Als uw systeem afhankelijk is van PostgreSQL en u op zoek bent naar clusteringoplossingen voor hoge beschikbaarheid, willen we u van tevoren laten weten dat het een complexe taak is, maar niet onmogelijk om te bereiken.
Gezien uw vereisten voor fouttolerantie, zijn hier enkele clusteringoplossingen met hoge beschikbaarheid waaruit u kunt kiezen die kunnen helpen.
PostgreSQL ondersteunt geen enkele multi-master clusteringoplossing zoals MySQL of Oracle. Desalniettemin bieden veel commerciële en gemeenschapsproducten deze implementatie, inclusief replicatie en taakverdeling voor PostgreSQL.
Laten we om te beginnen enkele basisconcepten bekijken:
Wat is hoge beschikbaarheid?
Hoge beschikbaarheid verwijst naar de hoeveelheid tijd dat een service beschikbaar is en wordt meestal bepaald door het overeengekomen prestatieniveau van een bedrijf.
Redundantie is de basis voor hoge beschikbaarheid; in het geval van een incident kunt u de systemen probleemloos blijven bedienen en benaderen.
Continu herstel
Als zich een incident voordoet en u een back-up moet terugzetten en vervolgens de WAL-logboeken (Write-Ahead Logging) moet toepassen, zou de hersteltijd erg hoog zijn en zou deze niet in hoge mate beschikbaar zijn.
Als je de back-ups en logs echter hebt gearchiveerd op een noodserver, kun je de logs toepassen zodra ze binnenkomen. Als de logboeken elke minuut worden verzonden en toegepast, zou de basis voor onvoorziene gebeurtenissen continu worden hersteld en zou de productie ten hoogste één minuut verouderd zijn.
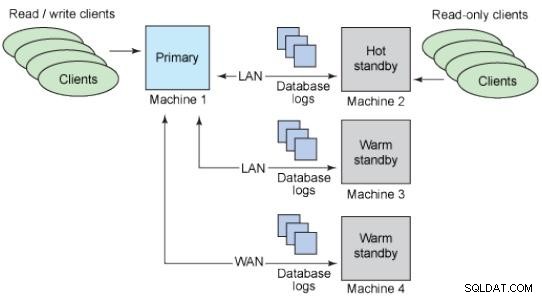
Stand-by-databases
Het idee van een standby-database is om een kopie te bewaren van een productiedatabase die altijd dezelfde gegevens heeft en klaar is om te worden gebruikt in geval van een incident.
Er zijn verschillende manieren om een standby-database te classificeren.
Door de aard van de replicatie:
-
Fysieke standbys:schijfblokken worden gekopieerd.
-
Logische standbys:streaming van de gegevenswijzigingen.
Door de synchroniciteit van de transacties:
-
Asynchroon:er is een mogelijkheid van gegevensverlies.
-
Synchroon:er is geen mogelijkheid tot gegevensverlies; De commits in de master wachten op de reactie van de standby.
Door het gebruik:
-
Warme standbys:ze ondersteunen geen verbindingen.
-
Hot standbys:ondersteuning voor alleen-lezen verbindingen.
Clusters
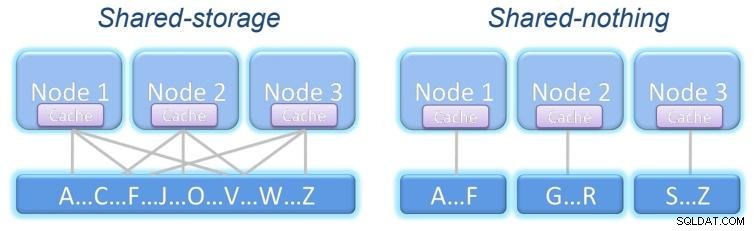
Een cluster is een groep hosts die samenwerken en als één worden gezien. Dit biedt een manier om horizontale schaalbaarheid te bereiken en de mogelijkheid om meer werk te verwerken door servers toe te voegen.
