In dit 3e deel van Benchmarking van beheerde PostgreSQL-cloudoplossingen , heb ik gebruik gemaakt van het gratis GCP-aanbod van Google. Het was een waardevolle ervaring en als systeembeheerder die het grootste deel van zijn tijd op de console doorbrengt, kon ik de kans niet missen om cloudshell uit te proberen, een van de consolefuncties die Google onderscheidt van de cloudprovider waarmee ik meer vertrouwd ben , Amazon-webservices.
Om het snel samen te vatten, heb ik in deel 1 gekeken naar de beschikbare benchmarktools en uitgelegd waarom ik voor AWS Benchmark Procedure voor Aurora heb gekozen. Ik heb ook Amazon Aurora gebenchmarkt voor PostgreSQL-versie 10.6. In deel 2 heb ik AWS RDS beoordeeld voor PostgreSQL versie 11.1.
Tijdens deze ronde worden de tests op basis van de AWS Benchmark Procedure voor Aurora uitgevoerd tegen Google Cloud SQL voor PostgreSQL 9.6 aangezien versie 11.1 nog in bèta is.
Cloud-instanties
Vereisten
Zoals vermeld in de vorige twee artikelen, heb ik ervoor gekozen om de PostgreSQL-instellingen op hun cloud GUC-standaardwaarden te laten, tenzij ze voorkomen dat tests worden uitgevoerd (zie verderop). Bedenk uit eerdere artikelen dat de veronderstelling was dat de cloudprovider de database-instantie standaard moet hebben geconfigureerd om redelijke prestaties te leveren.
De AWS pgbench-timingpatch voor PostgreSQL 9.6.5 is netjes toegepast op Google Cloud-versie van PostgreSQL 9.6.10.
Met behulp van de informatie die Google in hun blog Google Cloud voor AWS Professionals heeft gepubliceerd, heb ik de specificaties voor de client en de doelinstanties met betrekking tot de componenten Compute, Storage en Networking op elkaar afgestemd. Het Google Cloud-equivalent van AWS Enhanced Networking wordt bijvoorbeeld bereikt door het rekenknooppunt te dimensioneren op basis van de formule:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Als het gaat om het instellen van de doeldatabase-instantie, net als bij AWS, staat Google Cloud geen replica's toe, maar de opslag is in rust versleuteld en er is geen optie om deze uit te schakelen.
