De operators ROLLUP en CUBE worden gebruikt om resultaten te retourneren die zijn geaggregeerd door de kolommen in de GROUP BY-component.
De functies GROUPING en GROUPING_ID worden gebruikt om te bepalen of de kolommen in de GROUP BY-lijst zijn geaggregeerd (met behulp van de operators ROLLUP of CUBE) of niet.
Er zijn twee grote verschillen tussen de GROUPING- en GROUPING_ID-functies.
Ze zijn als volgt:
- De GROUPING-functie is van toepassing op een enkele kolom, terwijl de kolomlijst voor de GROUPING_ID-functie moet overeenkomen met de kolomlijst in de GROUP BY-component.
- De GROUPING-functie geeft aan of een kolom in de GROUP BY-lijst is geaggregeerd of niet. Het retourneert 1 als de resultatenset is geaggregeerd en 0 als de resultaatset niet is geaggregeerd.
Aan de andere kant retourneert de functie GROUPING_ID ook een geheel getal. Het voert echter de binaire naar decimale conversie uit na het aaneenschakelen van de uitkomst van alle GROUPING-functies.
In dit artikel zullen we de functies GROUPING en GROUPING_ID in actie zien aan de hand van voorbeelden.
Sommige dummy-gegevens voorbereiden
Laten we zoals altijd enkele dummy-gegevens maken die we gaan gebruiken voor het voorbeeld waarmee we in dit artikel zullen werken.
Voer het volgende script uit:
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
In het bovenstaande script hebben we een database gemaakt met de naam "Bedrijf". We hebben vervolgens een tabel "Werknemer" gemaakt in de bedrijfsdatabase. Ten slotte hebben we enkele dummy-records ingevoegd in de tabel Werknemers.
GROUPING-functie
Zoals hierboven vermeld, retourneert de GROUPING-functie 1 als de resultaatset is geaggregeerd en 0 als de resultaatset niet is geaggregeerd.
Bekijk het volgende script om de GROUPING-functie in actie te zien.
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
Het bovenstaande script telt de som van de salarissen van alle mannelijke en vrouwelijke werknemers, die eerst zijn gegroepeerd op de kolom Afdeling en vervolgens op de kolom Geslacht. Er zijn nog twee kolommen toegevoegd om het resultaat weer te geven van de GROUPING-functie die is toegepast op de kolommen Afdeling en Geslacht.
De operator ROLLUP wordt gebruikt om de som van de salarissen weer te geven in de vorm van eindtotalen en subtotalen.
De uitvoer van het bovenstaande script ziet er als volgt uit.
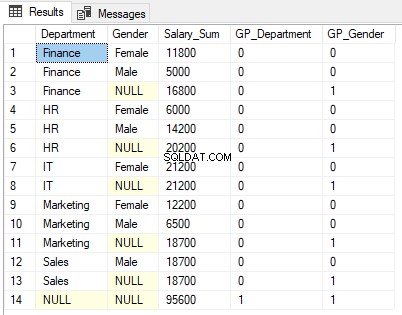
Kijk goed naar de output. De som van de salarissen wordt weergegeven per geslacht per afdelingsgeslacht (rijen 1, 2, 4, 5, 7, 9, 10 en 12). Het wordt dan ook alleen geaggregeerd naar geslacht (rijen 3, 6, 8, 11 en 13). Ten slotte wordt het totaal van de salarissen geaggregeerd door zowel afdeling als geslacht weergegeven in rij 14.
1 wordt weergegeven in de GROUPING-functiekolom GP_Gender voor rijen waar de resultaten worden geaggregeerd op geslacht, d.w.z. rijen 3, 6, 8, 11 en 13. Dit komt omdat de GP_Gender-kolom het resultaat bevat van de GROUPING-functie die is toegepast op de kolom Geslacht.
Evenzo bevat rij 14 de geaggregeerde som van alle afdelingen en alle kolommen. Daarom wordt 1 geretourneerd voor zowel de kolom GP_Department als GP_Gender.