Het kan het falen van een knooppunt weerstaan en transparant blijven werken. Afhankelijk van wat er wordt gedeeld, zijn er twee clustermodellen:
-
Gedeelde opslag:alle nodes hebben toegang tot dezelfde opslag met dezelfde informatie.
-
Niets gedeeld:elk knooppunt heeft zijn eigen opslag, die al dan niet dezelfde informatie heeft als de andere knooppunten, afhankelijk van de structuur van ons systeem.
Laten we nu enkele van de clusteringopties bekijken die we in PostgreSQL hebben.
Gedistribueerd gerepliceerd blokapparaat
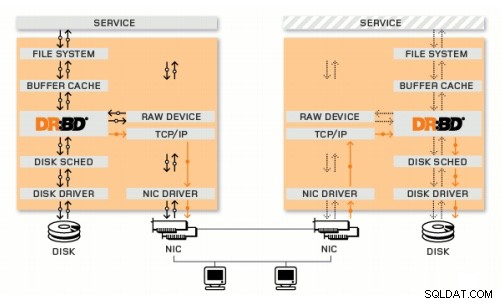
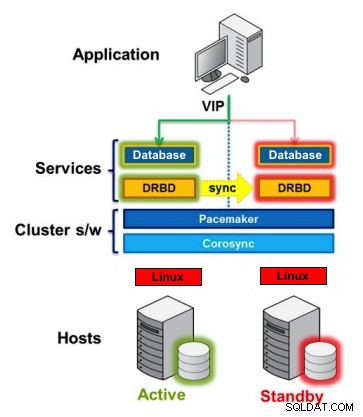
DRBD is een Linux-kernelmodule die synchrone blokreplicatie implementeert met behulp van het netwerk. Het implementeert eigenlijk geen cluster en behandelt geen failover of monitoring. Daar heb je aanvullende software voor nodig, bijvoorbeeld Corosync + Pacemaker + DRBD.
Voorbeeld:
-
Corosync:verwerkt berichten tussen hosts.
-
Pacemaker:start en stopt services en zorgt ervoor dat ze slechts op één host draaien.
-
DRBD:synchroniseert de gegevens op het niveau van blokapparaten.
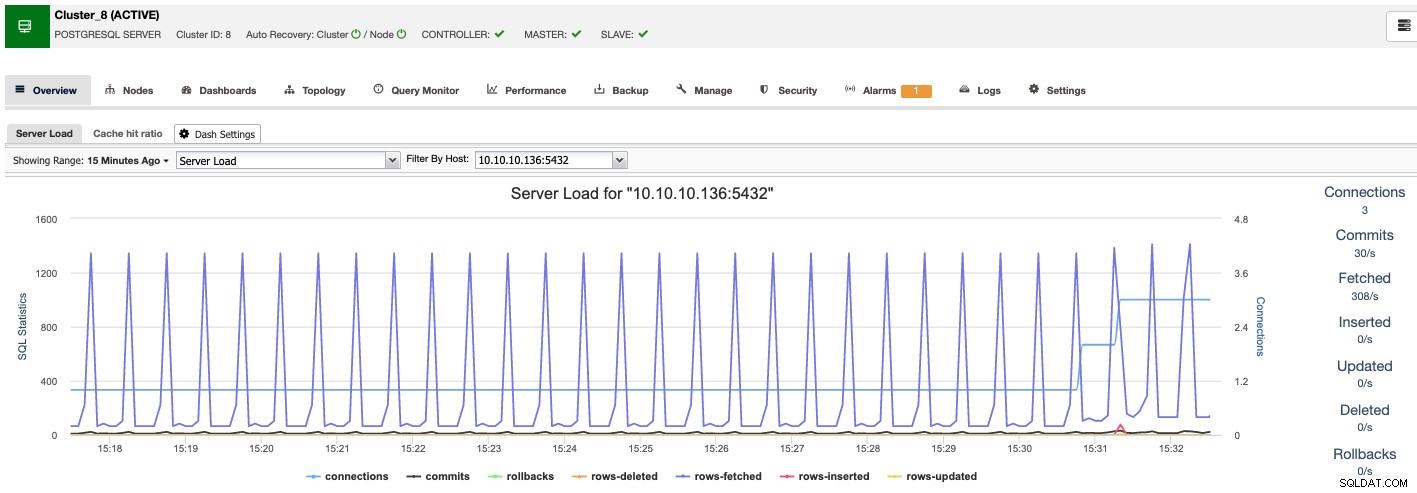
ClusterControl
ClusterControl is agentless beheer- en automatiseringssoftware voor databaseclusters. Het helpt bij het implementeren, bewaken, beheren en schalen van uw databaseserver/cluster rechtstreeks vanuit de gebruikersinterface. Het kan de meeste beheertaken aan die nodig zijn om databaseservers of clusters te onderhouden.
