SCUMM (Severalnines ClusterControl Unified Monitoring &Management) is een op agents gebaseerde oplossing waarbij agents zijn geïnstalleerd op de databaseknooppunten. Het biedt een reeks controledashboards met Prometheus als gegevensopslag met zijn elastische querytaal en multidimensionaal gegevensmodel. Prometheus schraapt metrische gegevens van exporteurs die op de databasehosts worden uitgevoerd.
ClusterControl SCUMM-architectuur werd geïntroduceerd met versie 1.7.0, waarmee de monitoringfunctionaliteit voor MySQL, Galera Cluster, PostgreSQL en ProxySQL wordt uitgebreid.
De nieuwe ClusterControl 1.7.1 voegt monitoring met hoge resolutie toe aan MongoDB-systemen.
 ClusterControl MongoDB-dashboardlijst
ClusterControl MongoDB-dashboardlijst In dit artikel beschrijven we de twee belangrijkste dashboards voor MongoDB-omgevingen. MongoDB Server en MongoDB Replicaset.
Dashboard- en metrische lijst
De lijst met dashboards en hun statistieken:
| MongoDB-server | |
|---|---|
| Naam Naam opnieuw instellen Server-uptime OpsCounters Verbindingen WT - Gelijktijdige tickets (lezen) WT - Gelijktijdige tickets (schrijven) WT - Cache Global Lock Beweringen |
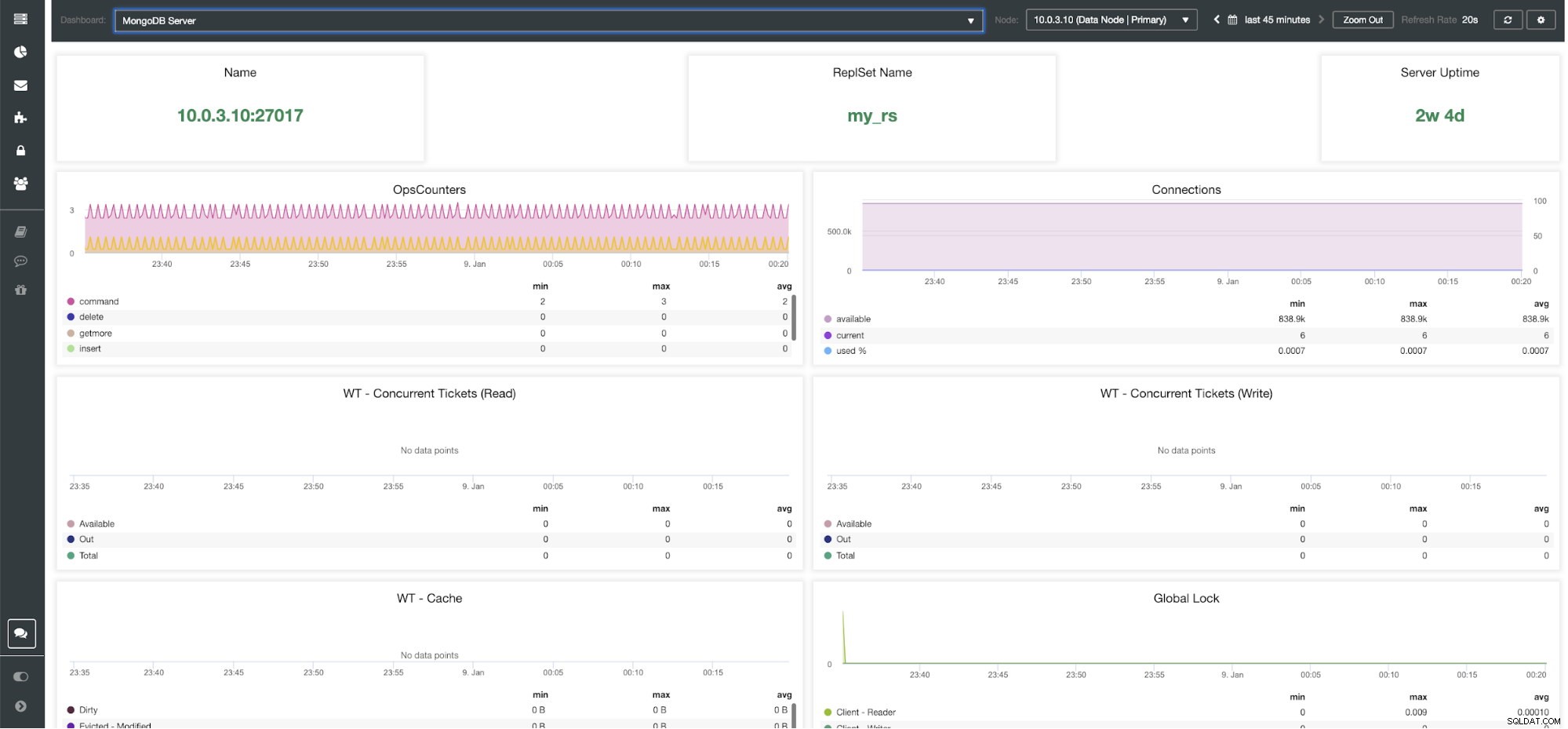 ClusterControl MongoDB-serverdashboard
ClusterControl MongoDB-serverdashboard| MongoDB ReplicaSet | |
|---|---|
