Een database load balancer, of database reverse proxy, verdeelt de inkomende database workload over meerdere databaseservers die erachter draaien. Het doel van het hebben van database-load balancers is om een enkel database-eindpunt te bieden voor toepassingen om verbinding mee te maken, de doorvoer van query's te vergroten, latentie te minimaliseren en het gebruik van bronnen van de databaseservers te maximaliseren.
Er kunnen twee manieren zijn om de load balancer-topologie van de database te gebruiken:
- Gecentraliseerde topologie
- Gedistribueerde topologie
In deze blogpost behandelen we beide topologieën en begrijpen we enkele voor- en nadelen van elke opstelling. Zou het ook mogelijk zijn om beide topologieën samen te mengen?
Gecentraliseerde topologie
In een gecentraliseerde configuratie bevindt zich een reverse proxy tussen de gegevens- en presentatielaag, zoals weergegeven in het volgende diagram:
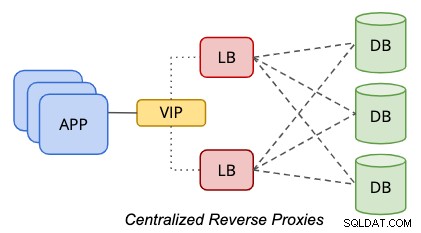
Om een single-point-of-failure te elimineren, moet twee of meer load balancer-knooppunten voor redundantiedoeleinden. Als uw toepassing meerdere database-eindpunten aankan, bijvoorbeeld de toepassing of het databasestuurprogramma in staat is om statuscontroles uit te voeren als de load balancer in orde is voor het verwerken van query's, kunt u waarschijnlijk het virtuele IP-adresgedeelte overslaan. Anders moeten beide load balancer-knooppunten aan elkaar worden gekoppeld met een gemeenschappelijke hostnaam of virtueel IP-adres, om transparantie te bieden aan de databaseclients waar het slechts één database-eindpunt hoeft te gebruiken om toegang te krijgen tot de gegevenslaag. Het gebruik van DNS of hosttoewijzing is ook mogelijk als u het gebruik van virtuele IP-adressen wilt overslaan.
Deze op lagen gebaseerde benadering is veel eenvoudiger te beheren vanwege de onafhankelijke statische hostplaatsing. Het is zeer onwaarschijnlijk dat de load balancer-laag wordt uitgeschaald (door meer knooppunten toe te voegen) vanwege de solide basis in veerkracht, redundantie en transparantie van de applicatielaag. U moet de host waarschijnlijk opschalen (meer bronnen aan de host toevoegen), wat vaak in de toekomst zal gebeuren, nadat de load balancer-workloads veeleisender zijn geworden naarmate uw bedrijf groeit.
Deze topologie vereist een extra laag en hosts, wat kostbaar kan zijn in een bare-metal infrastructuur met fysieke servers. Deze configuratie is gemakkelijker te beheren in een cloud- of virtuele omgeving, waar u de flexibiliteit heeft om een extra laag toe te voegen tussen de applicatie- en databaselaag, zonder dat u teveel betaalt voor de fysieke infrastructuurkosten zoals elektriciteit, rackruimte en netwerkkosten.
Gedistribueerde topologie
In een gedistribueerde topologieconfiguratie bevinden de load balancers zich op dezelfde plaats in de presentatielaag (applicatie- of webservers), zoals vereenvoudigd door het volgende diagram:
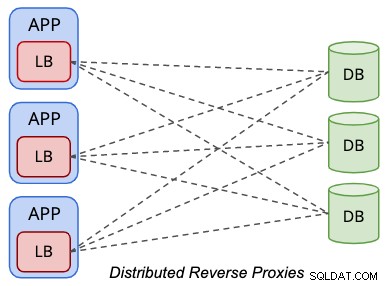
Toepassingen behandelen de load balancer van de database op dezelfde manier als een lokale databaseserver, waarbij de load balancer wordt de weergave van de externe databases vanuit het perspectief van de toepassing. Gewoonlijk luistert de load balancer naar de lokale netwerkinterface zoals 127.0.0.1 of "localhost", die de database-eindpuntdatabasehost voor de applicaties stroomlijnt.
