In het eerste deel van deze blog hebben we enkele belangrijke concepten genoemd met betrekking tot een goede PostgreSQL-replicatieomgeving. Laten we nu eens kijken hoe we al deze dingen op een eenvoudige manier kunnen combineren met ClusterControl. Hiervoor gaan we ervan uit dat je ClusterControl hebt geïnstalleerd, maar als dat niet het geval is, kun je naar de officiële site gaan of de officiële documentatie raadplegen om het te installeren.
PostgreSQL-streamingreplicatie implementeren
Als u een implementatie van een PostgreSQL-cluster vanuit ClusterControl wilt uitvoeren, selecteert u de optie Deploy en volgt u de instructies die verschijnen.
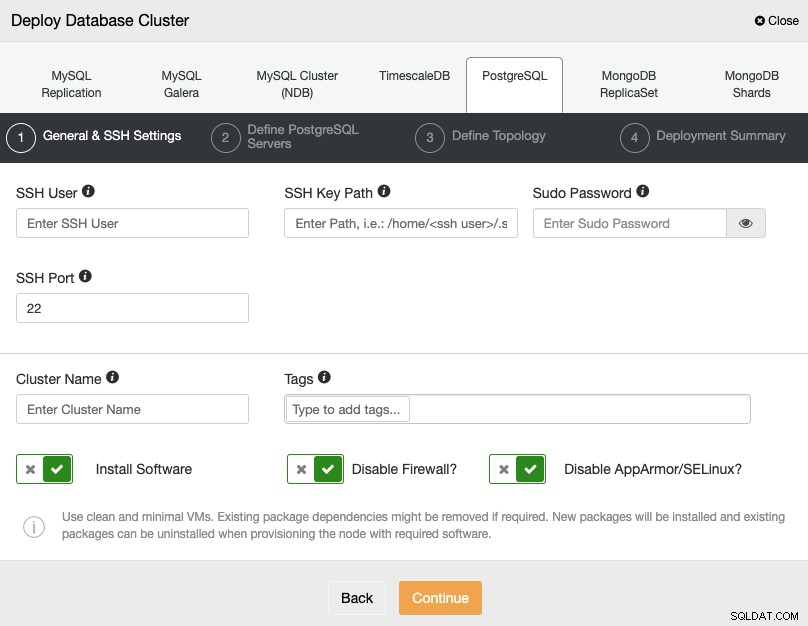
Als u PostgreSQL selecteert, moet u de gebruiker, de sleutel of het wachtwoord opgeven en Poort om via SSH verbinding te maken met uw servers. U kunt ook een naam voor uw nieuwe cluster toevoegen en aangeven of u wilt dat ClusterControl de bijbehorende software en configuraties voor u installeert.
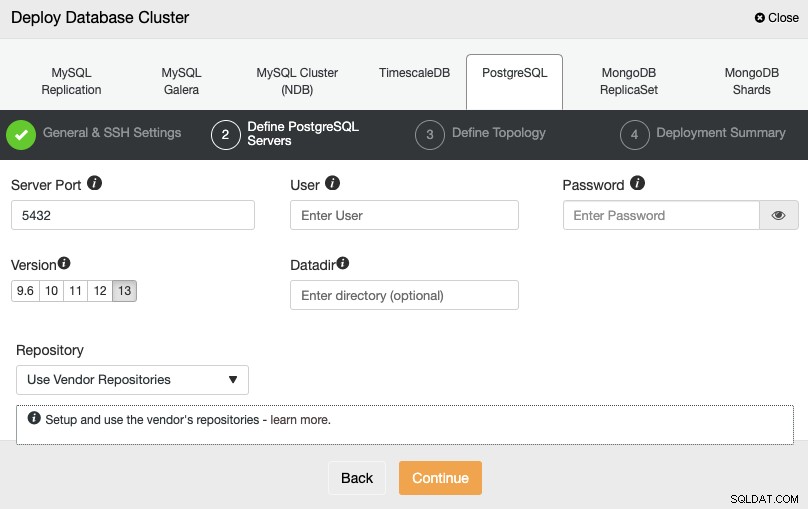
Na het instellen van de SSH-toegangsinformatie, moet u de databasereferenties definiëren , versie en datadir (optioneel). Je kunt ook aangeven welke repository je wilt gebruiken.