| ReplSet-grootte ReplSet-naam PRIMAIRE Serverversie Replicasets en leden Oplogvenster per ReplSet Replicatieruimte Totaal PRIMAIRE/SECUNDAIRE online per ReplSet Cursors openen per ReplSet ReplSet - Time-out cursors per set Max. replicatievertraging per ReplSet Oplog-grootte OpsCounters Pingtijd voor replicasetleden van PRIMARY(s) |
 ClusterControl MongoDB ReplicaSet-dashboard
ClusterControl MongoDB ReplicaSet-dashboard Databasesystemen zijn sterk afhankelijk van OS-bronnen, dus u kunt ook twee extra dashboards vinden voor Systeemoverzicht en Clusteroverzicht van uw MongoDB-omgeving.
| Systeemoverzicht | |
|---|---|
| Server-uptime CPU-kernen Totaal RAM Gemiddeld laden CPU-gebruik RAM-gebruik Schijfruimtegebruik Netwerkgebruik Schijf-IOPS Schijf-IO Util % Schijfdoorvoer |
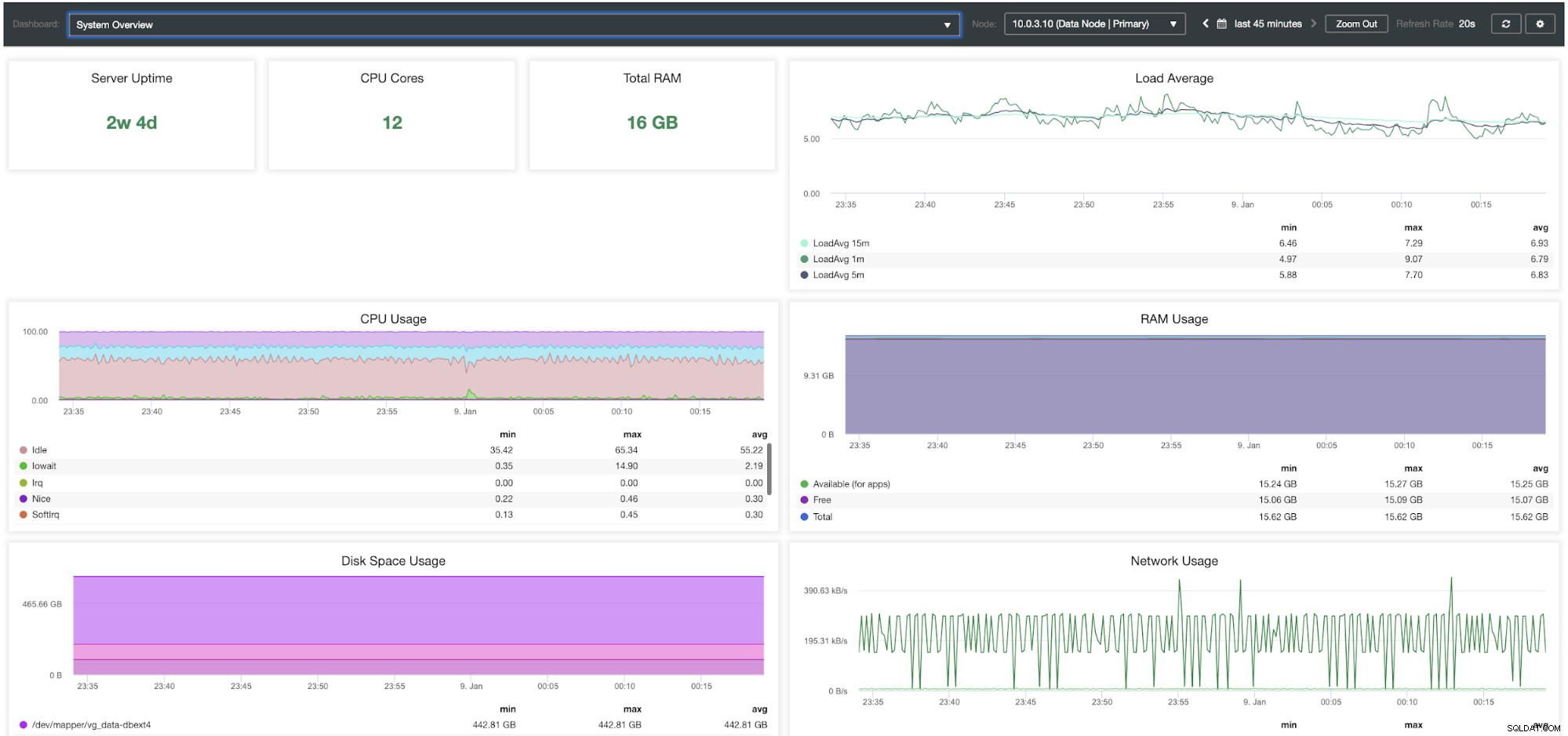 ClusterControl-systeemoverzicht Dashboard
ClusterControl-systeemoverzicht Dashboard| Clusteroverzicht | |
|---|---|
| Gemiddeld 1m laden Gemiddeld 5m laden Gemiddeld 15m laden Geheugen beschikbaar voor applicaties Netwerk TX Netwerk RX Schijf lezen IOPS Schijf schrijven IOPS Schijf schrijven + IOPS lezen |
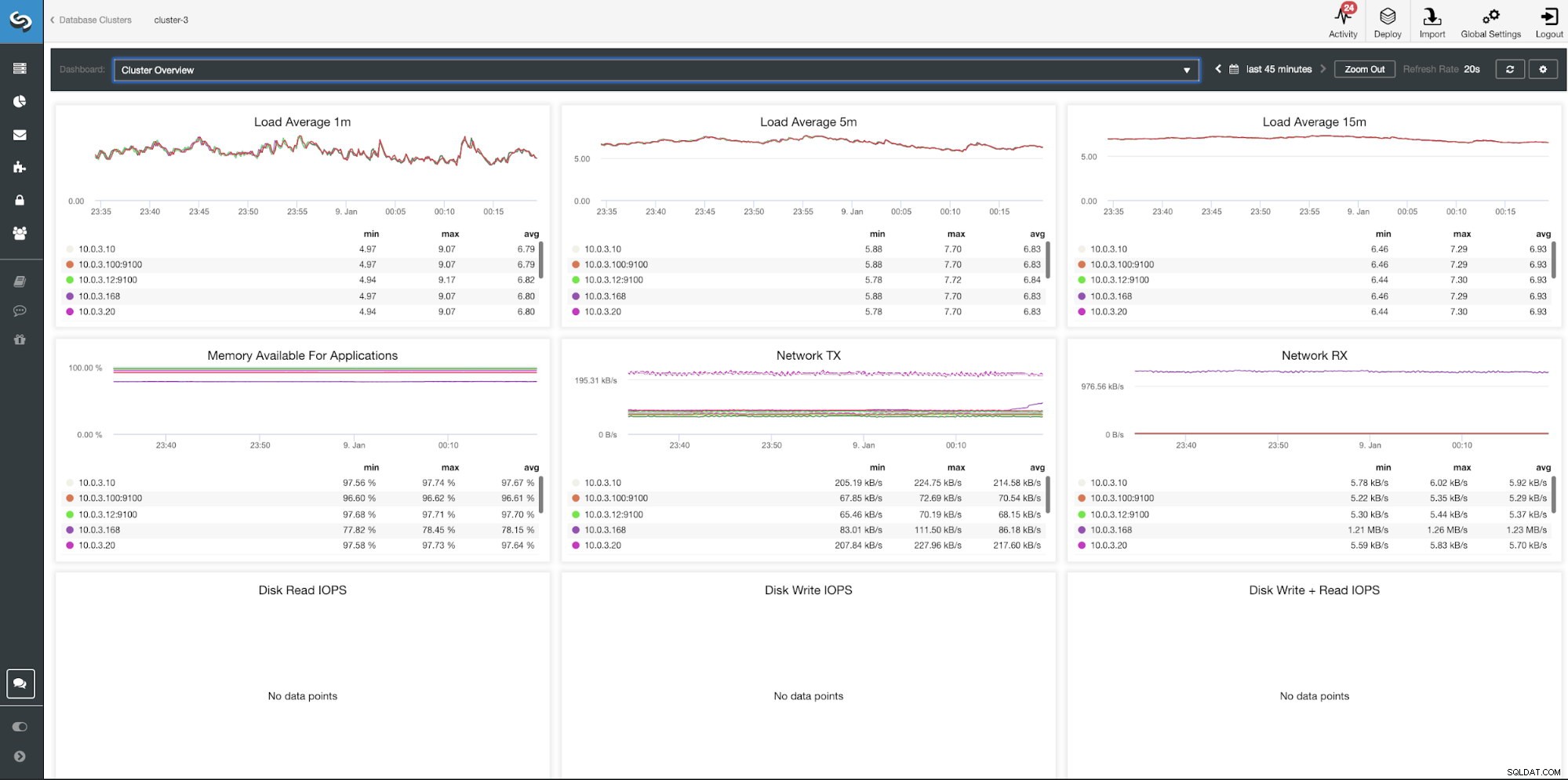 ClusterControl Clusteroverzicht Dashboard
ClusterControl Clusteroverzicht Dashboard MongoDB-serverdashboard
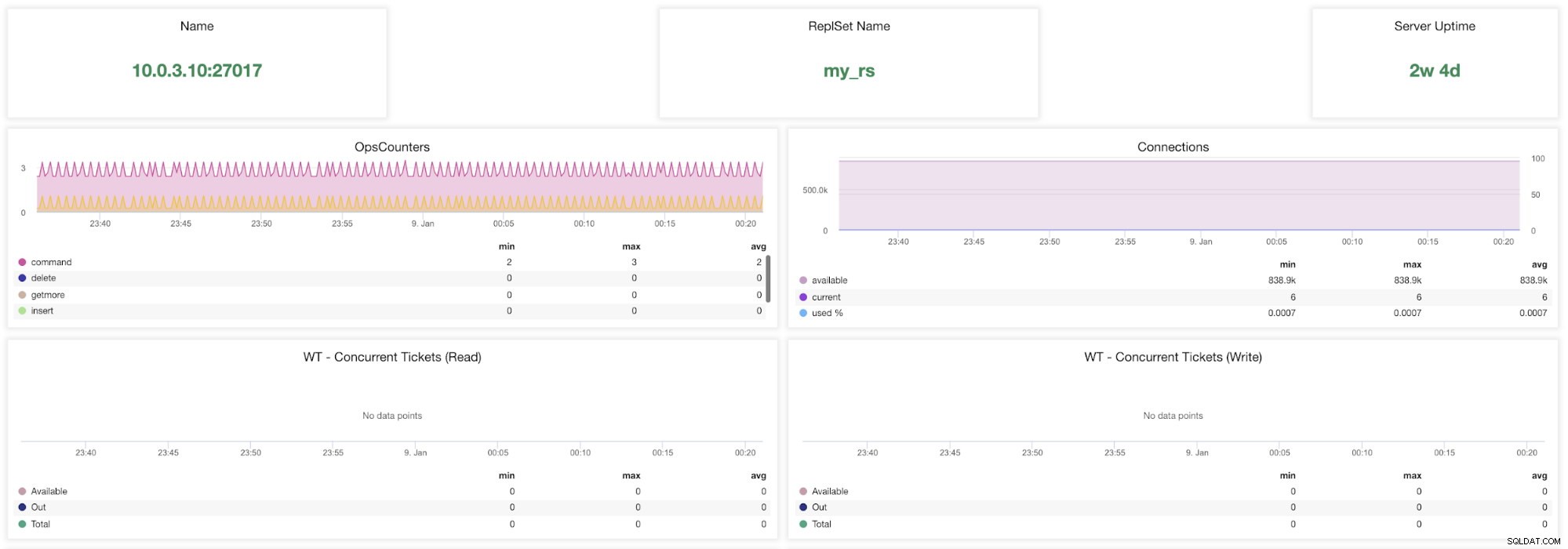 ClusterControl MongoDB-statistieken
ClusterControl MongoDB-statistieken Naam - Serveradres en de poort.
