Een van mijn grootste vreugden als ontwikkelaar is leren hoe verschillende technologieën elkaar kruisen.
Door de jaren heen heb ik de kans gehad om met verschillende soorten software en tools te werken. Van de vele tools die ik heb gebruikt, zijn Python en Structured Query Language (SQL) twee van mijn favorieten.
In dit artikel ga ik met u delen hoe Python en de verschillende SQL-databases op elkaar inwerken.
Ik zal het hebben over de meest populaire databases, SQLite, MySQL en PostgreSQL. Ik zal de belangrijkste verschillen van elke database en de bijbehorende use-cases uitleggen. En ik zal het artikel eindigen met wat Python-code.
De code laat je zien hoe je een SQL-query schrijft om gegevens uit een PostgreSQL-database te halen en de gegevens op te slaan in een panda-gegevensframe.
Als je niet bekend bent met relationele databases (RDBMS), raad ik je aan om hier het artikel van Sameer over de basisterminologie van RDBMS te lezen. In de rest van het artikel worden termen gebruikt waarnaar in het artikel van Sameer wordt verwezen.
Populaire SQL-databases
SQLite
SQLite is vooral bekend als een geïntegreerde database. Dit betekent dat u geen extra applicatie hoeft te installeren of een aparte server hoeft te gebruiken om de database te laten draaien.
Als u een MVP maakt of niet veel gegevensopslagruimte nodig heeft, wilt u een SQLite-database gebruiken.
De voordelen zijn dat u sneller kunt bewegen met een SQLite-database ten opzichte van MySQL en PostgreSQL. Dat gezegd hebbende, zit je vast met beperkte functionaliteit. U kunt geen functies aanpassen of een heleboel functionaliteit voor meerdere gebruikers toevoegen.
MySQL/PostgreSQL
Er zijn duidelijke verschillen tussen MySQL en PostgreSQL. Dat gezegd hebbende, passen ze, gezien de context van het artikel, in een vergelijkbare categorie.
Beide databasetypen zijn geweldig voor bedrijfsoplossingen. Als u snel wilt schalen, zijn MySQL en PostgreSQL de beste keuze. Ze bieden een langetermijninfrastructuur en versterken uw beveiliging.
Een andere reden waarom ze geweldig zijn voor ondernemingen, is dat ze high-performance activiteiten aankunnen. Langere instructies voor invoegen, bijwerken en selecteren hebben veel rekenkracht nodig. U kunt deze instructies schrijven met minder latentie dan wat een SQLite-database u zou geven.
Waarom Python en een SQL-database verbinden?
Je vraagt je misschien af, "waarom zou ik me druk maken om het verbinden van Python en een SQL-database?"
Er zijn veel gevallen waarin iemand Python met een SQL-database wil verbinden. Zoals ik eerder al zei, werkt u mogelijk aan een webtoepassing. In dit geval moet u een SQL-database aansluiten, zodat u de gegevens uit de webtoepassing kunt opslaan.
Misschien werk je in de data-engineering en moet je een geautomatiseerde ETL-pijplijn bouwen. Door Python aan een SQL-database te koppelen, kunt u Python gebruiken voor zijn automatiseringsmogelijkheden. U kunt ook communiceren tussen verschillende gegevensbronnen. U hoeft niet te schakelen tussen verschillende programmeertalen.
Door Python en een SQL-database met elkaar te verbinden, wordt uw datawetenschap ook gemakkelijker. U kunt uw Python-vaardigheden gebruiken om gegevens uit een SQL-database te manipuleren. Je hebt geen CSV-bestand nodig.
Hoe Python- en SQL-databases met elkaar verbinden

Python- en SQL-databases maken verbinding via aangepaste Python-bibliotheken. U kunt deze bibliotheken importeren in uw Python-script.
Database-specifieke Python-bibliotheken dienen als aanvullende instructies. Deze instructies begeleiden uw computer over hoe deze kan communiceren met uw SQL-database. Anders is uw Python-code een vreemde taal voor de database waarmee u verbinding probeert te maken.
