Vraagt u zich af wat Postgresql-schema's zijn en waarom ze belangrijk zijn en hoe u schema's kunt gebruiken om uw database-implementaties robuuster en onderhoudbaarder te maken? Dit artikel introduceert de basisprincipes van schema's in Postgresql en laat je zien hoe je ze kunt maken met enkele basisvoorbeelden. Toekomstige artikelen zullen ingaan op voorbeelden van het beveiligen en gebruiken van schema's voor echte toepassingen.
Ten eerste, om mogelijke terminologieverwarring op te helderen, laten we begrijpen dat in de Postgresql-wereld de term "schema" misschien enigszins overbelast is. In de bredere context van relationele databasebeheersystemen (RDBMS) kan de term "schema" worden opgevat als een verwijzing naar het algemene logische of fysieke ontwerp van de database, d.w.z. de definitie van alle tabellen, kolommen, weergaven en andere objecten die de databasedefinitie vormen. In die bredere context kan een schema worden uitgedrukt in een entiteit-relatiediagram (ER) of een script van DDL-instructies (Data Definition Language) die worden gebruikt om de applicatiedatabase te instantiëren.
In de Postgresql-wereld kan de term 'schema' beter worden begrepen als een 'naamruimte'. In feite worden in de Postgresql-systeemtabellen schema's vastgelegd in tabelkolommen die "naamruimte" worden genoemd, wat, IMHO, nauwkeurigere terminologie is. Als een praktische kwestie, wanneer ik 'schema' in de context van Postgresql zie, herinterpreteer ik het stilletjes als 'naamruimte'.
Maar je kunt je afvragen:"Wat is een naamruimte?" Over het algemeen is een naamruimte een vrij flexibel middel om informatie op naam te ordenen en te identificeren. Stel je bijvoorbeeld twee naburige huishoudens voor, de Smiths, Alice en Bob, en de Jones, Bob en Cathy (zie figuur 1). Als we alleen voornamen zouden gebruiken, zou het verwarrend kunnen worden welke persoon we bedoelden als we het over Bob hadden. Maar door de achternaam Smith of Jones toe te voegen, identificeren we op unieke wijze welke persoon we bedoelen.
Vaak zijn naamruimten georganiseerd in een geneste hiërarchie. Dit maakt een efficiënte classificatie van grote hoeveelheden informatie in zeer fijnkorrelige structuren mogelijk, zoals bijvoorbeeld het internetdomeinnaamsysteem. Op het hoogste niveau definiëren ".com", ".net", ".org", ".edu", enz. brede naamruimten waarbinnen geregistreerde namen voor specifieke entiteiten zijn, dus bijvoorbeeld "severalnines.com" en “postgresql.org” zijn uniek gedefinieerd. Maar onder elk van deze zijn er een aantal gemeenschappelijke subdomeinen zoals bijvoorbeeld "www", "mail" en "ftp", die alleen duplicerend zijn, maar binnen de respectieve naamruimten uniek zijn.
Postgresql-schema's dienen hetzelfde doel van organiseren en identificeren, maar in tegenstelling tot het tweede voorbeeld hierboven, kunnen Postgresql-schema's niet in een hiërarchie worden genest. Hoewel een database veel schema's kan bevatten, is er altijd maar één niveau en daarom moeten de schemanamen binnen een database uniek zijn. Elke database moet ook ten minste één schema bevatten. Telkens wanneer een nieuwe database wordt geïnstantieerd, wordt een standaardschema met de naam "public" gemaakt. De inhoud van een schema omvat alle andere database-objecten, zoals tabellen, weergaven, opgeslagen procedures, triggers, enzovoort. Om te visualiseren, raadpleegt u Afbeelding 2, die een matroesjka-pop-achtige nesting toont die laat zien waar schema's passen in de structuur van een schema. Postgresql-database.
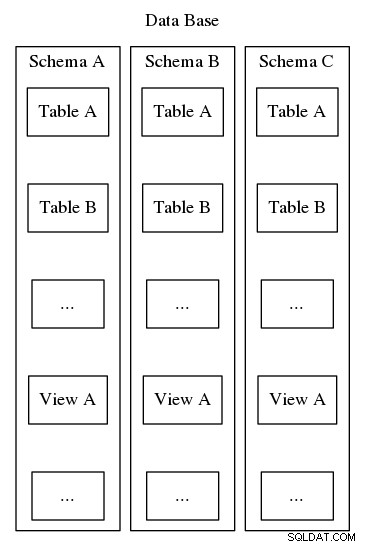
Naast het eenvoudig organiseren van database-objecten in logische groepen om ze beter beheersbaar te maken, dienen schema's het praktische doel om botsingen tussen namen te voorkomen. Een operationeel paradigma omvat het definiëren van een schema voor elke databasegebruiker om een zekere mate van isolatie te bieden, een ruimte waar gebruikers hun eigen tabellen en weergaven kunnen definiëren zonder elkaar te hinderen. Een andere benadering is het installeren van tools van derden of database-extensies in individuele schema's om alle gerelateerde componenten logisch bij elkaar te houden. Een later artikel in deze serie zal een nieuwe benadering van robuust applicatieontwerp beschrijven, waarbij schema's worden gebruikt als een middel om de blootstelling van het fysieke ontwerp van de database te beperken en in plaats daarvan een gebruikersinterface te presenteren die synthetische sleutels oplost en onderhoud op lange termijn en configuratiebeheer vergemakkelijkt. naarmate de systeemvereisten evolueren.
Laten we wat code doen!