ReplsSet-naam - Geeft de naam weer van de replicaset waartoe de server behoort.
Server-uptime - Tijd sinds de laatste herstart van de server.
Ops-Couters - Aantal ontvangen verzoeken tijdens de geselecteerde periode, opgesplitst naar het type operatie. Deze tellingen omvatten alle ontvangen bewerkingen, inclusief bewerkingen die niet succesvol waren.
Verbindingen - Deze grafiek toont een van de belangrijkste statistieken om in de gaten te houden:het aantal verbindingen dat is ontvangen tijdens de geselecteerde periode, inclusief mislukte verzoeken. Abnormale verkeersbelastingen kunnen leiden tot prestatieproblemen. Als MongoDB weinig verbindingen heeft, kan het inkomende verzoeken mogelijk niet tijdig afhandelen.
WT - gelijktijdige tickets (lezen) / WT - gelijktijdige tickets (schrijven) Deze twee grafieken tonen lees- en schrijftickets die gelijktijdigheid in WiredTiger (WT) regelen. WT-tickets bepalen hoeveel lees- en schrijfbewerkingen tegelijkertijd op de opslagengine kunnen worden uitgevoerd. Wanneer beschikbare lees- en schrijftickets tot nul dalen, is het aantal gelijktijdig uitgevoerde bewerkingen gelijk aan de geconfigureerde lees-/schrijfwaarden. Dit betekent dat alle andere bewerkingen moeten wachten tot een van de actieve threads zijn werk op de opslagengine heeft voltooid voordat ze worden uitgevoerd.
 ClusterControl MongoDB-statistieken
ClusterControl MongoDB-statistieken WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - De grootte van de cache is de belangrijkste knop voor WiredTiger. Standaard reserveert MongoDB 3.x 50% (60% in 3.2) van het beschikbare geheugen voor zijn datacache.
Globaal slot (Client-Read, Client - Write, Current Queue - Reader, Current Queue - Writer) - Slechte schema-ontwerppatronen of zware lees- en schrijfverzoeken van veel clients kunnen uitgebreide vergrendeling veroorzaken. Wanneer dit gebeurt, is het nodig om consistentie te behouden en schrijfconflicten te vermijden.
Om dit te bereiken gebruikt MongoDB multi-granularity-locking, waardoor vergrendelingsoperaties op verschillende niveaus kunnen plaatsvinden, zoals een globaal, database- of verzamelingsniveau .
Beweringen (bericht, normaal, rollovers, gebruiker) - Deze grafiek toont het aantal beweringen dat elke seconde wordt verhoogd. Hoge waarden en afwijkingen van trends moeten worden beoordeeld.
MongoDB ReplicaSet-dashboard
De statistieken die in dit dashboard worden weergegeven, zijn alleen van belang als u een replicaset gebruikt.
 ClusterControl MongoDB ReplicaSet-statistieken
ClusterControl MongoDB ReplicaSet-statistieken ReplicaSet-grootte - Het aantal leden in de replicaset. De standaardimplementatie van replicasets voor het productiesysteem is een replicaset met drie leden. Over het algemeen wordt aanbevolen dat een replicaset een oneven aantal stemgerechtigde leden heeft. Fouttolerantie voor een replicaset is het aantal leden dat mogelijk niet meer beschikbaar is en toch voldoende leden in de set overlaat om een primaire te kiezen. De fouttolerantie voor drie leden is één, voor vijf is het twee enz.
ReplSet-naam - Het is de naam die is toegewezen in het MongoDB-configuratiebestand. De naam verwijst naar /etc/mongod.conf replSet waarde.
PRIMAIR - Het primaire knooppunt ontvangt alle schrijfbewerkingen en registreert alle andere wijzigingen in zijn gegevensset in zijn bewerkingslogboek. De waarde is om het IP-adres en de poort van uw primaire knooppunt in het MongoDB-replicasetcluster te identificeren.
