Het gebruik van replicatie voor uw PostgreSQL-databases kan niet alleen nuttig zijn om een hoge beschikbaarheid en fouttolerante omgeving te hebben, maar ook om de prestaties op uw systeem te verbeteren door het verkeer tussen de stand-by-knooppunten te verdelen. In dit eerste deel van de tweedelige blog gaan we enkele concepten zien die verband houden met de PostgreSQL-replicatie.
Replicatiemethoden in PostgreSQL
Er zijn verschillende methoden voor het repliceren van gegevens in PostgreSQL, maar hier zullen we ons concentreren op de twee belangrijkste methoden:streamingreplicatie en logische replicatie.
Streaming-replicatie
PostgreSQL-streamingreplicatie, de meest voorkomende PostgreSQL-replicatie, is een fysieke replicatie die de wijzigingen byte-voor-byte repliceert, waardoor een identieke kopie van de database op een andere server wordt gemaakt. Het is gebaseerd op de verzendmethode van het logboek. De WAL-records worden direct van de ene databaseserver naar de andere verplaatst om te worden toegepast. We kunnen zeggen dat het een soort continue PITR is.
Deze WAL-overdracht wordt op twee verschillende manieren uitgevoerd, door WAL-records één bestand (WAL-segment) per keer over te dragen (bestandsgebaseerde logverzending) en door WAL-records over te dragen (een WAL-bestand bestaat uit WAL-records) on-the-fly (op records gebaseerde logverzending), tussen een primaire server en een of meer dan op standby-servers, zonder te wachten tot het WAL-bestand is gevuld.
In de praktijk zal een proces met de naam WAL-ontvanger, dat draait op de standby-server, verbinding maken met de primaire server via een TCP/IP-verbinding. In de primaire server bestaat een ander proces, genaamd WAL-afzender, en is verantwoordelijk voor het verzenden van de WAL-registers naar de standby-server wanneer ze plaatsvinden.
Een standaard streaming-replicatie kan als volgt worden weergegeven:
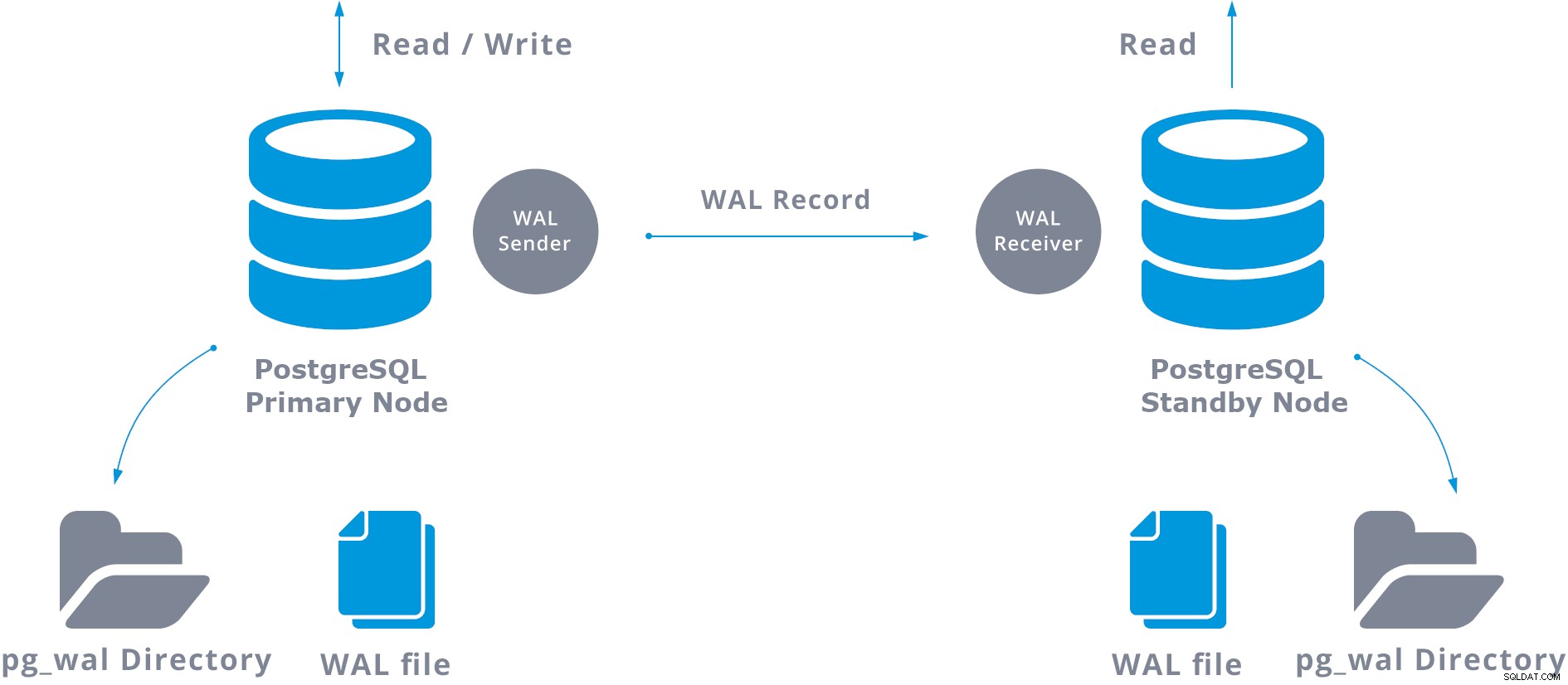