In de volgende stap moet u uw servers toevoegen aan het cluster dat u gaat maken met behulp van het IP-adres of de hostnaam.
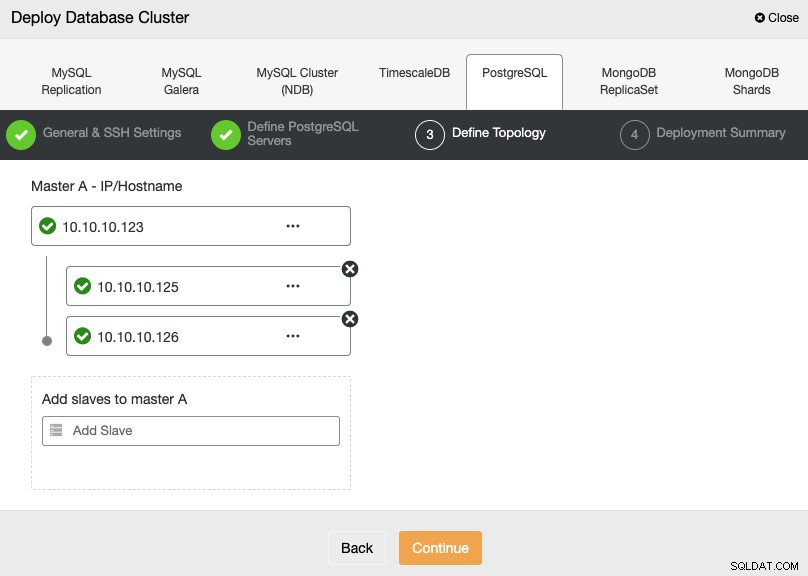
In de laatste stap kunt u kiezen of uw replicatie Synchroon of Asynchroon, en druk dan gewoon op Deploy.
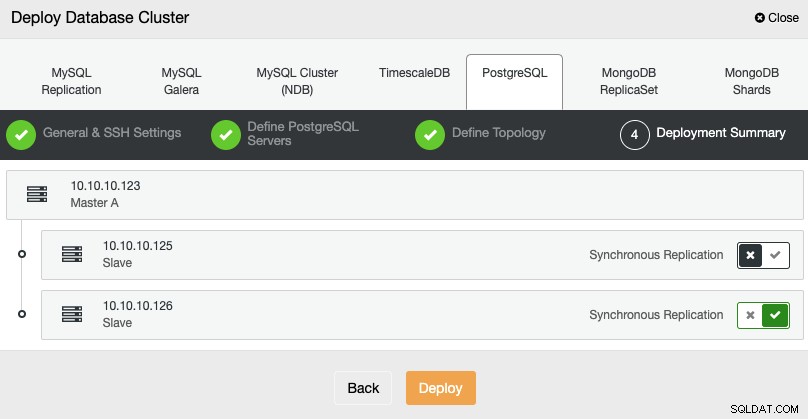
Zodra de taak is voltooid, ziet u uw nieuwe PostgreSQL-cluster in het hoofdscherm van ClusterControl.

Nu je je cluster hebt gemaakt, kun je er verschillende taken op uitvoeren, zoals het toevoegen van een load balancer (HAProxy), verbindingspooler (PgBouncer) of een nieuwe synchrone of asynchrone replicatieslave.
Synchroon en asynchrone replicatieslaves toevoegen
Ga naar ClusterControl -> Clusteracties -> Replicatieslave toevoegen.
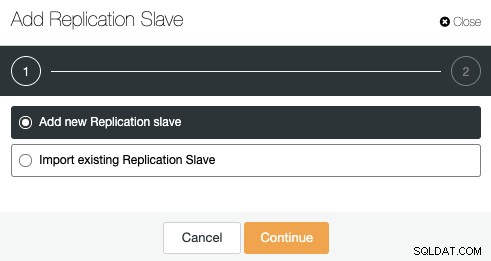
Je kunt een nieuwe replicatieslave toevoegen of zelfs een bestaande importeren. Laten we de eerste optie kiezen en doorgaan.