Serverversie - Identificeer de serverversie. ClusterControl versie 1.7.1 ondersteunt MongoDB versies 3.2/3.4/3.6/4.0.
Replicasets en leden (min, max, gem) - Deze grafiek kan u helpen om actieve leden te identificeren over de tijdsperiode. U kunt het minimale, maximale en gemiddelde aantal primaire en secundaire knooppunten volgen en hoe deze aantallen in de loop van de tijd zijn veranderd. Elke afwijking kan de fouttolerantie en de beschikbaarheid van clusters beïnvloeden.
Oplog-venster per ReplSet - Replicatievenster is een essentiële statistiek om naar te kijken. De MongoDB-oplog is een enkele verzameling die is beperkt tot een (vooraf ingestelde) grootte. Het kan worden omschreven als het verschil tussen de eerste en de laatste tijdstempel in de oplog.rs. Dit is de hoeveelheid tijd die een secundaire offline kan zijn voordat de eerste synchronisatie nodig is om de instantie te synchroniseren. Deze statistieken geven aan hoeveel tijd je nog hebt voordat onze volgende transactie uit de oplog wordt verwijderd.
 ClusterControl MongoDB ReplicaSet-statistieken
ClusterControl MongoDB ReplicaSet-statistieken Replicatieruimte - Deze grafiek geeft het verschil weer tussen het oplogvenster van de primaire en de replicatievertraging van de secundaire knooppunten. De MongoDB-oplog is beperkt in omvang en als het knooppunt te ver achterblijft, kan het de achterstand niet inhalen. Als dit gebeurt, wordt volledige synchronisatie uitgevoerd en dit is een dure operatie die te allen tijde moet worden vermeden.
Totaal PRIMAIRE/SECUNDAIRE online per ReplSet - Totaal aantal clusterknooppunten gedurende de periode.
Cursors openen per ReplSet (vastgezet, time-out, totaal) - Een leesverzoek wordt geleverd met een cursor die een verwijzing is naar de dataset van het resultaat. Het blijft open op de server en verbruikt dus geheugen, tenzij het wordt beëindigd door de standaard MongoDB-instelling. Je zou niet-actieve cursors moeten identificeren en ze afknippen om geheugen te besparen.
ReplSet - Time-outcursors per set Max. Replicatievertraging per ReplSet - Replicatievertraging is erg belangrijk om in de gaten te houden als u uitlezingen uitschaalt door meer secondaries toe te voegen. MongoDB zal deze secondaries alleen gebruiken als ze niet te ver achterblijven. Als de secundaire replicatievertraging heeft, loopt u het risico verouderde gegevens op te leveren die al zijn overschreven op de primaire.
OplogSize - Voor bepaalde workloads is mogelijk een grotere oplog vereist. Updates voor meerdere documenten tegelijk, verwijderingen zijn gelijk aan dezelfde hoeveelheid gegevens als een invoeging of het aanzienlijke aantal interne updates.
OpsConters - Deze grafiek toont het aantal uitvoeringen van zoekopdrachten.
Pingtijd voor replicasetlid van primair - Hiermee kunt u replicasetleden ontdekken die niet beschikbaar zijn of niet bereikbaar zijn vanaf het primaire knooppunt.
Slotopmerkingen
De nieuwe ClusterControl 1.7.1 MongoDB-dashboardfunctie is gratis beschikbaar in de Community-editie. Database-ops-teams kunnen hiervan profiteren door grafieken met hoge resolutie te gebruiken, vooral bij het uitvoeren van hun dagelijkse routines als oorzaakanalyses en capaciteitsplanning.
Het is slechts een kwestie van één klik om nieuwe monitoring agents in te zetten. ClusterControl installeert Prometheus-agents, configureert metrische gegevens en onderhoudt toegang tot de configuratie van Prometheus-exporteurs via de GUI, zodat u de parameterconfiguratie zoals collectorvlaggen voor de exporteurs (Prometheus) beter kunt beheren.
Door het aantal lees- en schrijfverzoeken adequaat te monitoren, kunt u overbelasting van resources voorkomen, snel de oorzaak van mogelijke overbelasting vinden en weten wanneer u moet opschalen.