Een van de voordelen van het draaien in deze topologie is dat je geen extra hosts nodig hebt voor taakverdeling. Door de load balancer-laag binnen de presentatielaag te combineren, konden we ten minste twee hosts besparen. In een bare-metal omgeving kan deze topologie u door de jaren heen mogelijk veel geld besparen. Over het algemeen is de load balancer-workload veel minder veeleisend in vergelijking met database- of applicatie-workloads, waardoor het gerechtvaardigd is om dezelfde hardwarebronnen met de applicaties te delen.
Wanneer u co-located met de applicatieserver, brengt u de reverse proxy dichter bij de applicatie en elimineert u het single-point-of-failure. Dit kan de toepassingsprestaties aanzienlijk verbeteren wanneer u een geografische scheiding hebt tussen de toepassing en de gegevenslaag, met name voor database-load balancers die caching van resultatensets ondersteunen, zoals ProxySQL en MaxScale. Aan de andere kant is het aantal database-load balancers gewoonlijk gelijk aan het aantal toepassingsknooppunten, wat betekent dat als de toepassingslaag wordt opgeschaald, het aantal database-loadbalancers zal toenemen, wat de prestaties voor de databasegezondheid mogelijk kan verslechteren. dienst controleren. Houd er rekening mee dat de statuscontroles van de load balancer een beetje spraakzamer zijn vanwege de verantwoordelijkheid om de juiste status van de databaseknooppunten bij te houden.
Met behulp van automatiseringstools voor IT-infrastructuur zoals Chef, Puppet en Ansible samen met de containerorkestratietools, is het niet langer een onmogelijke taak om de implementatie en het beheer van meerdere load balancer-instanties voor deze topologie te automatiseren. Er zal echter nog een leercurve zijn voor het operationele team om te komen met een beproefd implementatie- en beheerbeleid op productieniveau om het buitensporige werk bij het omgaan met veel load balancer-knooppunten te verminderen. Mis alle belangrijke beheeraspecten voor database-load balancer niet, zoals back-up/herstel, upgrade/downgrade, configuratiebeheer, servicecontrole, foutbeheer enzovoort.
Gedistribueerde topologie kan worden gecombineerd met de gecentraliseerde topologie voor sommige ondersteunde load balancers voor databases zoals ProxySQL, zoals geïllustreerd in het volgende diagram:
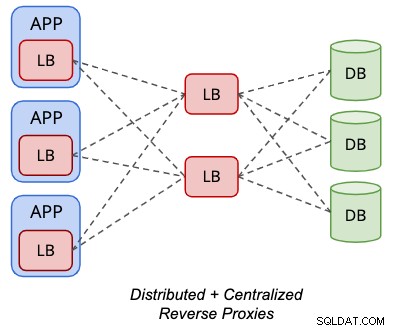
De backend "servers" van een ProxySQL-instantie kan een andere set ProxySQL zijn knooppunten in plaats daarvan. Met deze configuratie is een virtueel IP-adres niet nodig voor toegang via één eindpunt tot de databaseknooppunten, aangezien de lokale ProxySQL-instantie die lokaal op de toepassingsserver wordt gehost, de enkelvoudige eindpunttoegang zal zijn vanuit het oogpunt van de toepassing.
Dit vereist echter twee versies van load balancer-configuraties:een die zich op de toepassingslaag bevindt en een andere die zich op de load balancer-lagen bevindt. Het vereist ook meer hosts, zonder de noodzaak om te leren over virtuele IP-adrestechnologie, IP-failover enzovoort. De voor- en nadelen van zowel gedistribueerde als gecentraliseerde opstellingen zijn in deze topologie samengesmolten.
Conclusie
Elke topologie heeft zijn eigen voor- en nadelen en moet vanaf het begin goed worden gepland. Deze vroege beslissing is van cruciaal belang en kan op de lange termijn een enorme invloed hebben op de prestaties, schaalbaarheid, betrouwbaarheid en beschikbaarheid van uw applicatie.