Vacuüm is een van de belangrijkste functies voor het terugwinnen van verwijderde tuples in tabellen en indexen. Zonder vacuüm zouden tabellen en indexen grenzeloos in omvang blijven groeien. Deze blogpost beschrijft de PARALLEL-optie voor de VACUUM-opdracht, die nieuw is geïntroduceerd in PostgreSQL13.
Vacuümverwerkingsfasen
Laten we, voordat we de nieuwe optie diepgaand bespreken, de details bekijken van hoe vacuüm werkt.
Vacuüm (zonder FULL-optie) bestaat uit vijf fasen. Voor een tabel met twee indexen werkt het bijvoorbeeld als volgt:
- Heap-scanfase
- Scan de tafel van bovenaf en verzamel afvaltupels in het geheugen.
- Index vacuümfase
- Zuig beide indexen één voor één op.
- Hoop vacuümfase
- Zuig de hoop (tafel).
- Opruimingsfase index
- Schoon beide indexen één voor één op.
- Hoop inkortingsfase
- Lege pagina's aan het einde van de tabel inkorten.
In de heap-scanfase kan vacuüm de zichtbaarheidskaart gebruiken om de verwerking van pagina's over te slaan waarvan bekend is dat ze geen rommel bevatten, terwijl in zowel de indexvacuümfase als de indexopschoningsfase, afhankelijk van de indextoegangsmethoden, een hele index wordt gescand is vereist.
btree-indexen, het meest populaire indextype, vereisen bijvoorbeeld een volledige indexscan om afvaltupels te verwijderen en de index op te schonen. Aangezien vacuüm altijd door een enkel proces wordt uitgevoerd, worden de indexen één voor één verwerkt. De langere uitvoeringstijd van vacuüm op vooral een grote tafel irriteert de gebruikers vaak.
PARALLEL optie
Om dit probleem aan te pakken, heb ik in 2016 een patch voorgesteld om vacuüm te parallelliseren. Na een lang evaluatieproces en vele hervormingen is de PARALLEL-optie geïntroduceerd in PostgreSQL 13. Met deze optie kan vacuüm de Index-vacuümfase en indexopruimingsfase uitvoeren met parallelle werkers. Parallelle vacuümwerkers starten voordat ze naar de indexvacuümfase of indexopruimingsfase gaan en verlaten aan het einde van de fase. Een individuele werknemer wordt toegewezen aan een index. Parallel vacuüm is altijd uitgeschakeld in autovacuüm.
De optie PARALLEL zonder een geheel getal-argument berekent automatisch de parallelle graad op basis van het aantal indexen in de tabel.
VACUUM (PARALLEL) tbl;
Aangezien het leiderproces altijd één index verwerkt, is het maximum aantal parallelle werkers (het aantal indexen in tabel – 1), wat verder beperkt is tot max_parallel_maintenance_workers. De doelindex moet groter zijn dan of gelijk zijn aan min_parallel_index_scan_size.
Met de optie PARALLEL kunnen we de parallelle graad specificeren door een geheel getal dat niet nul is door te geven. In het volgende voorbeeld worden drie werkers gebruikt, voor een totaal van vier parallelle processen.
VACUUM (PARALLEL 3) tbl;
De PARALLEL-optie is standaard ingeschakeld; om parallel vacuüm uit te schakelen, stelt u max_parallel_maintenance_workers in op 0, of specificeert u PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Als we naar de VACUUM VERBOSE-uitvoer kijken, kunnen we zien dat een werknemer de index aan het verwerken is.
De informatie die wordt afgedrukt als "door parallelle werknemer" wordt gerapporteerd door de werknemer.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Indextoegangsmethoden versus mate van parallellisme
Vacuüm voert de indexvacuümfase en de indexopruimingsfase niet altijd parallel uit. Als de indexgrootte klein is, of als bekend is dat het proces snel kan worden voltooid, veroorzaken de kosten van het starten en beheren van parallelle werknemers voor parallellisatie in plaats daarvan overhead. Afhankelijk van de toegangsmethoden en de grootte van de index, is het beter om deze fasen niet uit te voeren door een parallel vacuümproces.
Bij het stofzuigen van een index die groot genoeg is, kan de indexvacuümfase van de index bijvoorbeeld worden uitgevoerd door een parallelle vacuümwerker omdat er altijd een hele indexscan nodig is, terwijl de indexopruimingsfase wordt uitgevoerd door een parallelle vacuümwerker als de index vacuüm wordt niet uitgevoerd (er ligt bijvoorbeeld geen afval op tafel). Dit komt omdat btree-indexen in de indexopschoningsfase de indexstatistieken moeten verzamelen, die ook worden verzameld tijdens de indexvacuümfase. Aan de andere kant vereisen hash-indexen altijd geen scan op de index tijdens de fase van het opschonen van de index.
Om verschillende soorten indexvacuümstrategieën te ondersteunen, kunnen ontwikkelaars van indextoegangsmethoden dit gedrag specificeren door vlaggen in te stellen op de amparallelvacuumoptions veld van de IndexAmRoutine structuur. De beschikbare vlaggen zijn als volgt:
- VACUUM_OPTION_NO_PARALLEL (standaard)
- parallel vacuüm is in beide fasen uitgeschakeld.
- VACUUM_OPTION_PARALLEL_BULKDEL
- de indexvacuümfase kan parallel worden uitgevoerd.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- de indexopruimingsfase kan parallel worden uitgevoerd als de indexvacuümfase nog niet is uitgevoerd.
- VACUUM_OPTION_PARALLEL_CLEANUP
- de indexopschoningsfase kan parallel worden uitgevoerd, zelfs als de indexvacuümfase de index al heeft verwerkt.
De onderstaande tabel laat zien hoe index AM's ingebouwde PostgreSQL parallel vacuüm ondersteunt.
| nbtree | hash | gin | kern | spgist | brin | bloei | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Zie 'src/include/command/vacuum.h' voor meer details.
Prestatieverificatie
Ik heb de prestaties van parallel vacuüm op mijn laptop geëvalueerd (Core i7 2.6GHz, 16GB RAM, 512GB SSD). De tabelgrootte is 6 GB en heeft acht indexen van 3 GB. De totale relatie is 30 GB, wat niet past in het machine-RAM. Voor elke evaluatie maakte ik enkele procenten van de tafel gelijkmatig vuil na het stofzuigen, en voerde vervolgens vacuüm uit terwijl ik de parallelle graad veranderde. De onderstaande grafiek toont de uitvoeringstijd van het vacuüm.
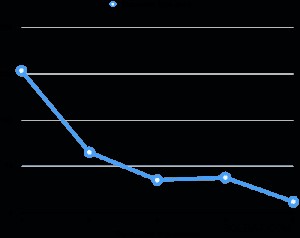
In alle evaluaties was de uitvoeringstijd van het indexvacuüm goed voor meer dan 95% van de totale uitvoeringstijd. Daarom hielp parallellisatie van de indexvacuümfase de uitvoeringstijd van het vacuüm aanzienlijk te verkorten.
Bedankt
Speciale dank aan Amit Kapila voor het toegewijde reviewen, het geven van advies en het toewijzen van deze functie aan PostgreSQL 13. Ik waardeer alle ontwikkelaars die betrokken waren bij deze functie voor het beoordelen, testen en bespreken.