Bij het configureren van streamingreplicatie heeft u de mogelijkheid om WAL-archivering in te schakelen. Dit is niet verplicht, maar is uiterst belangrijk voor een robuuste replicatie-installatie, aangezien het noodzakelijk is om te voorkomen dat de hoofdserver oude WAL-bestanden recyclet die nog niet zijn toegepast op de standby-server. Als dit gebeurt, moet u de replica helemaal opnieuw maken.
Logische replicatie
Logische PostgreSQL-replicatie is een methode voor het repliceren van gegevensobjecten en hun wijzigingen op basis van hun replicatie-identiteit (meestal een primaire sleutel). Het is gebaseerd op een publicatie- en abonnementsmodus, waarbij een of meer abonnees zich abonneren op een of meer publicaties op een uitgeversknooppunt.
Een publicatie is een reeks wijzigingen die zijn gegenereerd op basis van een tabel of een groep tabellen. Het knooppunt waar een publicatie is gedefinieerd, wordt uitgever genoemd. Een abonnement is de downstream-kant van logische replicatie. Het knooppunt waar een abonnement is gedefinieerd, wordt de abonnee genoemd en definieert de verbinding met een andere database en reeks publicaties (een of meer) waarop het zich wil abonneren. Abonnees halen gegevens uit de publicaties waarop ze geabonneerd zijn.
Logische replicatie is gebouwd met een architectuur die vergelijkbaar is met fysieke streamingreplicatie. Het wordt geïmplementeerd door "walsender" en "apply"-processen. Het walsender-proces start de logische decodering van de WAL en laadt de standaard plug-in voor logische decodering. De plug-in transformeert de gelezen wijzigingen van WAL naar het logische replicatieprotocol en filtert de gegevens volgens de publicatiespecificatie. De gegevens worden vervolgens continu overgedragen met behulp van het streaming-replicatieprotocol naar de toepassingswerker, die de gegevens toewijst aan lokale tabellen en de individuele wijzigingen toepast zodra ze worden ontvangen, in een correcte transactievolgorde.
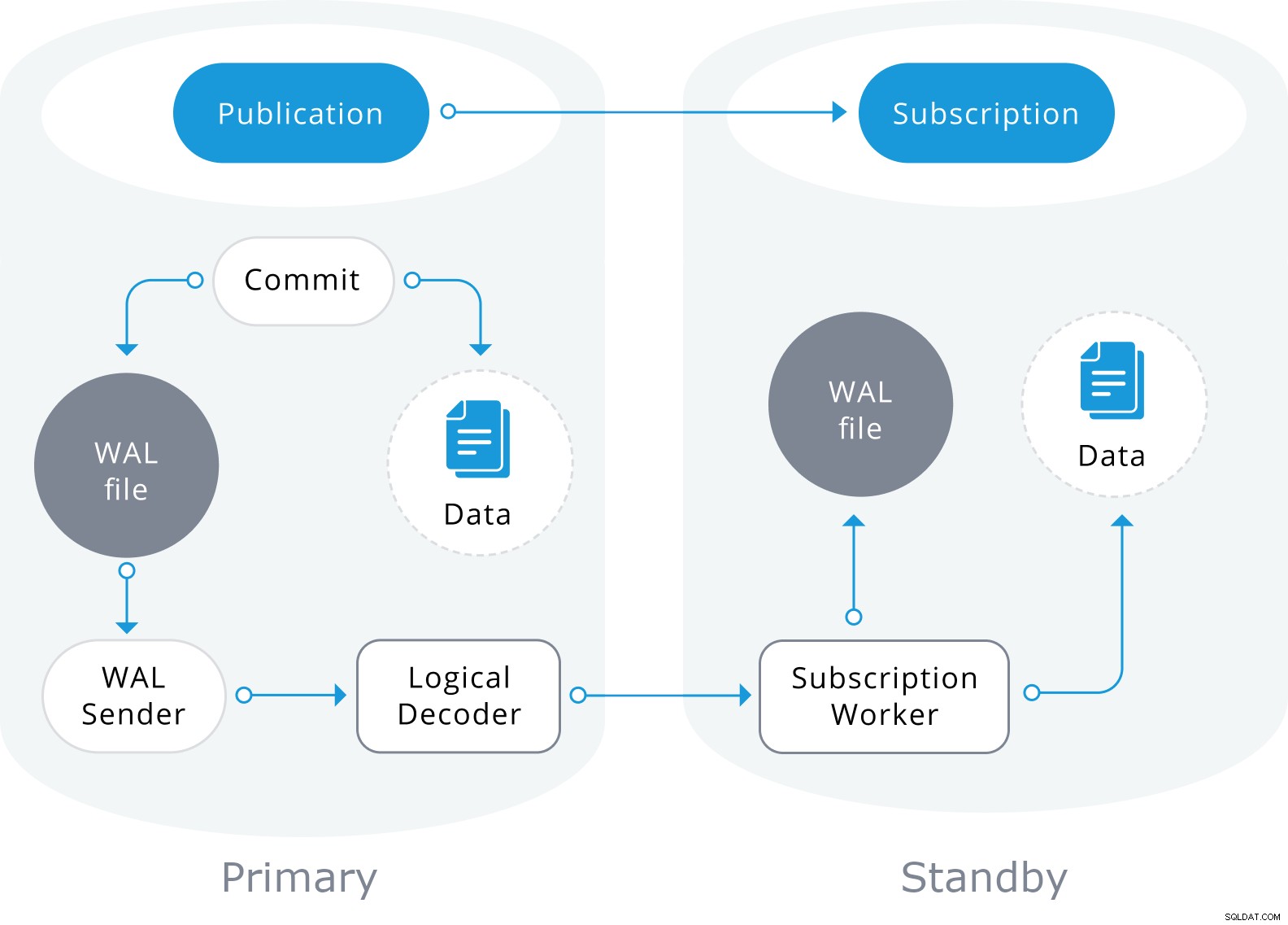
