In productie gaan is een zeer belangrijke taak die vooraf goed moet worden overwogen en gepland. Sommige niet zo goede beslissingen kunnen achteraf gemakkelijk worden gecorrigeerd, maar andere niet. Het is dus altijd beter om die extra tijd te besteden aan het lezen van de officiële documenten, boeken en onderzoeken die door anderen in een vroeg stadium zijn gemaakt, dan later spijt te hebben. Dit geldt voor de meeste implementaties van computersystemen en PostgreSQL is geen uitzondering.
Initiële systeemplanning
Sommige beslissingen moeten vroeg worden genomen, voordat het systeem live gaat. De PostgreSQL DBA moet een aantal vragen beantwoorden:Draait de DB op bare metal, VM's of zelfs in containers? Draait het op het terrein van de organisatie of in de cloud? Welk besturingssysteem zal worden gebruikt? Wordt de opslag van het type draaiende schijven of SSD's? Voor elk scenario of besluit zijn er voor- en nadelen en de uiteindelijke beslissing zal worden genomen in samenwerking met de belanghebbenden volgens de vereisten van de organisatie. Traditioneel draaiden mensen PostgreSQL op bare metal, maar dit is de afgelopen jaren drastisch veranderd met steeds meer cloudproviders die PostgreSQL als standaardoptie aanbieden, wat een teken is van de brede acceptatie en een resultaat van de toenemende populariteit van PostgreSQL. Onafhankelijk van de specifieke oplossing moet de DBA ervoor zorgen dat de gegevens veilig zijn, wat betekent dat de database crashes kan overleven, en dit is het belangrijkste criterium bij het nemen van beslissingen over hardware en opslag. Dit brengt ons bij de eerste tip!
Tip 1
Ongeacht wat de schijfcontroller of schijffabrikant of cloudopslagprovider adverteert, u moet er altijd voor zorgen dat de opslag niet liegt over fsync. Zodra fsync in orde is, zouden de gegevens veilig moeten zijn op het medium, wat er daarna ook gebeurt (crash, stroomstoring, enz.). Een handige tool waarmee u de betrouwbaarheid van de terugschrijfcache van uw schijven kunt testen, is diskchecker.pl.
Lees de opmerkingen:https://brad.livejournal.com/2116715.html en doe de test.
Gebruik één machine om naar gebeurtenissen te luisteren en de eigenlijke machine om te testen. Je zou moeten zien:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0aan het einde van het rapport over de geteste machine.
De tweede zorg, na betrouwbaarheid, moet gaan over prestaties. Beslissingen over het systeem (CPU, geheugen), waren vroeger veel belangrijker omdat het vrij moeilijk was om ze later te veranderen. Maar in het huidige cloudtijdperk kunnen we flexibeler omgaan met de systemen waarop de database draait. Hetzelfde geldt voor opslag, vooral in het begin van een systeem en terwijl de afmetingen nog klein zijn. Wanneer de DB het TB-cijfer overschrijdt, wordt het steeds moeilijker om de basisopslagparameters te wijzigen zonder de database volledig te hoeven kopiëren - of erger nog, om een pg_dump, pg_restore uit te voeren. De tweede tip gaat over systeemprestaties.
Tip 2
Net als bij het altijd testen van de beloften van de fabrikanten met betrekking tot betrouwbaarheid, moet u hetzelfde doen met de hardwareprestaties. Bonnie++ is de populairste benchmark voor opslagprestaties voor Unix-achtige systemen. Voor algemene systeemtests (CPU, geheugen en ook opslag) is niets representatiever dan de prestaties van de DB. Dus de basisprestatietest op uw nieuwe systeem zou pgbench zijn, de officiële PostgreSQL-benchmarksuite op basis van TCP-B.
Aan de slag gaan met pgbench is vrij eenvoudig, het enige wat u hoeft te doen is:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$U dient altijd pgbench te raadplegen na elke belangrijke wijziging waarvan u de resultaten wilt beoordelen en vergelijken.