Hoe het project in te stellen
Laten we bijvoorbeeld een PostgreSQL-database nemen, AWS Redshift. Eerst wil je de psycopg-bibliotheek importeren. Het is een universele Python-bibliotheek voor PostgreSQL-databases.
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdU zult merken dat we ook de JSON- en panda-bibliotheken hebben geïmporteerd. We hebben JSON geïmporteerd omdat het maken van een JSON-configuratiebestand een veilige manier is om uw databasereferenties op te slaan. We willen niet dat iemand anders die in de gaten houdt!
Met de panda-bibliotheek kun je alle statistische mogelijkheden van panda's gebruiken voor je Python-script. In dit geval stelt de bibliotheek Python in staat om de gegevens die uw SQL-query retourneert op te slaan in een gegevensframe.
Vervolgens wil je toegang tot je configuratiebestand. De json.load() functie leest het JSON-bestand zodat u in de volgende stap toegang hebt tot uw databasereferenties.
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
Nu uw Python-script toegang heeft tot uw JSON-configuratiebestand, wilt u een databaseverbinding maken. U moet de inloggegevens van uw configuratiebestand lezen en gebruiken:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()U heeft zojuist een databaseverbinding gemaakt! Toen je de psycopg-bibliotheek importeerde, vertaalde je de Python-code die je hierboven schreef om met de PostgreSQL-database (AWS Redshift) te spreken.
Op zichzelf zou AWS Redshift de bovenstaande code niet begrijpen. Maar omdat je de psycopg-bibliotheek hebt geïmporteerd, spreek je nu een taal die AWS Redshift kan begrijpen.
Het leuke van Python is dat het bibliotheken heeft voor SQLite, MySQL en PostgreSQL. U kunt de technologieën gemakkelijk integreren.
Een SQL-query schrijven
Voel je vrij om de Europese voetbalgegevens te downloaden naar je PostgreSQL-database. Ik zal de gegevens voor dit voorbeeld gebruiken.
Met de databaseverbinding die u in de laatste stap hebt gemaakt, kunt u SQL schrijven om de gegevens vervolgens op te slaan in een Python-vriendelijke gegevensstructuur. Nu u een databaseverbinding tot stand heeft gebracht, kunt u een SQL-query schrijven om gegevens op te halen:
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"Het werk is echter nog niet gedaan. Je moet wat extra Python-code schrijven die de SQL-query uitvoert:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()Vervolgens moet u de geretourneerde gegevens opslaan in een panda-gegevensframe:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
print(raw_initial_df)Je zou een panda-dataframe (raw_initial_df) moeten krijgen dat er ongeveer zo uitziet:
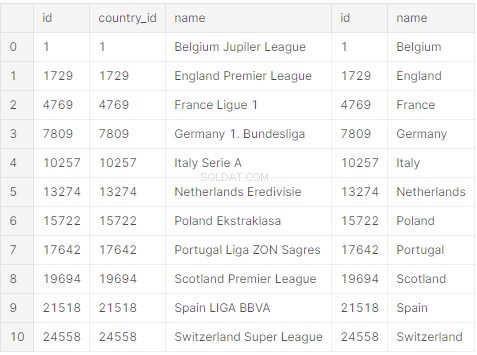
Er is een database voor iedereen

SQLite, MySQL en PostgreSQL hebben allemaal hun voor- en nadelen. Degene die u selecteert, moet afhangen van uw project of de behoeften van uw bedrijf. Je moet ook overwegen wat je nu nodig hebt in plaats van over een aantal jaren.
Het belangrijkste om te onthouden is dat Python met elk databasetype kan worden geïntegreerd.
Dit artikel schetst de oppervlakte voor wat mogelijk is door Python te verbinden met een SQL-database. Ik vind het geweldig om te zien hoe software elkaar kruist en combineert om ongelooflijke waarde toe te voegen.
Als je meer van dit soort inhoud wilt, kun je me vinden op Course to Hire! Ik wil meer mensen helpen te leren coderen en een baan in de techniek te vinden. Neem contact op voor vragen of als je gewoon hallo wilt zeggen :)