Het gebruik van goede hardware helpt zeker voor een goede prestatie. Maar wat kan er gebeuren in een omgeving als één exemplaar van een grote machine sterft? Het antwoord is 'failover'.
Het hebben van meerdere kleine machines (in plaats van één of twee) in een gedistribueerde omgeving kan ervoor zorgen dat uitval slechts een paar delen van de shard zal treffen met weinig of geen waarneming door de toepassing. Maar tegelijkertijd betekent meer machines een grote kans op een storing. Houd rekening met deze afweging bij het ontwerpen van uw omgeving. De juiste keuzes zijn van invloed op de prestaties.
Werkset
Hoe groot is de werkset? Meestal gebruikt een applicatie niet alle gegevens. Sommige gegevens worden vaak bijgewerkt, andere niet. Past uw werkende dataset in RAM? Optimale prestaties treden op wanneer alle werkende datasets zich in het RAM bevinden.