Ten slotte moeten de client en de doelinstanties zich in dezelfde beschikbaarheidszone bevinden om de beste netwerkprestaties te bereiken.
Klant
De specificaties van de clientinstantie die het dichtst bij de AWS-instantie komen, zijn:
- vCPU:32 (16 cores x 2 threads/core)
- RAM:208 GiB (maximaal voor de 32 vCPU-instantie)
- Opslag:persistente schijf van Compute Engine
- Netwerk:16 Gbps (max van [32 vCPU's x 2 Gbps/vCPU] en 16 Gbps)
Instantiedetails na initialisatie:
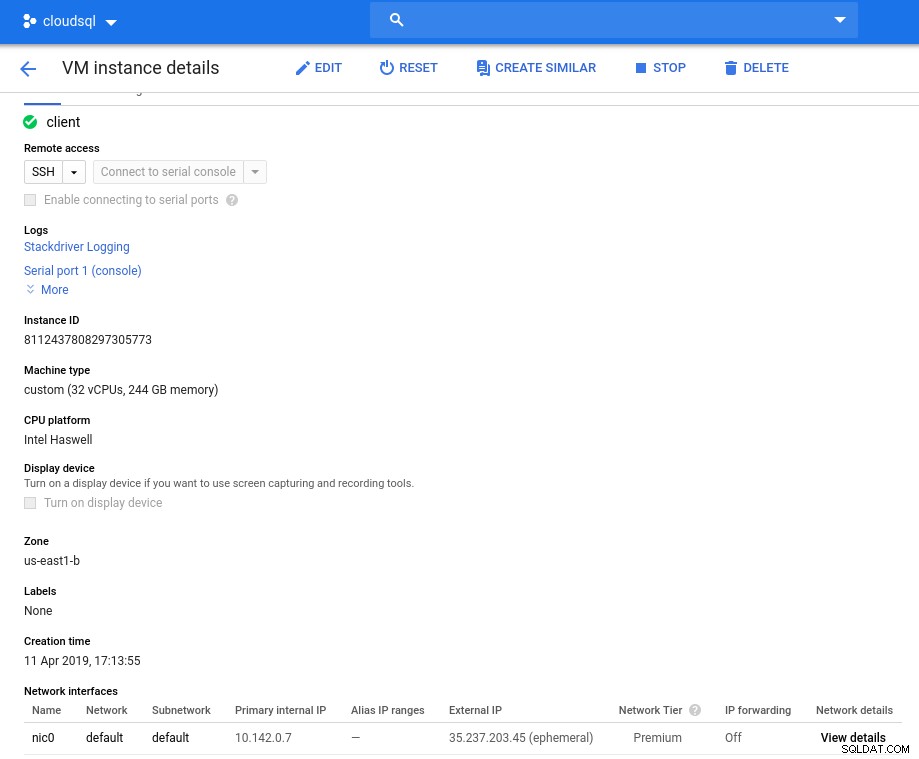 Clientinstantie:Compute en netwerk
Clientinstantie:Compute en netwerk Opmerking:Instanties zijn standaard beperkt tot 24 vCPU's. De technische ondersteuning van Google moet de quotaverhoging tot 32 vCPU's per instantie goedkeuren.

Hoewel dergelijke verzoeken doorgaans binnen twee werkdagen worden afgehandeld, moet ik de ondersteuningsservices van Google een pluim geven voor het voltooien van mijn verzoek in slechts twee uur.
Voor nieuwsgierigen:de formule voor netwerksnelheid is gebaseerd op de documentatie van de rekenmachine waarnaar in deze GCP-blog wordt verwezen.
DB-cluster
Hieronder staan de specificaties van de database-instantie:
- vCPU:8
- RAM:52 GiB (maximaal)
- Opslag:144 MB/s, 9.000 IOPS
- Netwerk:2.000 MB/s
Houd er rekening mee dat het maximaal beschikbare geheugen voor een 8 vCPU-instantie 52 GiB is. Er kan meer geheugen worden toegewezen door een grotere instantie te selecteren (meer vCPU's):
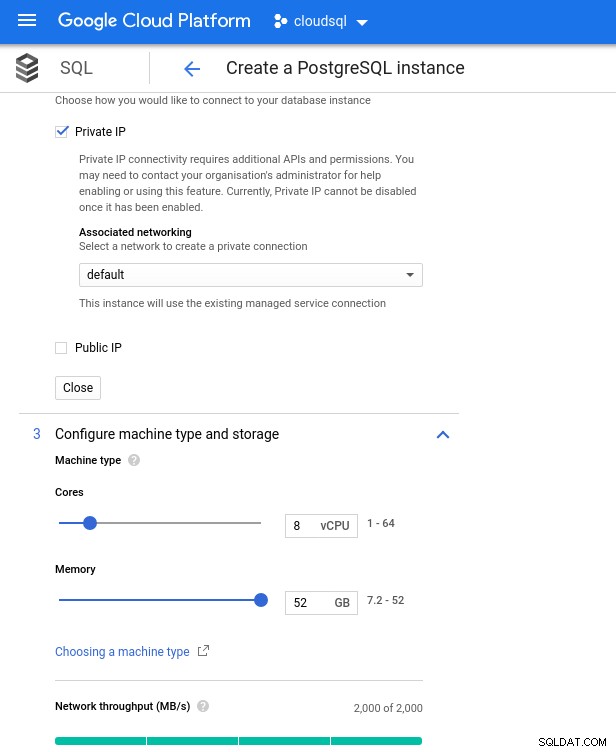 Database CPU en geheugengrootte
Database CPU en geheugengrootte Hoewel Google SQL de onderliggende opslag automatisch kan uitbreiden, wat trouwens een heel coole functie is, heb ik ervoor gekozen om de optie uit te schakelen om consistent te zijn met de AWS-functieset en een mogelijke I/O-impact tijdens het formaat wijzigen te voorkomen. ("potentieel", omdat het helemaal geen negatieve impact zou moeten hebben, maar in mijn ervaring verhoogt het wijzigen van elk type onderliggende opslag de I/O, zelfs al is het maar voor een paar seconden).