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperDe eenvoudigste opdracht om een schema in een database te maken is
CREATE SCHEMA hollywood;Voor deze opdracht zijn aanmaakrechten in de database vereist en het nieuw gemaakte schema "hollywood" is eigendom van de gebruiker die de opdracht aanroept. Een complexere aanroep kan optionele elementen bevatten die een andere eigenaar specificeren, en kan zelfs DDL-instructies bevatten die database-objecten in het schema in één commando instantiëren!
Het algemene formaat is
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]waarbij "gebruikersnaam" is wie eigenaar is van het schema en "schema_element" een van bepaalde DDL-opdrachten kan zijn (raadpleeg de documentatie van Postgresql voor details). Superuser-privileges zijn vereist om de AUTORISATIE-optie te gebruiken.
Als u bijvoorbeeld een schema met de naam 'hollywood' wilt maken met een tabel met de naam 'films' en een weergave met de naam 'winnaars' in één opdracht, kunt u dat doen
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Extra database-objecten kunnen vervolgens direct worden gemaakt, er zou bijvoorbeeld een extra tabel aan het schema worden toegevoegd met
CREATE TABLE hollywood.actors (name text, dob date, gender text);Let in het bovenstaande voorbeeld op het voorvoegsel van de tabelnaam met de schemanaam. Dit is vereist omdat standaard, dat wil zeggen zonder expliciete schemaspecificatie, nieuwe database-objecten worden gemaakt binnen het huidige schema, dat we hierna zullen bespreken.
Bedenk hoe we in het voorbeeld van de voornaamruimte hierboven twee personen hadden met de naam Bob, en we beschreven hoe we ze konden ontwarren of onderscheiden door de achternaam op te nemen. Maar binnen elk van de Smith en Jones-huishoudens afzonderlijk, verstaat elk gezin 'Bob' om te verwijzen naar het huishouden dat bij dat specifieke huishouden hoort. Dus in de context van elk respectievelijk huishouden hoeft Alice haar man niet aan te spreken met Bob Jones, en Cathy hoeft haar man niet Bob Smith te noemen:ze kunnen allemaal gewoon "Bob" zeggen.
Het huidige Postgresql-schema lijkt een beetje op het huishouden in het bovenstaande voorbeeld. Er kan ongekwalificeerd naar objecten in het huidige schema worden verwezen, maar als u in andere schema's naar objecten met dezelfde naam verwijst, moet de naam worden gekwalificeerd door de schemanaam vooraf te laten gaan, zoals hierboven.
Het huidige schema is afgeleid van de configuratieparameter "search_path". Deze parameter slaat een door komma's gescheiden lijst van schemanamen op en kan worden onderzocht met het commando
SHOW search_path;of stel een nieuwe waarde in met
SET search_path TO schema [, schema, ...];De eerste schemanaam in de lijst is het "huidige schema" en hier worden nieuwe objecten gemaakt indien opgegeven zonder kwalificatie van de schemanaam.
De door komma's gescheiden lijst met schemanamen dient ook om de zoekvolgorde te bepalen waarmee het systeem bestaande niet-gekwalificeerde benoemde objecten lokaliseert. Terug naar de Smith and Jones-buurt, bijvoorbeeld, zou een pakketbezorging die alleen aan 'Bob' is geadresseerd, elk huishouden moeten bezoeken totdat de eerste bewoner met de naam 'Bob' is gevonden. Let op, dit is mogelijk niet de beoogde ontvanger. Dezelfde logica geldt voor Postgresql. Het systeem zoekt naar tabellen, weergaven en andere objecten binnen schema's in de volgorde van zoekpad, en vervolgens wordt het eerst gevonden object voor naamovereenkomst gebruikt. Schema-gekwalificeerde benoemde objecten worden direct gebruikt zonder verwijzing naar het zoekpad.
In de standaardconfiguratie onthult het opvragen van de configuratievariabele search_path deze waarde
SHOW search_path;
Search_path
--------------
"$user", publicHet systeem interpreteert de eerste waarde die hierboven wordt weergegeven als de huidige ingelogde gebruikersnaam en komt tegemoet aan de eerder genoemde use case waarbij elke gebruiker een gebruikersnaam krijgt toegewezen voor een werkruimte die gescheiden is van andere gebruikers. Als een dergelijk door een gebruiker genoemd schema niet is gemaakt, wordt dat item genegeerd en wordt het "openbare" schema het huidige schema waar nieuwe objecten worden gemaakt.
Dus, terug naar ons eerdere voorbeeld van het maken van de tabel "hollywood.actors", als we de tabelnaam niet hadden gekwalificeerd met de schemanaam, zou de tabel zijn gemaakt in het openbare schema. Als we hadden verwacht dat alle objecten binnen een specifiek schema zouden worden gemaakt, kan het handig zijn om de variabele zoekpad in te stellen, zoals
SET search_path TO hollywood,public;het vergemakkelijken van het typen van ongekwalificeerde namen om database-objecten te maken of te openen.
Er is ook een systeeminformatiefunctie die het huidige schema retourneert met een vraag
select current_schema();In het geval van vetvingeren van de spelling, mag de eigenaar van een schema de naam wijzigen, mits de gebruiker ook aanmaakrechten heeft voor de database, met de
ALTER SCHEMA old_name RENAME TO new_name;En als laatste, om een schema uit een database te verwijderen, is er een drop-commando
DROP SCHEMA schema_name;Het DROP-commando zal mislukken als het schema objecten bevat, dus deze moeten eerst worden verwijderd, of u kunt desgewenst recursief een schema verwijderen met de volledige inhoud van het schema met de optie CASCADE
DROP SCHEMA schema_name CASCADE;Met deze basisprincipes kun je beginnen met het begrijpen van schema's!