PostgreSQL 11 werd uitgebracht op 10 oktober 2018, en volgens planning, ter gelegenheid van de 23e verjaardag van de steeds populairdere open source database.
Hoewel een volledige lijst met wijzigingen beschikbaar is in de gebruikelijke release-opmerkingen, is het de moeite waard om de vernieuwde Feature Matrix-pagina te bekijken, die net als de officiële documentatie een make-over heeft gekregen sinds de eerste versie, waardoor het gemakkelijker wordt om wijzigingen te herkennen voordat u in de details duikt .
Op de pagina Release-opmerkingen is de "Kanaalbinding voor SCAM-authenticatie" bijvoorbeeld begraven onder de broncode, terwijl de matrix deze heeft onder de sectie Beveiliging. Voor de nieuwsgierigen is hier een screenshot van de interface:
 PostgreSQL-functiematrix
PostgreSQL-functiematrix Bovendien is de Bucardo Postgres Release Notes-pagina die hierboven is gelinkt, handig op zijn eigen manier, waardoor het gemakkelijk is om in alle versies naar een trefwoord te zoeken.
Wat is er nieuw? Met letterlijk honderden wijzigingen zal ik de verschillen doornemen die in de Feature Matrix worden vermeld.
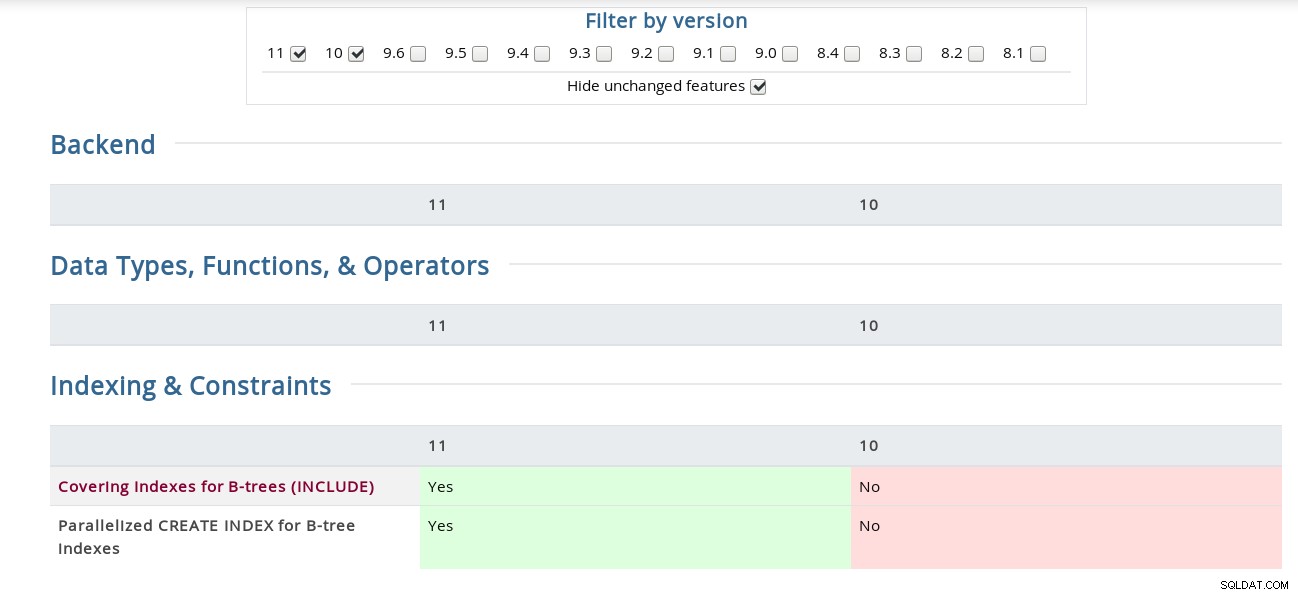
Indices voor B-trees (INCLUDE)
CREATE INDEX heeft de INCLUDE-clausule ontvangen waarmee indexen niet-sleutelkolommen kunnen bevatten . Het gebruik ervan voor frequente identieke vragen, wordt goed beschreven in Tom Lane's commit van 22 november, die de ontwikkelingsdocumentatie bijwerkt (wat betekent dat de huidige PostgreSQL 11-documentatie deze nog niet heeft), dus voor de volledige tekst raadpleegt u sectie 11.9. Alleen-index scans en dekkende indexen in de ontwikkelingsversie.
Parallelized CREATE INDEX voor B-tree Indexes
Zoals vermeld in de naam, is deze functie alleen geïmplementeerd voor de B-tree-indexen, en uit het commit-logboek van Robert Haas leren we dat de implementatie in de toekomst kan worden verfijnd. Zoals opgemerkt in de CREATE INDEX-documentatie, terwijl zowel parallelle als gelijktijdige methoden voor het maken van indexen gebruikmaken van meerdere CPU's, wordt in het geval van CONCURRENT alleen de eerste tabelscan parallel uitgevoerd.