Systeemimplementatie, automatisering en bewaking
Als u eenmaal live gaat, is het erg belangrijk om uw belangrijkste systeemcomponenten gedocumenteerd en reproduceerbaar te hebben, om geautomatiseerde procedures te hebben voor het creëren van services en terugkerende taken en ook om de tools te hebben om continue monitoring uit te voeren.
Tip 3
Een handige manier om PostgreSQL met al zijn geavanceerde bedrijfsfuncties te gaan gebruiken, is ClusterControl van Verschillendenines. Men kan een PostgreSQL-cluster van ondernemingsklasse hebben, gewoon met een paar klikken. ClusterControl biedt al deze bovengenoemde diensten en nog veel meer. Het opzetten van ClusterControl is vrij eenvoudig, volg gewoon de instructies op de officiële documentatie. Nadat u uw systemen hebt voorbereid (meestal één voor het uitvoeren van CC en één voor PostgreSQL voor een basisconfiguratie) en de SSH-configuratie hebt uitgevoerd, moet u de basisparameters invoeren (IP's, poortnummers, enz.), en als alles goed gaat, moet u zie een uitvoer zoals de volgende:
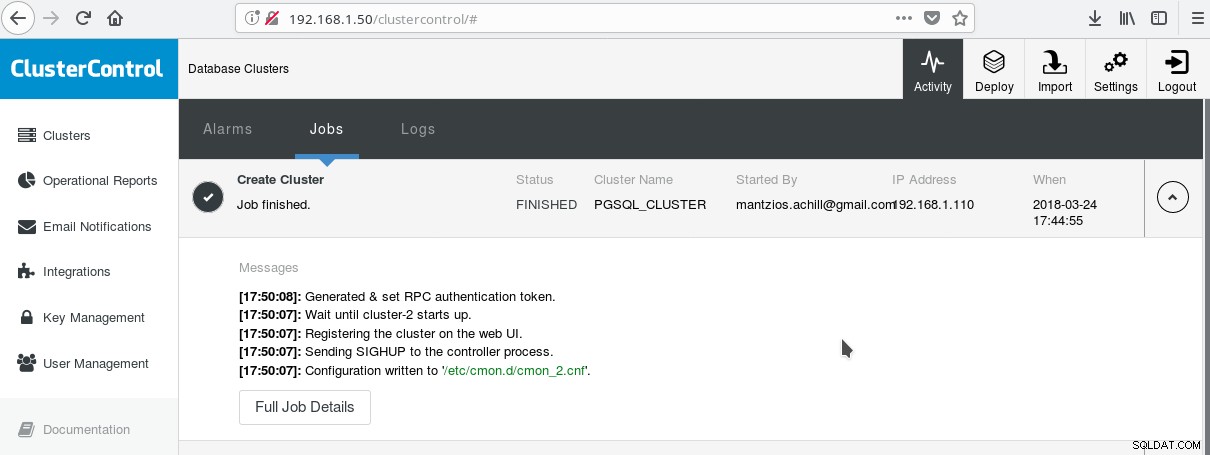
En in het hoofdclusterscherm:
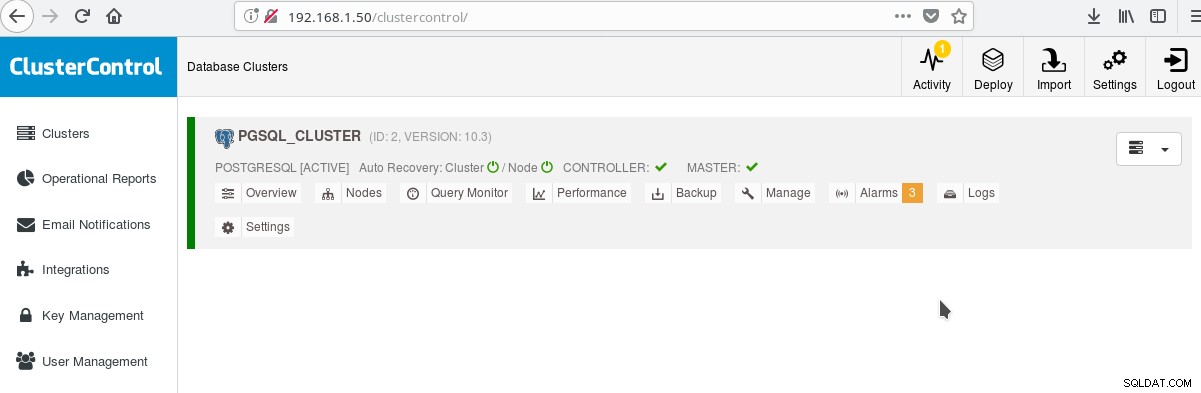
U kunt inloggen op uw masterserver en beginnen met het maken van uw schema! Uiteraard kunt u het zojuist aangemaakte cluster als basis gebruiken om uw infrastructuur (topologie) verder op te bouwen. Het is over het algemeen een goed idee om een stabiele indeling van het serverbestandssysteem en een definitieve configuratie op uw PostgreSQL-server en gebruikers-/app-databases te hebben voordat u klonen en standbys (slaves) gaat maken op basis van uw zojuist gemaakte gloednieuwe server.
PostgreSQL-layout, parameters en instellingen