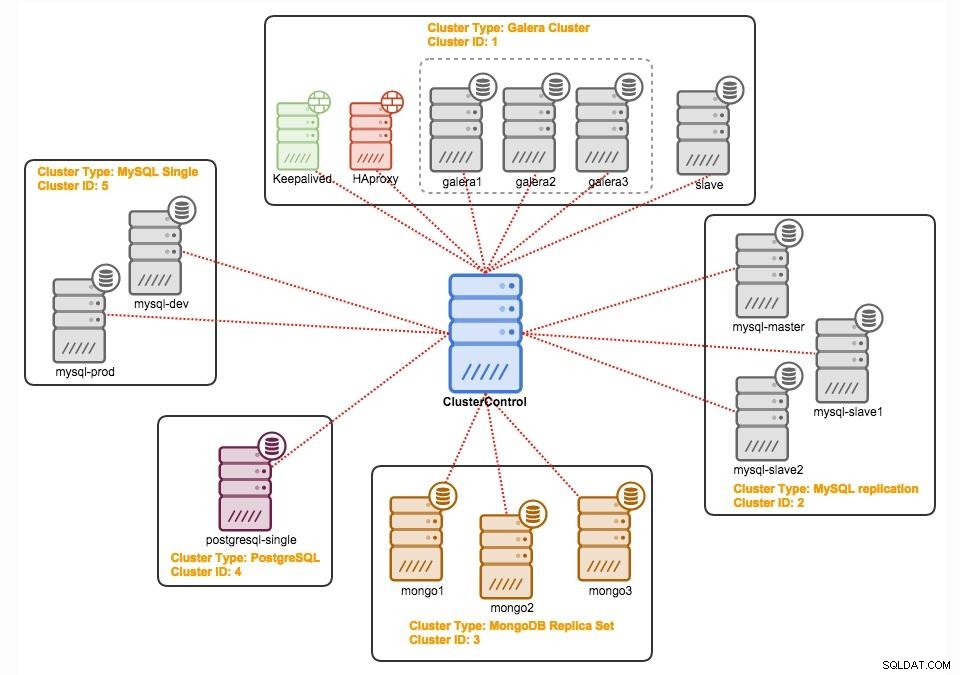
Met ClusterControl kunt u:
-
Implementeer zelfstandige, gerepliceerde of geclusterde databases op de technologiestack van uw keuze.
-
Automatiseer failovers, herstel en dagelijkse taken uniform in polyglot-databases en dynamische infrastructuren.
-
Maak volledige of incrementele back-ups handmatig of plan ze.
-
Voer uniforme en uitgebreide realtime monitoring uit van uw volledige database- en serverinfrastructuur.
-
Voeg eenvoudig een knooppunt toe of verwijder het met een enkele handeling.
-
Kloon uw cluster naar een andere datacenter/cloudprovider
Als u een incident heeft op PostgreSQL, kan uw Standby-knooppunt automatisch worden gepromoveerd naar Primair.
Het is een complete tool die full-ops levenscyclusbeheer en automatisering biedt via één enkel venster. ClusterControl biedt ook een gratis proefperiode van 30 dagen, zodat u het vrijblijvend kunt evalueren.