Bedenk dat de AWS-database-instantie werd geback-upt door een geoptimaliseerde EBS-opslag die een maximum bood van:
- 1700 Mbps bandbreedte
- 212,5 MB/s doorvoer
- 12.000 IOPS
Met Google Cloud bereiken we een vergelijkbare configuratie door het aantal vCPU's (zie hierboven) en opslagcapaciteit aan te passen:
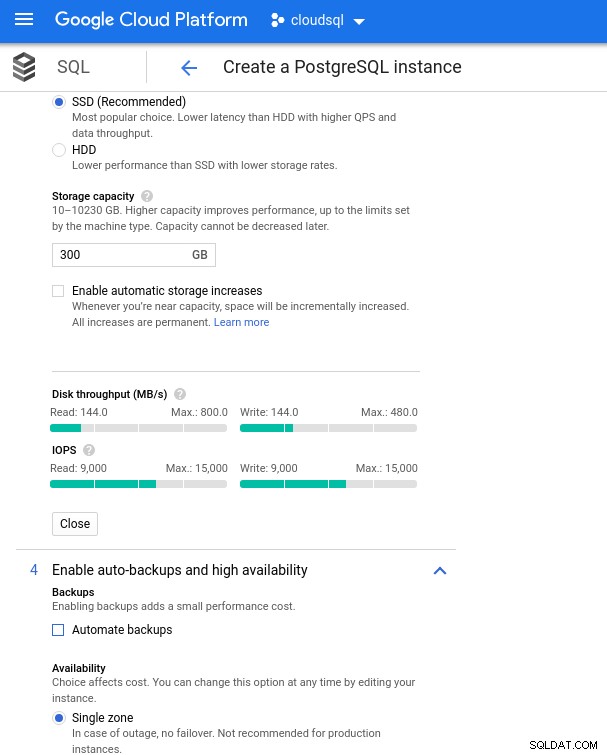 Databse-opslagconfiguratie en back-upinstellingen
Databse-opslagconfiguratie en back-upinstellingen De benchmarks uitvoeren
Instellen
Installeer vervolgens de benchmarktools, pgbench en sysbench door de instructies te volgen in de Amazon-gids die is aangepast aan PostgreSQL-versie 9.6.10.
Initialiseer de PostgreSQL-omgevingsvariabelen in .bashrc en stel de paden in op PostgreSQL-binaire bestanden en bibliotheken:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libPreflight-checklist:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)En we zijn klaar om op te stijgen:
pgbench
Initialiseer de pgbench-database.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…en enkele minuten later:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Zoals we nu gewend zijn, moet de databasegrootte 160GB zijn. Laten we dat verifiëren:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Als alle voorbereidingen zijn voltooid, start u de lees-/schrijftest:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsOeps! Wat is het maximum?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Dus hoewel AWS een grotendeels genoeg max_connections instelt omdat ik dat probleem niet tegenkwam, vereist Google Cloud een kleine aanpassing... Terug naar de cloudconsole, update de databaseparameter, wacht een paar minuten en controleer dan:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Door de test opnieuw te starten, lijkt alles goed te werken:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...maar er is nog een addertje onder het gras. Ik stond voor een verrassing toen ik probeerde een nieuwe psql-sessie te openen om het aantal verbindingen te tellen:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsZou het kunnen dat superuser_reserved_connections niet standaard is?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Dat is de standaard, wat zou het dan nog meer kunnen zijn?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! Een andere hobbel van max_connections zorgt ervoor, maar het vereiste dat ik de pgbench-test opnieuw moest starten. En dat is mensen het verhaal achter de schijnbare dubbele run in de onderstaande grafieken.