In de clusterinitialisatiefase is de belangrijkste beslissing of gegevenscontrolesommen op gegevenspagina's moeten worden gebruikt of niet. Als u maximale dataveiligheid wilt voor uw waardevolle (toekomstige) data, dan is dit het moment om dat te doen. Als er een kans is dat u deze functie in de toekomst wilt hebben en u verzuimt dit in dit stadium te doen, kunt u deze later niet meer wijzigen (zonder pg_dump/pg_restore dus). Dit is de volgende tip:
Tip 4
Voer initdb als volgt uit om gegevenscontrolesommen in te schakelen:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Merk op dat dit moet gebeuren op het moment van tip 3 die we hierboven hebben beschreven. Als je het cluster al met ClusterControl hebt gemaakt, moet je pg_createcluster handmatig opnieuw uitvoeren, omdat er op het moment van schrijven geen manier is om het systeem of CC te vertellen deze optie op te nemen.
Een andere zeer belangrijke stap voordat u in productie gaat, is het plannen van de indeling van het serverbestandssysteem. De meeste moderne Linux-distro's (tenminste de op Debian gebaseerde) koppelen alles aan / maar met PostgreSQL wil je dat normaal gesproken niet. Het is handig om uw tablespace(s) op aparte volumes te hebben, om één volume te hebben dat is gereserveerd voor de WAL-bestanden en een ander voor pg-log. Maar het belangrijkste is om de WAL naar zijn eigen schijf te verplaatsen. Dit brengt ons bij de volgende tip.
Tip 5
Met PostgreSQL 10 op Debian Stretch kunt u uw WAL naar een nieuwe schijf verplaatsen met de volgende opdrachten (ervan uitgaande dat de nieuwe schijf /dev/sdb heet):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlHet is uiterst belangrijk om de landinstelling en codering van uw databases correct in te stellen. Als je dit over het hoofd ziet in de createb-fase, zul je hier veel spijt van krijgen, aangezien je app/DB naar de i18n, l10n-gebieden gaat. De volgende tip laat zien hoe je dat doet.