U kunt zien dat NULL wordt weergegeven in de kolommen Afdeling en Geslacht in de uitvoer waar de resultaten worden verzameld. In rij 3 wordt bijvoorbeeld NULL weergegeven in de kolom Geslacht omdat de resultaten worden geaggregeerd per kolom geslacht en er dus geen kolomwaarde is om weer te geven. We willen niet dat onze gebruikers NULL zien, een beter woord hier zou kunnen zijn:"Alle geslachten".
Om dit te doen, moeten we ons script als volgt aanpassen:
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
In het bovenstaande script, als de GROUPING-functie toegepast op de Afdeling-kolom 1 retourneert en "Alle Afdelingen" wordt weergegeven in de Afdeling-kolom. Anders, als de kolom Afdeling de waarde NULL bevat, wordt "Onbekend" weergegeven. De geslachtskolom is op dezelfde manier aangepast.
Het uitvoeren van het bovenstaande script levert de volgende resultaten op:
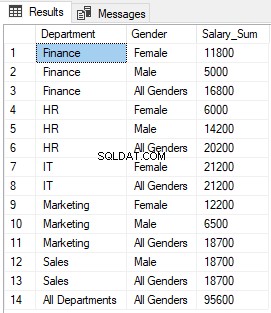
U kunt zien dat NULL in de kolommen Afdeling en Geslacht waar de functie GROEPEREN 1 retourneert, is vervangen door respectievelijk "Alle afdelingen" en "Alle geslachten".
GROUPING_ID Functie
De functie GROUPING_ID voegt de uitvoer van de GROUPING-functies samen die zijn toegepast op alle kolommen die zijn opgegeven in de GROUP BY-component. Het voert vervolgens binaire naar decimale conversie uit voordat de uiteindelijke uitvoer wordt geretourneerd.
Laten we eerst de uitvoer samenvoegen die wordt geretourneerd door de GROUPING-functie die is toegepast op de kolommen Afdeling en Geslacht. Bekijk het volgende script:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
In de uitvoer ziet u nullen en enen die worden geretourneerd door de GROUPING-functie, samengevoegd. De uitvoer ziet er als volgt uit:
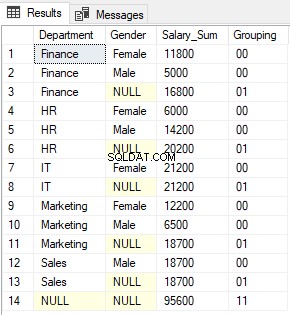
De functie GROUPING_ID retourneert eenvoudig het decimale equivalent van de binaire waarde die is gevormd als resultaat van de aaneenschakeling van de waarden die worden geretourneerd door de GROUPING-functies.
Voer het volgende script uit om de GROUPING ID-functie in actie te zien:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
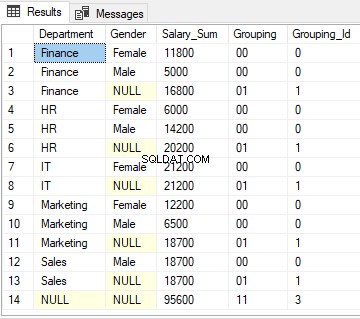
Voor rij 1 retourneert de GROUPING ID-functie 0 omdat het decimale equivalent van '00' nul is.
Voor rijen 3, 6, 8, 11 en 13 retourneert de functie GROUPING_ID 1 omdat het decimale equivalent van '01' 1 is.
Ten slotte, voor rij 14, retourneert de functie GROUPIND_ID 3, aangezien het binaire equivalent van '11' 3 is.
De uitvoer van het bovenstaande script ziet er als volgt uit:
Zie ook:
Microsoft:Grouping_ID Overzicht
Microsoft:overzicht van groepen
YouTube:groeperen en groeperen_ID