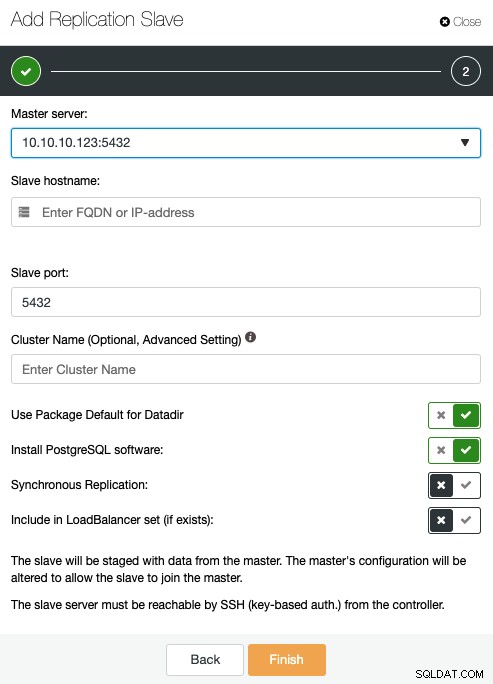
Hier moet u de hoofdserver, het IP-adres of de hostnaam van de nieuwe replicatie slave, poort, en als je wilt dat ClusterControl de software installeert, of deze node in een bestaande load balancer opneemt. U kunt de replicatie ook configureren om synchroon of asynchroon te zijn.
U heeft nu uw PostgreSQL-cluster met de bijbehorende replica's. Laten we eens kijken hoe u de prestaties kunt verbeteren door een verbindingspooler toe te voegen.
PgBouncer-implementatie
Ga naar ClusterControl -> Selecteer PostgreSQL-cluster -> Clusteracties -> Load Balancer toevoegen -> PgBouncer. Hier kunt u een nieuw PgBouncer-knooppunt implementeren dat in het geselecteerde databaseknooppunt wordt geïmplementeerd, of zelfs een bestaande PgBouncer importeren.
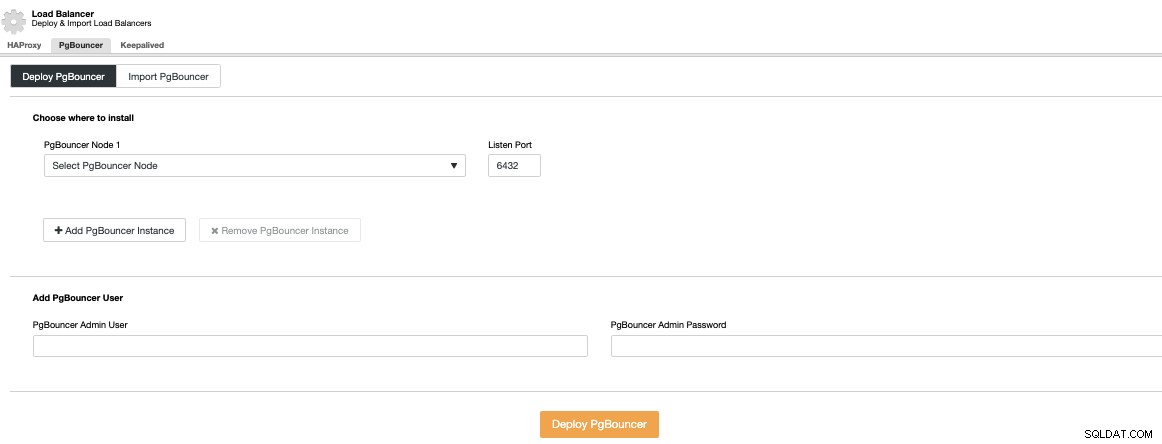
U moet een IP-adres of hostnaam, de luisterpoort en PgBouncer-referenties. Wanneer u op Deploy PgBouncer drukt, krijgt ClusterControl toegang tot het knooppunt, installeert en configureert alles zonder enige handmatige tussenkomst.
U kunt de voortgang volgen in de sectie ClusterControl-activiteit. Als het klaar is, moet u de nieuwe pool maken. Ga hiervoor naar ClusterControl -> Selecteer het PostgreSQL-cluster -> Nodes -> PgBouncer-knooppunt.