Tip 6
U moet de officiële documenten lezen en beslissen over uw COLLATE- en CTYPE-instellingen (createdb --locale=) (verantwoordelijk voor de sorteervolgorde en tekenclassificatie), evenals de instelling voor charset (createdb --encoding=). Door UTF8 als codering op te geven, kan uw database meertalige tekst opslaan.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperHoge beschikbaarheid PostgreSQL
Sinds PostgreSQL 9.0, toen streaming-replicatie een standaardfunctie werd, werd het mogelijk om een of meer alleen-lezen hot standbys te hebben, waardoor de mogelijkheid werd geboden om het alleen-lezen verkeer naar een van de beschikbare slaves te leiden. Er bestaan nieuwe plannen voor multimaster-replicatie, maar op het moment van schrijven (10.3) is het slechts mogelijk om één lees-schrijfmaster te hebben, in ieder geval in het officiële open source-product. Voor de volgende tip die hier precies over gaat.
Tip 7
We zullen onze ClusterControl PGSQL_CLUSTER gebruiken die in Tip 3 is gemaakt. Eerst maken we een tweede machine die zal fungeren als onze alleen-lezen slaaf (hot standby in PostgreSQL-terminologie). Vervolgens klikken we op Replicatie-slave toevoegen en selecteren we onze master en de nieuwe slave. Nadat de taak is voltooid, zou u deze uitvoer moeten zien:
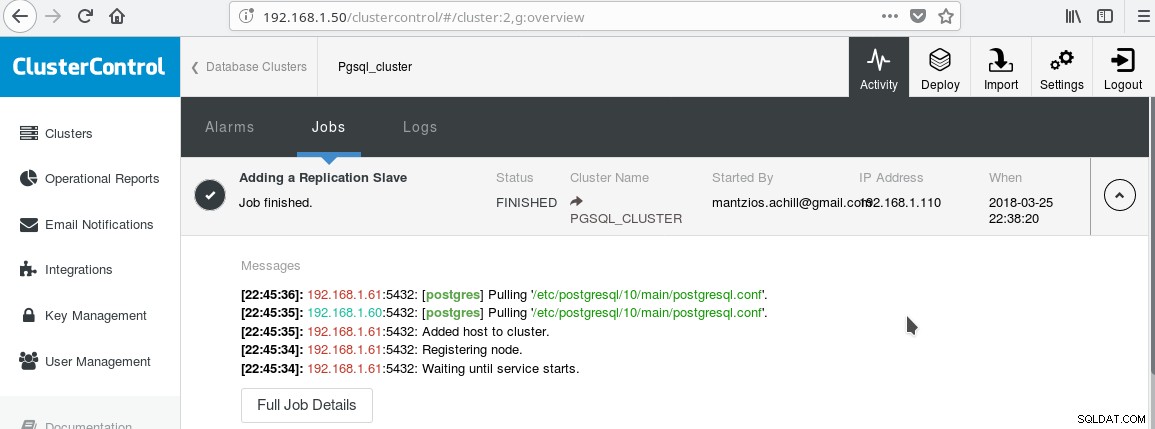
En het cluster zou er nu als volgt uit moeten zien:
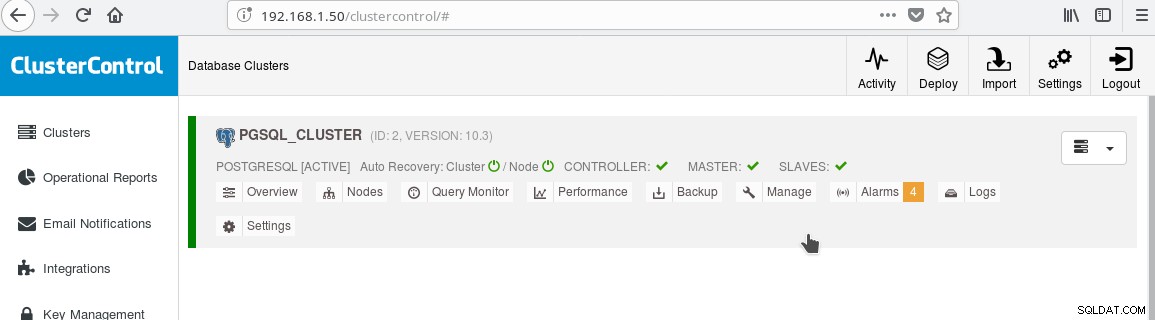
Let op het groene "aangevinkte" pictogram op het "SLAVES"-label naast "MASTER". U kunt controleren of de streaming-replicatie werkt door een databaseobject (database, tabel, enz.)