En tot slot zijn de resultaten binnen:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Vul de database:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareUitgang:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...En voer nu de test uit:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runEn de resultaten:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Benchmark-statistieken
De PostgreSQL-plug-in voor Stackdriver is beëindigd op 28 februari 2019. Hoewel Google Blue Medora aanbeveelt, heb ik er voor dit artikel voor gekozen geen account aan te maken en te vertrouwen op beschikbare Stackdriver-statistieken.
- CPU-gebruik:
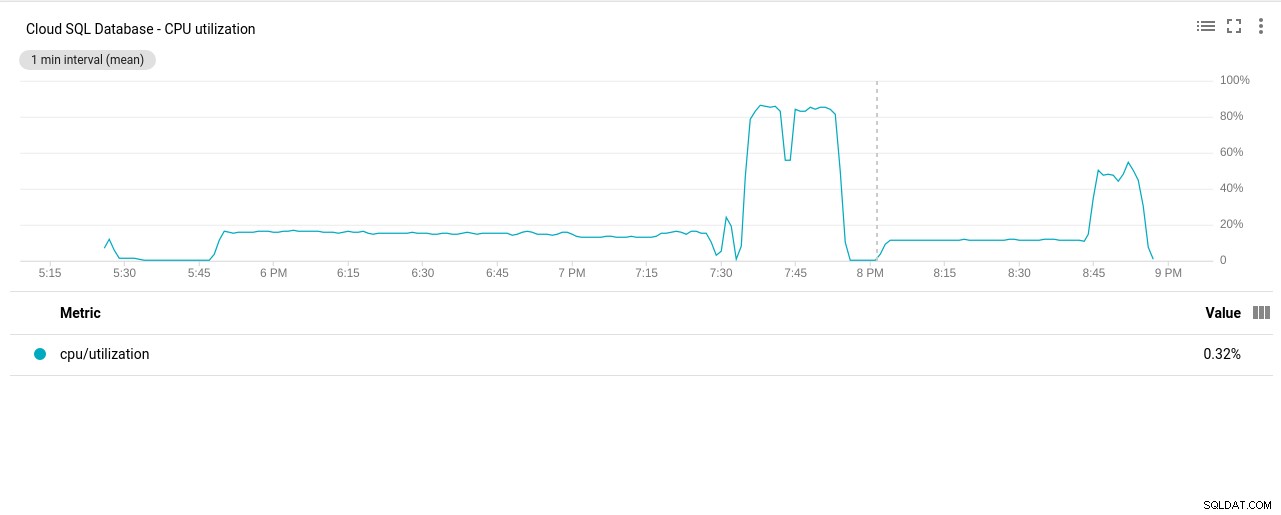 Foto auteur Google Cloud SQL:PostgreSQL CPU-gebruik
Foto auteur Google Cloud SQL:PostgreSQL CPU-gebruik - Schijflees-/schrijfbewerkingen:
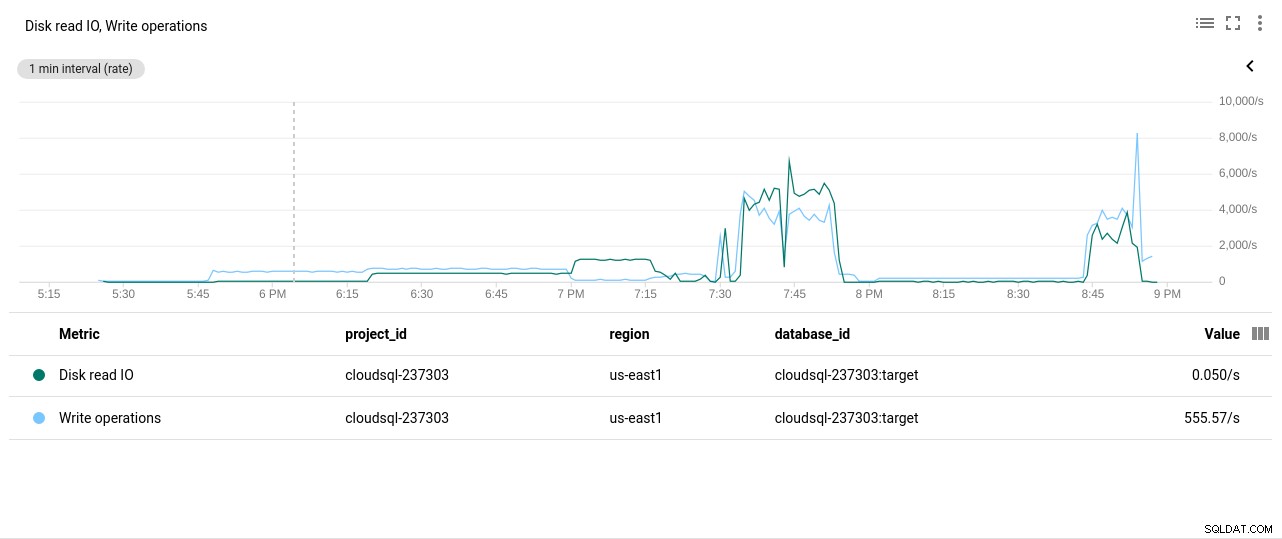 Foto auteur Google Cloud SQL:PostgreSQL schijf lees-/schrijfbewerkingen
Foto auteur Google Cloud SQL:PostgreSQL schijf lees-/schrijfbewerkingen - Netwerk verzonden/ontvangen bytes:
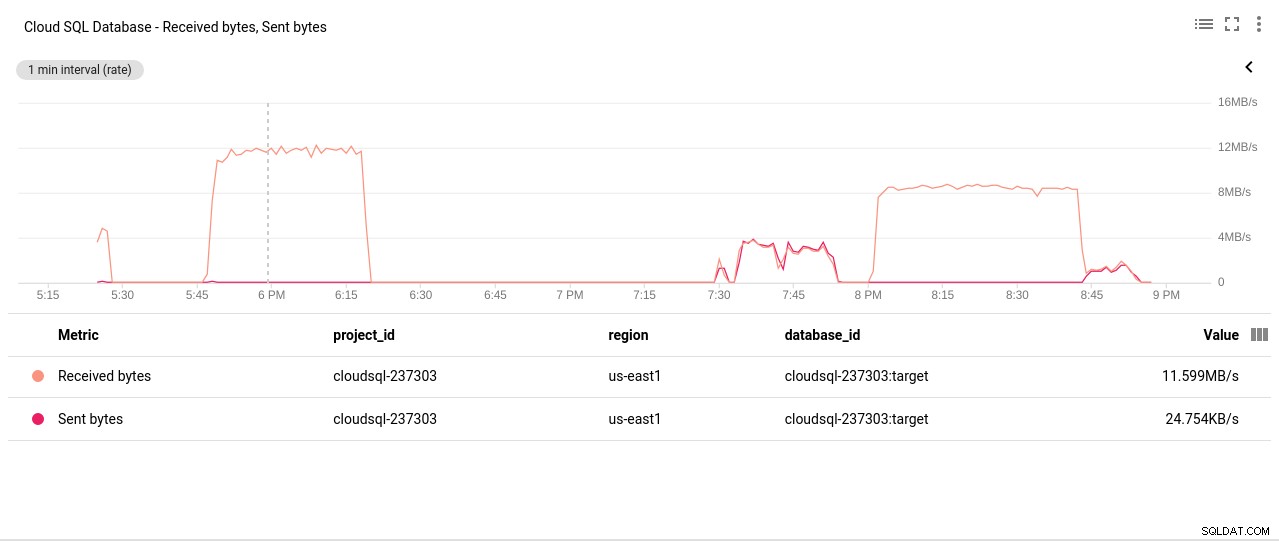 Foto auteur Google Cloud SQL:PostgreSQL netwerk verzonden/ontvangen bytes