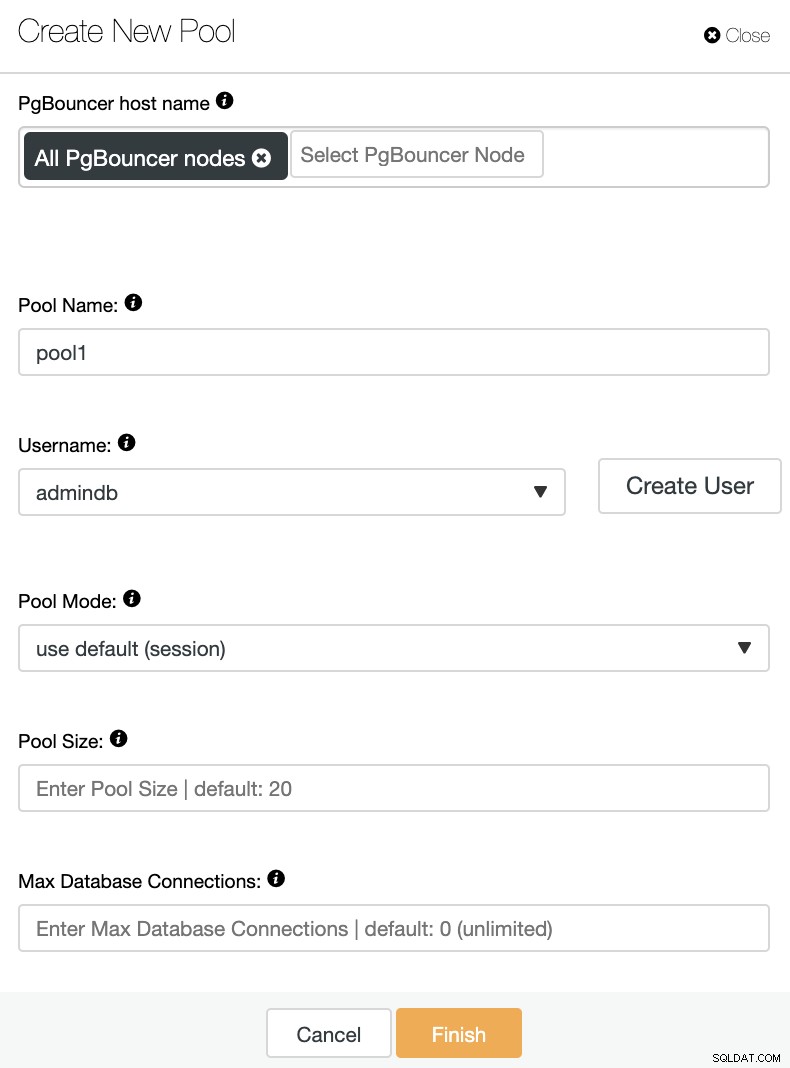
U moet de volgende informatie toevoegen:
-
PgBouncer-hostnaam:selecteer de node-hosts om de verbindingspool te maken.
-
Poolnaam:pool- en databasenamen moeten hetzelfde zijn.
-
Gebruikersnaam: Selecteer een gebruiker uit het primaire PostgreSQL-knooppunt of maak een nieuwe.
-
Poolmodus:dit kan zijn:sessie (standaard), transactie of pooling van overzichten.
-
Poolgrootte:maximale grootte van pools voor deze database. De standaardwaarde is 20.
-
Maximum databaseverbindingen:Configureer een databasebreed maximum. De standaardwaarde is 0, wat onbeperkt betekent.
Nu zou je de pool in de sectie Node moeten kunnen zien.