De aanwezigheid van de alleen-lezen stand-by stelt ons in staat om taakverdeling uit te voeren voor de clients die alleen-select-query's uitvoeren tussen de twee beschikbare servers, de master en de slave. Dit brengt ons bij tip 8.
Tip 8
U kunt taakverdeling tussen de twee servers inschakelen met HAProxy. Met ClusterControl is dit vrij eenvoudig te doen. U klikt op Beheren->Load Balancer. Nadat u uw HAProxy-server hebt gekozen, installeert ClusterControl alles voor u:xinetd op alle door u opgegeven instanties en HAProxy op uw door HAProxy aangewezen server. Nadat de taak met succes is voltooid, zou u het volgende moeten zien:
Let op het HAPROXY groene vinkje naast de SLAVES. Nu kunt u testen of HAProxy werkt:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Tip 9
Naast het configureren voor HA en taakverdeling, is het altijd handig om een soort verbindingspool voor de PostgreSQL-server te hebben. Pgpool en Pgbouncer zijn twee projecten afkomstig van de PostgreSQL-gemeenschap. Veel bedrijfstoepassingsservers bieden ook hun eigen pools. Pgbouncer is erg populair geweest vanwege zijn eenvoud, snelheid en de functie "transactie pooling", waardoor de verbinding met de server wordt vrijgegeven zodra de transactie is beëindigd, waardoor deze opnieuw kan worden gebruikt voor volgende transacties die uit dezelfde sessie of een andere kunnen komen . De instelling voor transactiepooling verbreekt sommige functies voor sessiepooling, maar over het algemeen is de conversie naar een configuratie die klaar is voor "transactiepooling" eenvoudig en de nadelen zijn in het algemeen niet zo belangrijk. Een gebruikelijke opzet is om de app-serverpool te configureren met semi-persistente verbindingen:een vrij grotere pool van verbindingen per gebruiker of per app (die verbinding maken met pgbouncer) met lange inactieve time-outs. Op deze manier is de verbindingstijd van de app minimaal, terwijl pgbouncer helpt om verbindingen met de server zo min mogelijk te houden.
Een ding dat hoogstwaarschijnlijk van belang zal zijn als je eenmaal live gaat met PostgreSQL, is het begrijpen en oplossen van langzame query's. De monitoringtools die we in de vorige blog noemden, zoals pg_stat_statements, en ook de schermen van tools zoals ClusterControl helpen je bij het identificeren en mogelijk voorstellen van ideeën voor het oplossen van langzame zoekopdrachten. Zodra u echter de langzame query identificeert, moet u EXPLAIN of EXPLAIN ANALYZE uitvoeren om precies de kosten en tijden te zien die betrokken zijn bij het queryplan. De volgende tip gaat over een heel handig hulpmiddel om dat te doen.
Tip 10
U moet uw EXPLAIN ANALYZE uitvoeren op uw database, en vervolgens de uitvoer kopiëren en plakken op de online tool voor uitleggen van de depesz en op verzenden klikken. Vervolgens ziet u drie tabbladen:HTML, TEKST en STATS. HTML bevat kosten, tijd en aantal lussen voor elk knooppunt in het plan. Het STATS-tabblad toont statistieken per knooppunttype. U moet de kolom "% van zoekopdracht" bekijken, zodat u weet waar uw zoekopdracht precies onder lijdt.
Naarmate u meer vertrouwd raakt met PostgreSQL, vindt u zelf nog veel meer tips!