Een voorbeeld waar dit een verschil kan maken, is dat het een prestatie-optimalisatie kan voorkomen die voorkomt dat informatie over rijversies wordt toegevoegd aan tabellen met after-triggers.
Dit wordt hier behandeld door Paul White
De werkelijke grootte van de opgeslagen gegevens is niet van belang - het is de potentiële grootte die ertoe doet.
Evenzo is het bij het gebruik van voor geheugen geoptimaliseerde tabellen sinds 2016 mogelijk om LOB-kolommen of combinaties van kolombreedten te gebruiken die mogelijk de inrow-limiet zouden kunnen overschrijden, maar met een boete.
(Max) kolommen worden altijd off-row opgeslagen. Voor andere kolommen, als de gegevensrijgrootte in de tabeldefinitie 8.060 bytes kan overschrijden, duwt SQL Server de grootste kolom(men) met variabele lengte buiten de rij. Nogmaals, het hangt niet af van de hoeveelheid gegevens die u daar opslaat.
Dit kan een groot negatief effect hebben op het geheugenverbruik en de prestaties
Een ander geval waarbij het opgeven van kolombreedten een groot verschil kan maken, is of de tabel ooit met SSIS zal worden verwerkt. Het geheugen dat is toegewezen voor kolommen met variabele lengte (niet-BLOB) is vast voor elke rij in een uitvoeringsstructuur en is volgens de opgegeven maximale lengte van de kolommen, wat kan leiden tot inefficiënt gebruik van geheugenbuffers (voorbeeld). Hoewel de ontwikkelaar van het SSIS-pakket een kleinere kolomgrootte dan de bron kan aangeven, kan deze analyse het beste vooraf worden gedaan en daar worden afgedwongen.
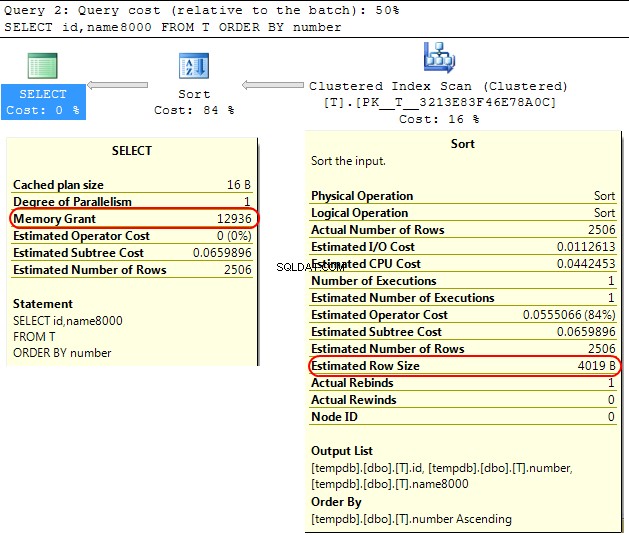
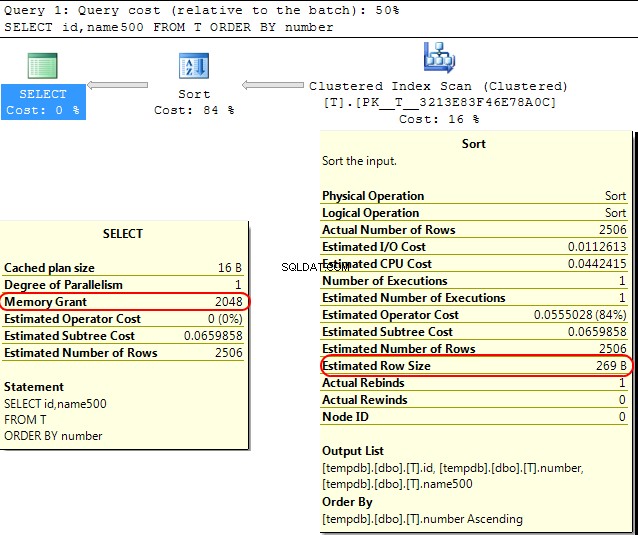
Terug in de SQL Server-engine zelf is een soortgelijk geval dat bij het berekenen van de geheugentoekenning die moet worden toegewezen voor SORT operaties SQL Server gaat ervan uit dat varchar(x) kolommen verbruiken gemiddeld x/2 bytes.
Als de meeste van uw varchar kolommen zijn voller dan dat dit kan leiden tot de sort bewerkingen lopen over naar tempdb .
In uw geval als uw varchar kolommen worden gedeclareerd als 8000 bytes, maar hebben in feite veel minder inhoud dan dat uw query geheugen krijgt toegewezen dat niet nodig is, wat duidelijk inefficiënt is en kan leiden tot wachten op geheugentoekenningen.
Dit wordt behandeld in deel 2 van SQL Workshops Webcast 1 die hier kan worden gedownload of hieronder kan worden bekeken.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number