Logische replicatie begint met het maken van een momentopname van de gegevens in de uitgeversdatabase en kopiëren naar de abonnee. De initiële gegevens in de bestaande geabonneerde tabellen worden snapshots genomen en gekopieerd in een parallelle instantie van een speciaal soort toepassingsproces. Dit proces maakt een eigen tijdelijke replicatiesleuf en kopieert de bestaande gegevens. Zodra de bestaande gegevens zijn gekopieerd, gaat de werknemer naar de synchronisatiemodus, die ervoor zorgt dat de tabel in een gesynchroniseerde staat wordt gebracht met het hoofdtoepassingsproces door alle wijzigingen die tijdens de eerste gegevenskopie hebben plaatsgevonden, te streamen met behulp van standaard logische replicatie. Zodra de synchronisatie is voltooid, wordt de controle over de replicatie van de tabel teruggegeven aan het hoofdtoepassingsproces waar de replicatie gewoon doorgaat. De wijzigingen op de uitgever worden in realtime naar de abonnee verzonden.
Replicatiemodi in PostgreSQL
De replicatie in PostgreSQL kan synchroon of asynchroon zijn.
Asynchrone replicatie
Dit is de standaardmodus. Hier is het mogelijk om sommige transacties in het primaire knooppunt te laten vastleggen die nog niet zijn gerepliceerd naar de standby-server. Dit betekent dat er een kans is op mogelijk gegevensverlies. Deze vertraging in het commit-proces wordt verondersteld erg klein te zijn als de standby-server krachtig genoeg is om de belasting bij te houden. Als dit kleine risico op gegevensverlies niet acceptabel is in het bedrijf, kunt u in plaats daarvan synchrone replicatie gebruiken.
Synchrone replicatie
Elke vastlegging van een schrijftransactie zal wachten tot de bevestiging dat de vastlegging is geschreven naar het vooruitschrijflogboek op schijf van zowel de primaire als de standby-server. Deze methode minimaliseert de kans op gegevensverlies. Om gegevensverlies te laten optreden, moeten zowel de primaire als de stand-by tegelijkertijd uitvallen.