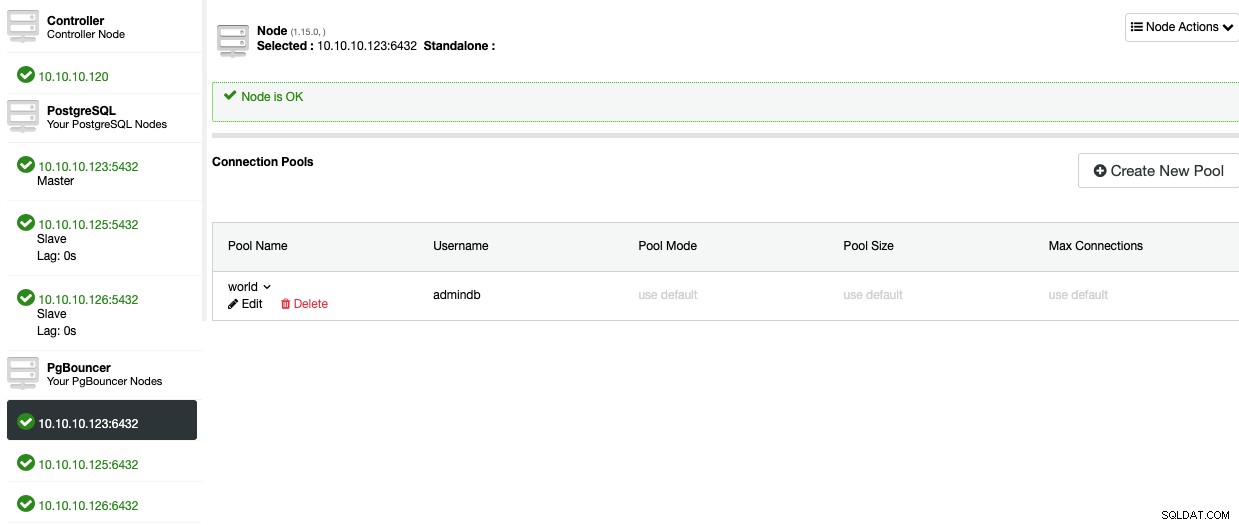
Laten we eens kijken hoe u een load balancer.
Load Balancer-implementatie
Als u een load balancer-implementatie wilt uitvoeren, selecteert u de optie Load Balancer toevoegen in het menu Clusteracties en vult u de gevraagde informatie in.
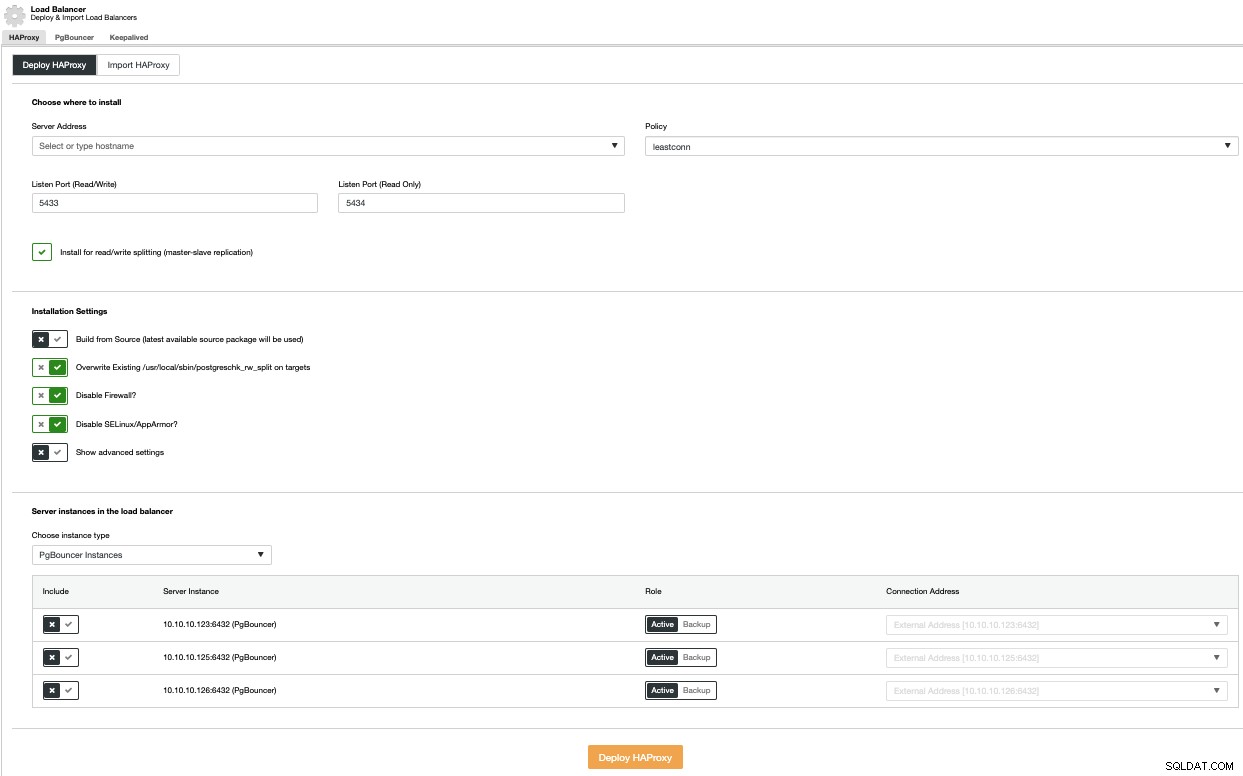
U moet IP of hostnaam, poort, beleid en de knooppunten toevoegen je gaat gebruiken. Als je PgBouncer gebruikt, kun je dit kiezen in de keuzelijst met instantietype.