Foto auteur Google Cloud SQL:PostgreSQL netwerk verzonden/ontvangen bytes - Aantal PostgreSQL-verbindingen:
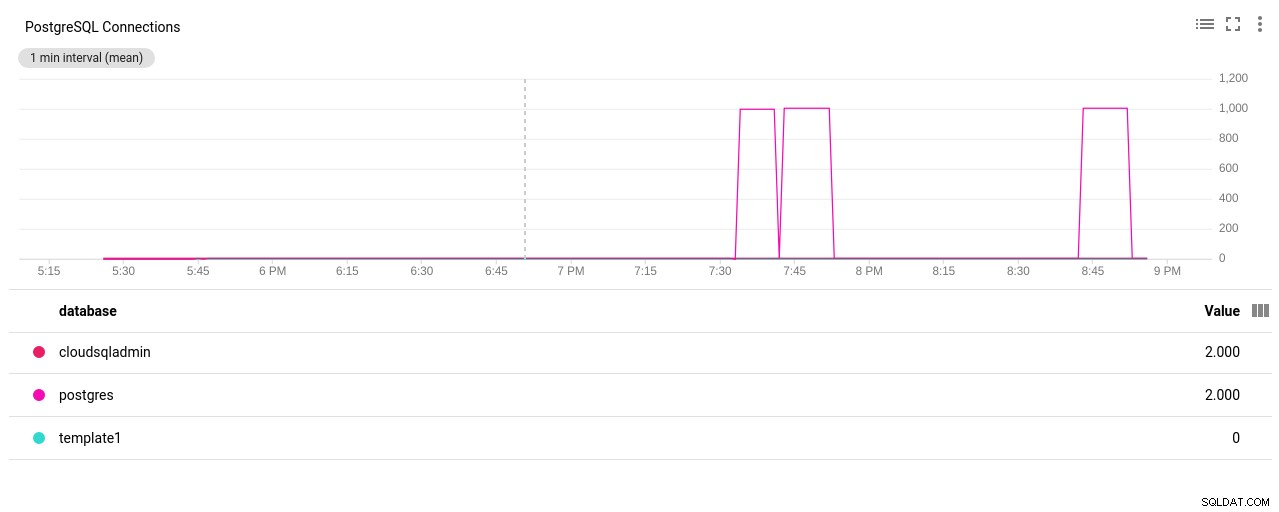 Fotoauteur Google Cloud SQL:PostgreSQL-verbindingen tellen
Fotoauteur Google Cloud SQL:PostgreSQL-verbindingen tellen
Benchmarkresultaten
pgbench-initialisatie
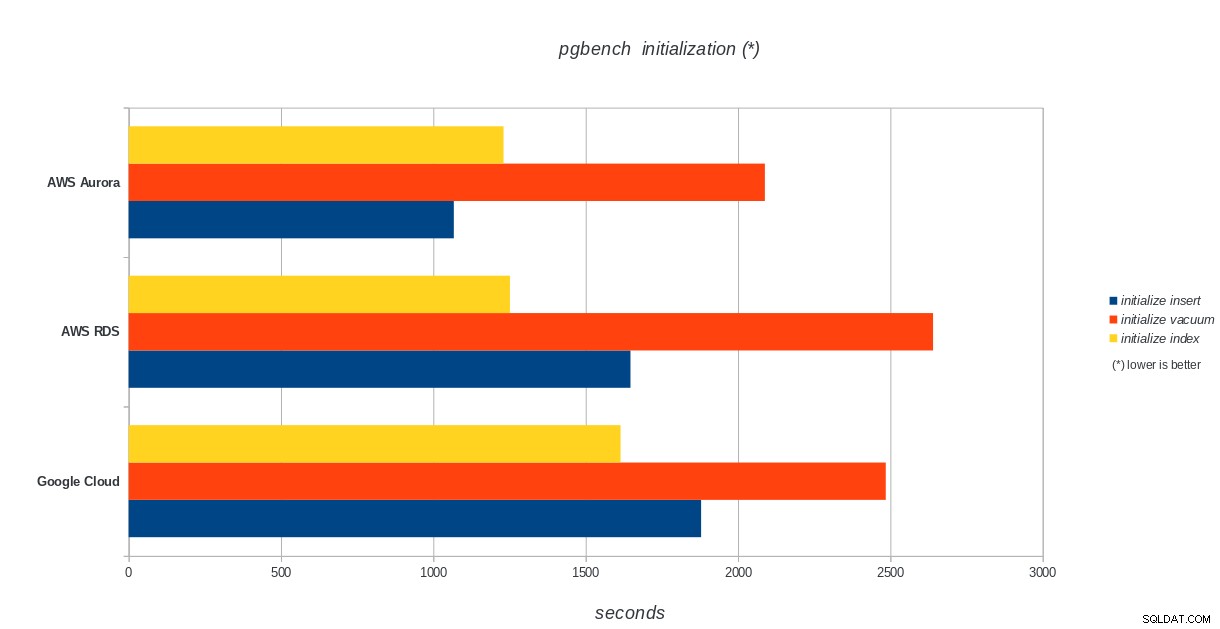 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench-initialisatieresultaten
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench-initialisatieresultaten pgbench-run