Het nadeel van deze methode is hetzelfde voor alle synchrone methodes, aangezien bij deze methode de responstijd voor elke schrijftransactie toeneemt. Dit is te wijten aan de noodzaak om te wachten tot alle bevestigingen dat de transactie is gepleegd. Gelukkig worden alleen-lezen transacties hierdoor niet beïnvloed, maar; alleen de schrijftransacties.
Hoge beschikbaarheid voor PostgreSQL-replicatie
Hoge beschikbaarheid is een vereiste voor veel systemen, ongeacht welke technologie we gebruiken, en er zijn verschillende benaderingen om dit te bereiken met verschillende tools.
Load Balancing
Load balancers zijn tools die kunnen worden gebruikt om het verkeer van uw applicatie te beheren om het meeste uit uw database-architectuur te halen. Het is niet alleen handig voor het balanceren van de belasting van onze databases, het helpt ook om applicaties om te leiden naar de beschikbare/gezonde nodes en zelfs om poorten met verschillende rollen te specificeren.
HAProxy is een load balancer die verkeer van de ene herkomst naar een of meer bestemmingen verdeelt en specifieke regels en/of protocollen voor deze taak kan definiëren. Als een van de bestemmingen niet meer reageert, wordt deze gemarkeerd als offline en wordt het verkeer naar de overige beschikbare bestemmingen gestuurd. Het hebben van slechts één Load Balancer-knooppunt genereert een Single Point of Failure, dus om dit te voorkomen, moet u ten minste twee HAProxy-knooppunten implementeren en Keepalive daartussen configureren.
Keepalived is een service waarmee we een virtueel IP-adres kunnen configureren binnen een actieve/passieve groep servers. Dit virtuele IP-adres is toegewezen aan een actieve server. Als deze server uitvalt, wordt het IP automatisch gemigreerd naar de "Secundaire" passieve server, waardoor deze op een transparante manier voor de systemen met hetzelfde IP kan blijven werken.
Prestaties verbeteren op PostgreSQL-replicatie
Prestaties zijn altijd belangrijk in elk systeem. U zult de beschikbare middelen goed moeten gebruiken om de best mogelijke responstijd te garanderen en er zijn verschillende manieren om dit te doen. Elke verbinding met een database verbruikt bronnen, dus een van de manieren om de prestaties van uw PostgreSQL-database te verbeteren, is door een goede verbindingspooler te hebben tussen uw toepassing en de databaseservers.
Verbindingspoolers
Een pooling van verbindingen is een methode om een pool van verbindingen te maken en deze opnieuw te gebruiken, waarbij wordt vermeden dat er steeds nieuwe verbindingen met de database moeten worden geopend, wat de prestaties van uw toepassingen aanzienlijk zal verbeteren. PgBouncer is een populaire pooler voor verbindingen die is ontworpen voor PostgreSQL.
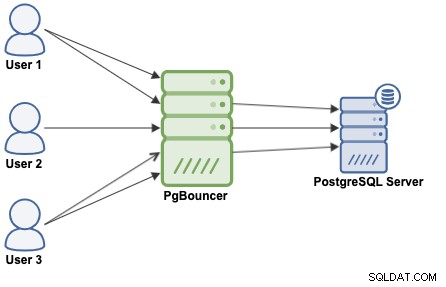
PgBouncer fungeert als een PostgreSQL-server, dus u hoeft alleen maar toegang te krijgen tot uw database met behulp van de PgBouncer-informatie (IP-adres/hostnaam en poort), en PgBouncer zal een verbinding maken met de PostgreSQL-server, of deze opnieuw gebruiken als deze bestaat.
Wanneer PgBouncer een verbinding ontvangt, voert het de authenticatie uit, die afhangt van de methode gespecificeerd in het configuratiebestand. PgBouncer ondersteunt alle authenticatiemechanismen die de PostgreSQL-server ondersteunt. Hierna controleert PgBouncer op een gecachte verbinding, met dezelfde gebruikersnaam + database-combinatie. Als er een verbinding in de cache wordt gevonden, wordt de verbinding naar de client geretourneerd, zo niet, dan wordt een nieuwe verbinding gemaakt. Afhankelijk van de PgBouncer-configuratie en het aantal actieve verbindingen, kan het zijn dat de nieuwe verbinding in de wachtrij wordt geplaatst totdat deze kan worden gemaakt of zelfs wordt afgebroken.
Met al deze genoemde concepten zullen we in het tweede deel van deze blog zien hoe je ze kunt combineren om een goede replicatieomgeving in PostgreSQL te hebben.