Hoewel in de toekomst de meeste databaseservers (vooral degenen die OLTP-achtige workloads verwerken) een op flash gebaseerde opslag zullen gebruiken, zijn we er nog niet - flashopslag is nog steeds aanzienlijk duurder dan traditionele harde schijven, en zoveel systemen gebruiken een mix van van SSD- en HDD-schijven. Dat betekent echter dat we moeten beslissen hoe we de database moeten splitsen - wat moet er naar de draaiende roest (HDD) en wat is een goede kandidaat voor de flash-opslag die duurder is maar veel beter in het omgaan met willekeurige I/O.
Er zijn oplossingen die dit automatisch op opslagniveau proberen af te handelen door SSD's automatisch als cache te gebruiken, waardoor het actieve deel van de gegevens automatisch op SSD blijft staan. Opslagapparatuur / SAN's doen dit vaak intern, er zijn hybride SATA/SAS-schijven met grote HDD en kleine SSD in één pakket, en natuurlijk zijn er oplossingen om dit direct bij de host te doen – er is bijvoorbeeld dm-cache in Linux, LVM kreeg ook zo'n mogelijkheid (gebouwd bovenop dm-cache) in 2014, en natuurlijk heeft ZFS L2ARC.
Maar laten we al die automatische opties negeren, en laten we zeggen dat we twee apparaten rechtstreeks op het systeem hebben aangesloten:één gebaseerd op HDD's, de andere op flash gebaseerd. Hoe moet je de database splitsen om het meeste voordeel te halen uit de dure flash? Een veelgebruikt patroon is om dit te doen op objecttype, met name tabellen versus indexen. Dat is in het algemeen logisch, maar we zien vaak dat mensen indexen op de SSD-opslag plaatsen, omdat indexen worden geassocieerd met willekeurige I/O. Hoewel dit misschien redelijk lijkt, blijkt dit precies het tegenovergestelde te zijn van wat u zou moeten doen.
Laat me je een benchmark laten zien ...
Laat me dit demonstreren op een systeem met zowel HDD-opslag (RAID10 opgebouwd uit 4x 10k SAS-schijven) als een enkel SSD-apparaat (Intel S3700). Het systeem heeft 16 GB RAM, dus laten we pgbench gebruiken met schalen 300 (=4,5 GB) en 3000 (=45 GB), d.w.z. een die gemakkelijk in RAM en een veelvoud van RAM past. Laten we vervolgens tabellen en indexen op verschillende opslagsystemen plaatsen (met behulp van tablespaces) en de prestaties meten. Het databasecluster was redelijk geconfigureerd (gedeelde buffers, WAL-limieten enz.) met betrekking tot de hardwarebronnen. De WAL is op een apart SSD-apparaat geplaatst, aangesloten op een RAID-controller die wordt gedeeld met de SAS-schijven.
Op de kleine (4,5 GB) dataset zien de resultaten er als volgt uit (merk op dat de y-as begint bij 3000 tps):
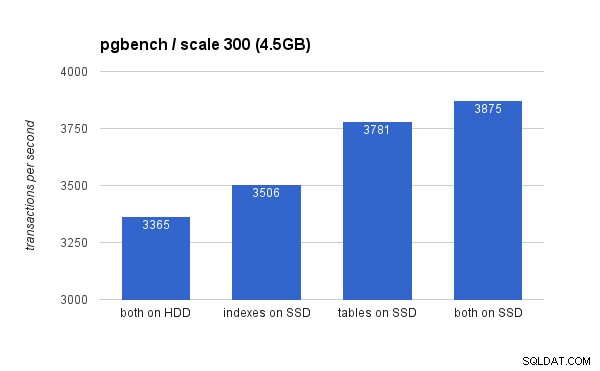
Het is duidelijk dat het plaatsen van de indexen op SSD een lager voordeel oplevert in vergelijking met het gebruik van de SSD voor tabellen. Hoewel de dataset gemakkelijk in RAM past, moeten de wijzigingen uiteindelijk naar schijf worden geschreven, en hoewel de RAID-controller een schrijfcache heeft, kan deze niet echt concurreren met de flash-opslag. Nieuwe RAID-controllers zouden waarschijnlijk iets beter presteren, maar dat geldt ook voor nieuwe SSD-schijven.
Op de grote dataset zijn de verschillen veel groter (deze keer begint de y-as bij 0):
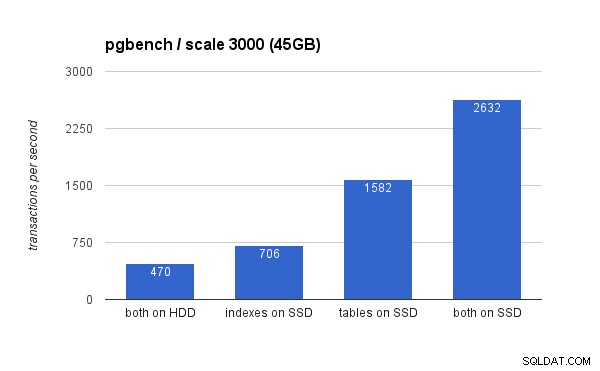
Het plaatsen van de indexen op SSD resulteert in een aanzienlijke prestatiewinst (bijna 50%, met HDD-opslag als basis), maar het verplaatsen van tabellen naar de SSD overtreft dat gemakkelijk door meer dan 200% te behalen. Als je zowel tabellen als index op SSD's plaatst, zul je de prestaties natuurlijk verder verbeteren, maar als je dat zou kunnen doen, hoef je je geen zorgen te maken over de andere gevallen.
Maar waarom?
Betere prestaties behalen door tabellen op SSD's te plaatsen, lijkt misschien een beetje contra-intuïtief, dus waarom gedraagt het zich zo? Nou, het is waarschijnlijk een combinatie van verschillende factoren:
- indexen zijn meestal veel kleiner dan tabellen en passen dus gemakkelijker in het geheugen
- de pagina's in indexniveaus (in de boomstructuur) zijn meestal behoorlijk populair en blijven dus in het geheugen
- bij het scannen en indexeren is veel van de daadwerkelijke I/O sequentieel van aard (vooral voor bladpagina's)
Het gevolg hiervan is dat een verrassende hoeveelheid I/O tegen indexen ofwel helemaal niet gebeurt (dankzij caching) of sequentieel is. Aan de andere kant zijn indexen een geweldige bron van willekeurige I/O tegen de tabellen.
Het is echter ingewikkelder ...
Dit was natuurlijk maar een simpel voorbeeld, en de conclusies kunnen bijvoorbeeld verschillen voor aanzienlijk verschillende workloads. Evenzo, aangezien SSD's duurder zijn, hebben systemen over het algemeen meer schijfruimte op HDD-schijven dan op SSD-schijven, dus tabellen passen mogelijk niet op de SSD, terwijl indexen dat wel zouden doen. In die gevallen is een meer uitgebreide plaatsing nodig, bijvoorbeeld niet alleen rekening houdend met het type object, maar ook hoe vaak het wordt gebruikt (en alleen de veelgebruikte tabellen naar SSD's verplaatsen), of zelfs subsets van tabellen (bijvoorbeeld door geleidelijk oude gegevens van SSD naar HDD).