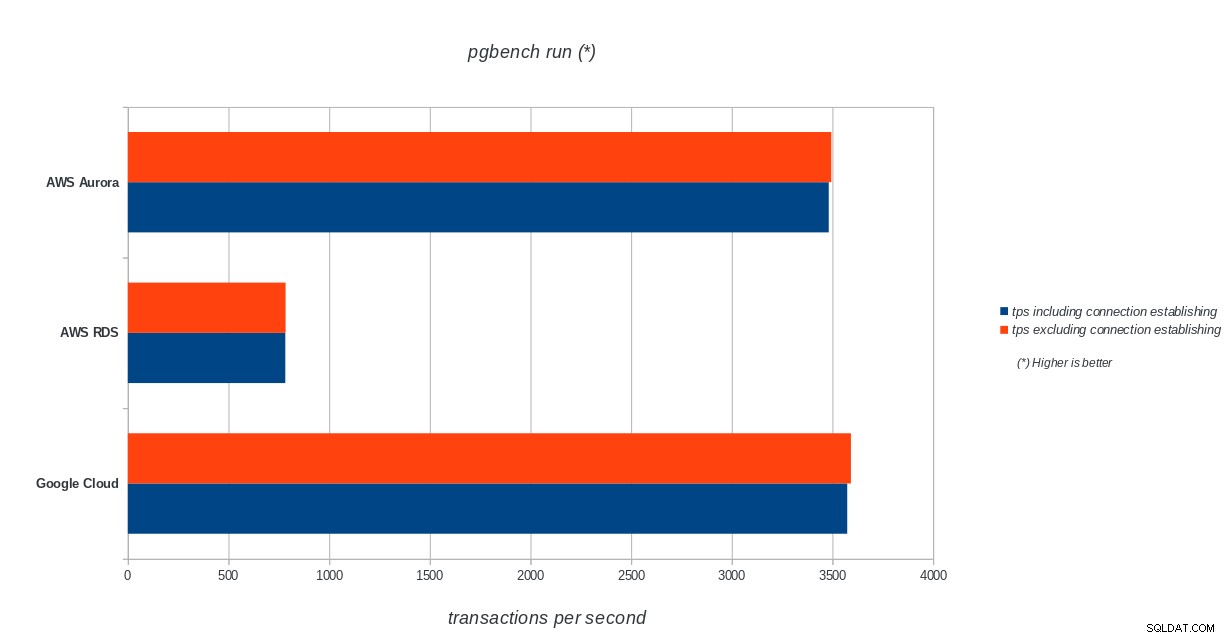 AWS Aurora, AWS RDS, Google Cloud SQL:resultaten van PostgreSQL pgbench-uitvoering
AWS Aurora, AWS RDS, Google Cloud SQL:resultaten van PostgreSQL pgbench-uitvoering sysbench
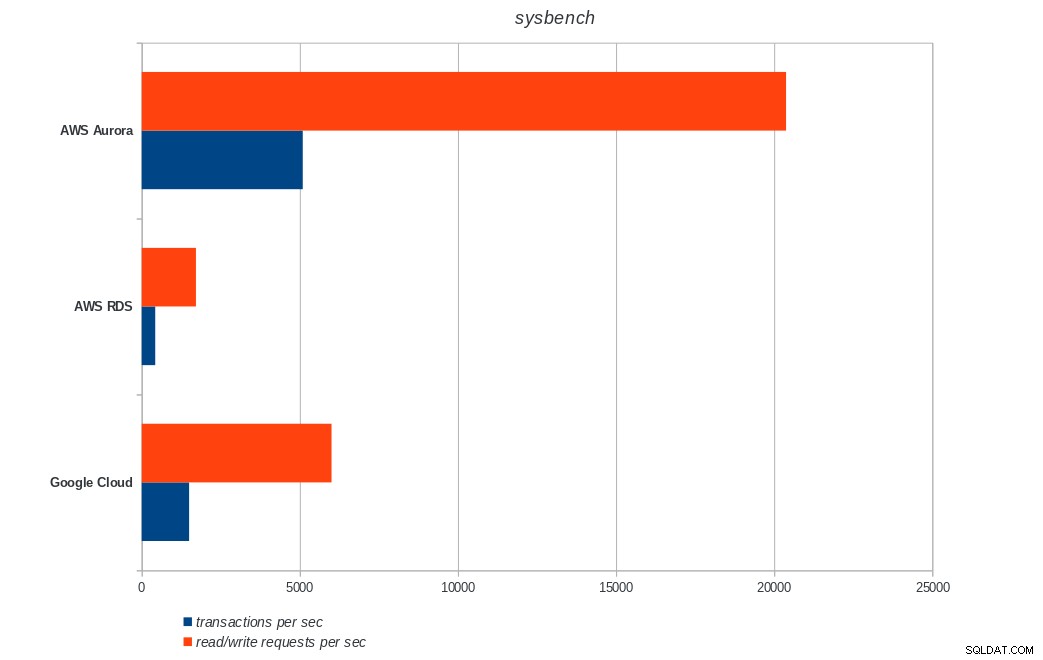 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench-resultaten
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench-resultaten Conclusie
Amazon Aurora komt veruit op de eerste plaats in zware schrijven (sysbench) tests, terwijl het op gelijke voet staat met Google Cloud SQL in de pgbench lees-/schrijftests. De load-test (pgbench-initialisatie) plaatst Google Cloud SQL op de eerste plaats, gevolgd door Amazon RDS. Op basis van een vluchtige blik op de prijsmodellen voor AWS Aurora en Google Cloud SQL, zou ik durven zeggen dat Google Cloud standaard een betere keuze is voor de gemiddelde gebruiker, terwijl AWS Aurora beter geschikt is voor omgevingen met hoge prestaties. Na het voltooien van alle benchmarks volgt meer analyse.
Het volgende en laatste deel van deze benchmarkreeks zal plaatsvinden op Microsoft Azure PostgreSQL.
Bedankt voor het lezen en reageer hieronder als je feedback hebt.