Om een single point of failure te voorkomen, moet u ten minste twee HAProxy-knooppunten implementeren en Keepalive gebruiken waarmee u een virtueel IP-adres in uw toepassing kunt gebruiken dat is toegewezen aan het actieve HAProxy-knooppunt. Als dit knooppunt uitvalt, wordt het virtuele IP-adres gemigreerd naar de secundaire load balancer, zodat uw applicatie gewoon kan blijven werken.
Behoud implementatie
Als u een Keepalived-implementatie wilt uitvoeren, selecteert u de optie Load Balancer toevoegen in het menu Clusteracties en gaat u vervolgens naar het tabblad Keepalived.
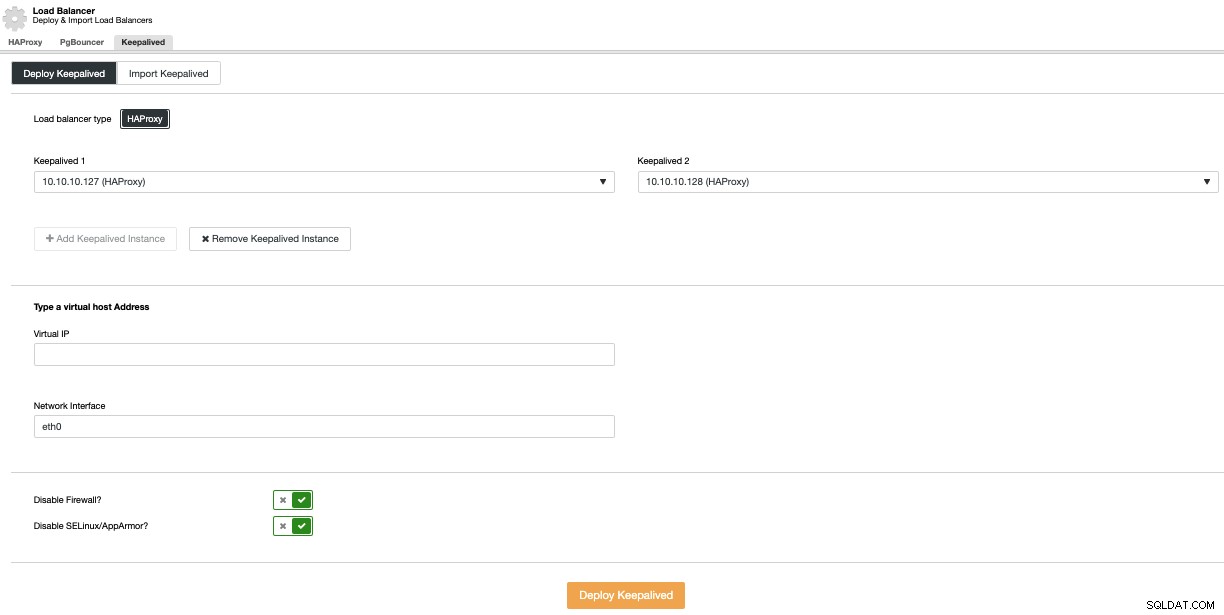
Selecteer hier de HAProxy-knooppunten en specificeer het virtuele IP-adres dat worden gebruikt om toegang te krijgen tot de database (of verbindingspooler).