Rubyrep
Rubyrep is een oplossing die asynchrone, multi-master, multi-platform replicatie (geïmplementeerd in Ruby of JRuby) en multi-DBMS (MySQL of PostgreSQL) biedt.
Het is gebaseerd op triggers en ondersteunt geen DDL, gebruikers of subsidies. De eenvoud van gebruik en beheer is het primaire doel.
Sommige functies omvatten:
-
Eenvoudige configuratie
-
Eenvoudige installatie
-
Platformonafhankelijk, tafelontwerp onafhankelijk.
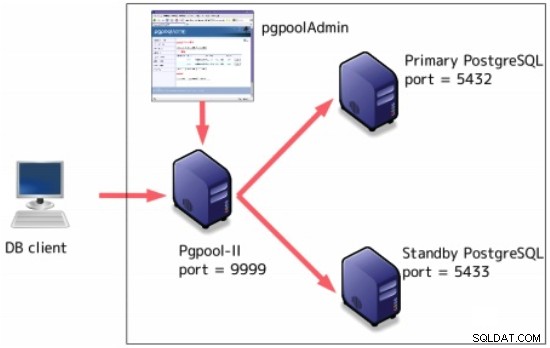
Pgpool-II
Pgpool-II is een middleware die werkt tussen PostgreSQL-servers en een PostgreSQL-databaseclient.
Sommige functies omvatten:
-
Verbindingspool
-
Replicatie
-
Belastingsverdeling
-
Automatische failover
-
Parallelle zoekopdrachten
Het kan worden geconfigureerd bovenop streaming-replicatie:
Bucardo
Bucardo biedt asynchrone trapsgewijze master-slave-replicatie, op rijen gebaseerd, met behulp van triggers en wachtrijen in de database, en asynchrone master-master-replicatie, op rijen, met behulp van triggers en aangepaste conflictoplossing.
Bucardo vereist een speciale database en draait als een Perl-daemon die communiceert met deze database en alle andere databases die betrokken zijn bij de replicatie. Het kan werken als multi-master of multi-slave.
Master-slave-replicatie houdt in dat een of meer bronnen naar een of meer doelen gaan. De bron moet PostgreSQL zijn, maar de doelen kunnen PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite of MongoDB zijn.
Sommige functies omvatten:
-
Belastingsverdeling
-
Slaven zijn niet beperkt en kunnen worden geschreven
-
Gedeeltelijke replicatie
-
Replicatie op aanvraag (wijzigingen kunnen automatisch of indien gewenst worden doorgevoerd)
-
Slaven kunnen worden "voorverwarmd" voor snelle installatie
Nadelen:
-
Kan DDL niet aan
-
Kan grote objecten niet aan
-
Kan tabellen niet stapsgewijs repliceren zonder een unieke sleutel
-
Werkt niet op versies ouder dan Postgres 8
Postgres-XC
Postgres-XC is een open-sourceproject om een schrijfbare, synchrone, symmetrische en transparante PostgreSQL-clusteroplossing te bieden. Het is een verzameling nauw gekoppelde databasecomponenten die op meer dan één hardware of virtuele machine kunnen worden geïnstalleerd.
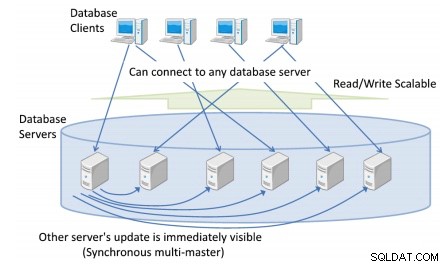
Schrijfschaalbaar betekent dat Postgres-XC kan worden geconfigureerd met zoveel databaseservers als u wilt en veel meer schrijfbewerkingen (bijwerken van SQL-instructies) kan verwerken in vergelijking met wat een enkele databaseserver kan doen.
U kunt meer dan één databaseserver hebben waarmee clients verbinding maken, zodat u een enkele, consistente clusterbrede weergave van de database krijgt.
Elke database-update van een databaseserver is onmiddellijk zichtbaar voor andere transacties die op verschillende masters worden uitgevoerd.