Gerelateerd aan deze nieuwe functie zijn de configuratieparameters maintenance_work_mem en maintenance_parallel_maintenance_workers .
Ten slotte kan het aantal parallelle werkers per tabel worden ingesteld met behulp van het ALTER TABLE-commando en door een waarde op te geven voor parallel_workers .
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperJust-In-Time (JIT)-compilatie voor expressie-evaluatie en tuple-vervorming
Met zijn eigen JIT-hoofdstuk in de documentatie, vertrouwt deze nieuwe functie erop dat PostgreSQL wordt gecompileerd met LLVM-ondersteuning (gebruik pg_config om te verifiëren).
Het onderwerp JIT in PostgreSQL is complex genoeg (zie de JIT README-referentie in de documentatie) om een toegewijde blog te vereisen, in de tussentijd is de CitusData-blog over JIT een zeer goed boek voor diegenen die geïnteresseerd zijn om dieper in het onderwerp te duiken.
Parallelle hash-joins
Deze prestatieverbetering voor parallelle query's is het resultaat van het toevoegen van een gedeelde hash-tabel, die, zoals Thomas Munro uitlegt in zijn Parallel Hash for PostgreSQL-blog, het partitioneren van de hash-tabel vermijdt, op voorwaarde dat deze past in work_mem , wat tot nu toe voor PostgreSQL een betere oplossing lijkt te zijn dan het partitie-eerst-algoritme. Dezelfde blog beschrijft de PostgreSQL-architectuurobstakels die de auteur moest overwinnen in zijn zoektocht naar het toevoegen van parallellisatie aan hash-joins, wat wijst op de complexiteit van het werk dat nodig was om deze functie te implementeren.
Standaardpartitie
Dit is een catch all-partitie om rijen op te slaan die niet overeenkomen met een andere gedefinieerde partitie. In gevallen waarin een nieuwe partitie wordt toegevoegd, wordt een CHECK-beperking aanbevolen om te voorkomen dat de standaardpartitie wordt gescand, wat traag kan zijn wanneer de standaardpartitie een groot aantal rijen bevat.
Het standaard partitiegedrag wordt uitgelegd in de documentatie van ALTER TABLE en CREATE TABLE.
Partitionering met een hekje
Ook wel hash-partitionering genoemd, en zoals aangegeven in het commit-bericht, maakt de functie het partitioneren van tabellen op zo'n manier mogelijk dat partities een vergelijkbaar aantal rijen bevatten. Dit wordt bereikt door een modulus te bieden, die in het meer eenvoudige scenario wordt aanbevolen om gelijk te zijn aan het aantal partities, en de rest moet voor elke partitie anders zijn.
Voor meer details en een voorbeeld zie de CREATE TABLE documentatie pagina.
Ondersteuning voor PRIMARY KEY, FOREIGN KEY, indexen en triggers op gepartitioneerde tabellen
Tabelpartitionering is al een grote stap in het verbeteren van de prestaties van grote tabellen, en de toevoeging van deze functies lost de beperkingen op die gepartitioneerde tabellen hebben gehad sinds PostgreSQL 10, toen de moderne "declaratieve partitionering" werd geïntroduceerd.
Er wordt door Alvaro Herrera gewerkt om externe sleutels naar primaire sleutels te laten verwijzen, en dit is gepland voor de volgende hoofdversie van PostgreSQL 12.
UPDATE op een partitiesleutel
Zoals uitgelegd in het logboek voor het vastleggen van de patch, voorkomt deze update dat PostgreSQL een fout genereert wanneer een update van de partitiesleutel een rij ongeldig maakt, en in plaats daarvan wordt de rij verplaatst naar een geschikte partitie.
Kanaalbinding voor SCRAM-verificatie
Dit is een beveiligingsmaatregel die gericht is op het voorkomen van man-in-the-middle-aanvallen in SASL-authenticatie en wordt uitvoerig beschreven in de blog van de auteur. De functie vereist minimaal OpenSSL 1.0.2.
CREATE PROCEDURE en CALL-syntaxis voor SQL Stored Procedures
PostgreSQL heeft CREATE FUNCTION sinds 1996, met versie 1.0.1 , functies kunnen echter geen transacties aan. Zoals vermeld in de documentatie, is de opdracht CREATE PROCEDURE niet volledig compatibel met de SQL-standaard.
Opmerking:houd ons in de gaten voor een aanstaande blog waarin dieper wordt ingegaan op deze functie
Conclusie
De belangrijkste updates van PostgreSQL 11 zijn gericht op prestatieverbeteringen door parallelle uitvoering, partitionering en Just-In-Time-compilatie. Opgeslagen procedures zorgen voor volledige transactiecontrole en kunnen in verschillende PL-talen worden geschreven.