Doe NIET gebruik indexen behalve voor een unieke enkele numerieke toets.
Dat past niet bij alle DB-theorie die we hebben ontvangen, maar testen met zware hoeveelheden gegevens tonen het aan. Hier is een resultaat van 100 miljoen ladingen tegelijk om 2 miljard rijen in een tabel te bereiken, en elke keer een heleboel verschillende zoekopdrachten op de resulterende tabel. Eerste grafische kaart met 10 gigabit NAS (150 MB/s), tweede met 4 SSD in RAID 0 (R/W @ 2GB/s).
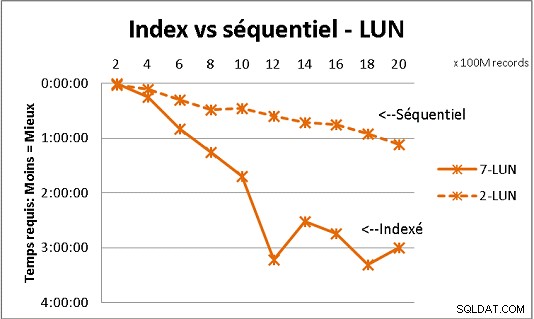
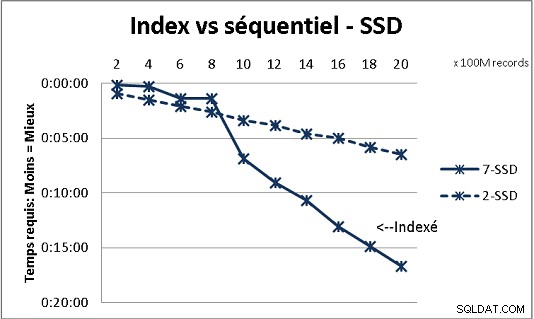
Als u meer dan 200 miljoen rijen in een tabel op gewone schijven heeft, gaat het sneller als u indexen vergeet. Op SSD's ligt de limiet op 1 miljard.
Ik heb het ook met partities gedaan voor betere resultaten, maar met PG9.2 is het moeilijk om hiervan te profiteren als je opgeslagen procedures gebruikt. Je moet ook zorgen voor het schrijven/lezen naar slechts 1 partitie tegelijk. Partities zijn echter de beste keuze om uw tafels onder de muur van 1 miljard rijen te houden. Het helpt ook veel om uw ladingen te multiprocessen. Met SSD kan ik met een enkel proces 18.000 rijen/s invoegen (kopiëren) (inclusief wat verwerkingswerk). Met multiprocessing op 6 CPU's groeit het tot 80.000 rijen/sec.
Let tijdens het testen op uw CPU- en IO-gebruik om beide te optimaliseren.