Transparant betekent dat u zich geen zorgen hoeft te maken over hoe uw gegevens intern op meer dan één databaseserver worden opgeslagen.
Je kunt Postgres-XC configureren om op meerdere servers te draaien. Uw gegevens worden gedistribueerd opgeslagen, gepartitioneerd of gerepliceerd, zoals u voor elke tabel kiest. Wanneer u query's uitgeeft, bepaalt Postgres-XC waar de doelgegevens worden opgeslagen en geeft de bijbehorende query's door aan servers die de doelgegevens bevatten.
Citus
Citus is een drop-in vervanging voor PostgreSQL met ingebouwde functies voor hoge beschikbaarheid, zoals auto-sharding en replicatie. Citus shards uw database en repliceert meerdere exemplaren van elke shard over het cluster van commodity-knooppunten. Als een knooppunt in het cluster niet meer beschikbaar is, leidt Citus alle schrijf- of query's transparant om naar een van de andere knooppunten die een kopie van de getroffen shard bevatten.
Sommige functies omvatten:
-
Automatische logische sharding
-
Ingebouwde replicatie
-
Datacenterbewuste replicatie voor noodherstel
-
Mid-query fouttolerantie met geavanceerde taakverdeling
U kunt de uptime van uw realtime applicaties, aangedreven door PostgreSQL, verhogen en de impact van hardwarestoringen op de prestaties minimaliseren. U kunt dit bereiken met ingebouwde tools voor hoge beschikbaarheid, waardoor kostbare en foutgevoelige handmatige interventie tot een minimum wordt beperkt.
PostgresXL
PostgresXL is een gedeelde-niets, multi-master clusteroplossing die transparant een tabel op een set knooppunten kan distribueren en parallel met die knooppunten query's kan uitvoeren. Het heeft een extra component genaamd Global Transaction Manager (GTM) voor het bieden van een wereldwijd consistent beeld van het cluster.
PostgresXL is een horizontaal schaalbaar open-source SQL-databasecluster, flexibel genoeg om verschillende database-workloads aan te kunnen:
-
OLTP schrijfintensieve workloads
-
Business Intelligence vereist MPP-parallellisme
-
Operationele datastore
-
Key-value store
-
GIS Geospatial
-
Mix-werkbelasting omgevingen
-
Door meerdere tenants gehoste omgevingen

Onderdelen:
-
Global Transaction Monitor (GTM):De Global Transaction Monitor zorgt voor clusterbrede transactieconsistentie.
-
Coördinator:de coördinator beheert de gebruikerssessies en communiceert met GTM en de gegevensknooppunten.
-
Dataknooppunt:het gegevensknooppunt is waar de daadwerkelijke gegevens worden opgeslagen.
Afronding
Er zijn nog veel meer producten beschikbaar om uw omgeving met hoge beschikbaarheid voor PostgreSQL te implementeren, maar u moet voorzichtig zijn met:
-
Nieuwe producten, niet voldoende getest
-
Beëindigde projecten
-
Beperkingen
-
Licentiekosten
-
Zeer complexe implementaties
-
Onveilige oplossingen
Houd bij het selecteren van de oplossing die u gaat gebruiken ook rekening met uw infrastructuur. Als u slechts één applicatieserver hebt, ongeacht hoeveel u de hoge beschikbaarheid van de databases hebt geconfigureerd, als de applicatieserver uitvalt, bent u ontoegankelijk. Je moet de single points of failure in de infrastructuur goed analyseren en proberen op te lossen.
Rekening houdend met deze punten, kunt u een clusteroplossing met hoge beschikbaarheid vinden die zich moeiteloos aanpast aan uw behoeften en vereisten. Als je op zoek bent naar extra HA-bronnen voor je PG-database, bekijk dan dit bericht over het inzetten van PostgreSQL voor hoge beschikbaarheid.
Volg ons op Twitter en LinkedIn en abonneer je op onze nieuwsbrief om op de hoogte te blijven van oplossingen voor databasebeheer en best practices.