Op dit moment zou je de volgende topologie moeten hebben:
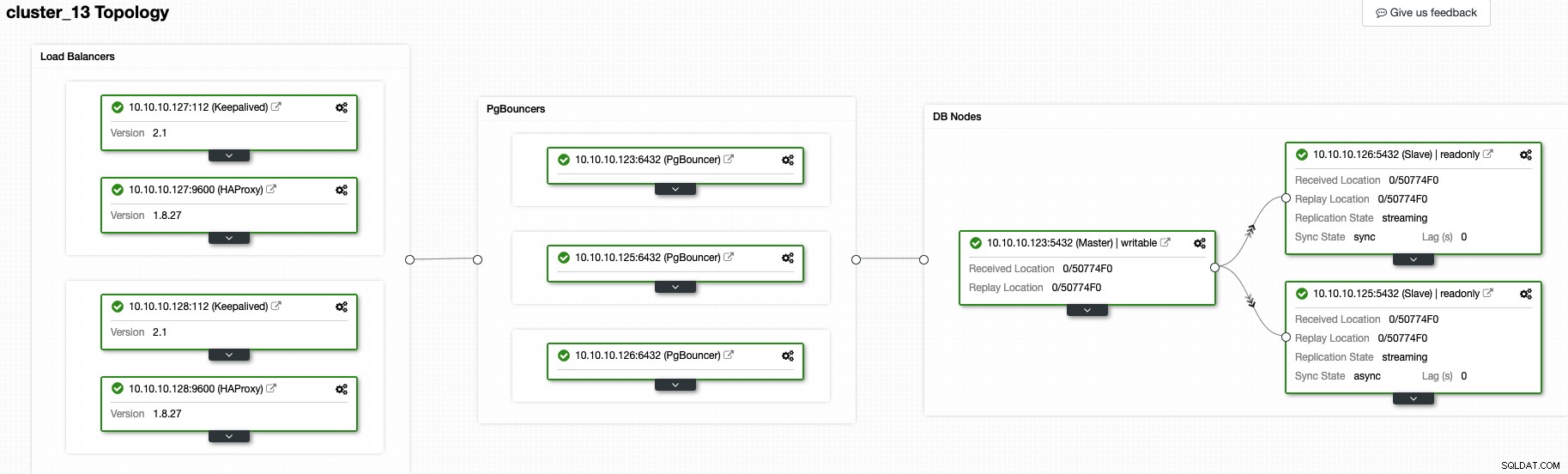
En dit betekent:HAProxy + Keepalived -> PgBouncer -> PostgreSQL-databaseknooppunten , dat is een goede topologie voor uw PostgreSQL-cluster.
ClusterControl-functie voor automatisch herstel
In geval van een storing, zal ClusterControl het meest geavanceerde stand-by-knooppunt promoveren naar primair en u op de hoogte stellen van het probleem. Het faalt ook om de rest van het standby-knooppunt te repliceren vanaf de nieuwe primaire server.
HAProxy is standaard geconfigureerd met twee verschillende poorten:lezen-schrijven en alleen-lezen. In de read-write poort heb je je primaire database (of PgBouncer) node als online en de rest van de nodes als offline, en in de read-only poort heb je zowel de primaire als de standby nodes online.
Wanneer HAProxy detecteert dat een van je nodes niet toegankelijk is, markeert het deze automatisch als offline en houdt er geen rekening mee voor het verzenden van verkeer ernaar. Detectie wordt uitgevoerd door scripts voor statuscontrole die zijn geconfigureerd door ClusterControl op het moment van implementatie. Deze controleren of de instanties actief zijn, of ze worden hersteld of alleen-lezen zijn.
Als ClusterControl een stand-by-knooppunt promoot, markeert HAProxy de oude primaire als offline voor beide poorten en plaatst het gepromote knooppunt online in de lees-schrijfpoort.
Als uw actieve HAProxy, waaraan een virtueel IP-adres is toegewezen waarmee uw systemen verbinding maken, faalt, migreert Keepalive dit IP-adres automatisch naar uw passieve HAProxy. Dit betekent dat uw systemen dan normaal kunnen blijven functioneren.
Conclusie
Zoals u kunt zien, is het hebben van een goede PostgreSQL-topologie eenvoudig als u ClusterControl gebruikt en als u de basisconcepten voor best practices voor PostgreSQL-replicatie volgt. De beste omgeving hangt natuurlijk af van de werklast, hardware, applicatie, enz., maar u kunt deze als voorbeeld gebruiken en de stukken verplaatsen naar behoefte.