MySQL is eenvoudig te installeren en te gebruiken, het is altijd populair geweest bij ontwikkelaars en systeembeheerders. Aan de andere kant is het implementeren van een productieklare MySQL-omgeving voor een bedrijfskritische enterprise-workload een ander verhaal. Het kan een beetje een uitdaging zijn en vereist diepgaande kennis van de database. In deze blogpost bespreken we enkele van de stappen die moeten worden genomen voordat we onze MySQL-implementatie productieklaar kunnen beschouwen.
Hoge beschikbaarheid

Als u tot de gelukkigen behoort die uren downtime kunnen accepteren, kunt u hier stoppen met lezen en doorgaan naar de volgende paragraaf. Voor 99,999% van de bedrijfskritische systemen zou dit niet acceptabel zijn. Daarom moet een productieklare implementatie maatregelen voor hoge beschikbaarheid omvatten. Geautomatiseerde failover van de database-instances, evenals een proxylaag die veranderingen in de topologie en status van MySQL detecteert en het verkeer dienovereenkomstig routeert, zou een belangrijke vereiste zijn. Er zijn talloze tools die kunnen worden gebruikt om dergelijke omgevingen te bouwen, bijvoorbeeld MHA, MRM of ClusterControl.
Proxylaag
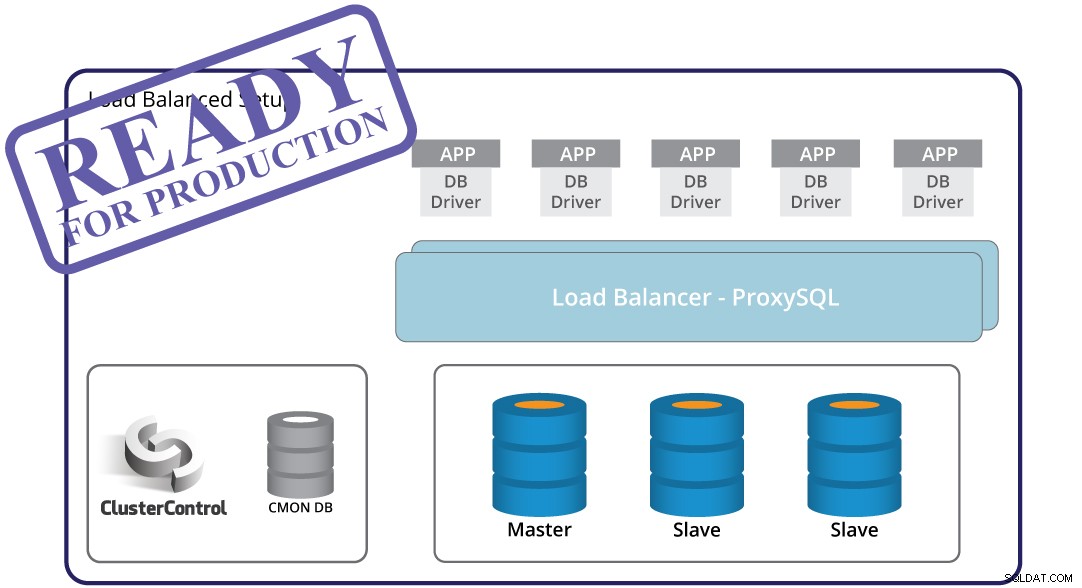
Masterfoutdetectie, geautomatiseerde failover en herstel - deze zijn cruciaal bij het bouwen van een productieklare infrastructuur. Maar op zichzelf is het niet genoeg. Er is nog steeds een applicatie die zich zal moeten aanpassen aan de topologieverandering die wordt veroorzaakt door de failover. Natuurlijk is het mogelijk om de applicatie te coderen zodat deze op de hoogte is van instantiefouten. Dit is echter een omslachtige en inflexibele manier om topologieveranderingen af te handelen. Hier komt de databaseproxy - een middenlaag tussen applicatie en database. Een proxy kan de complexiteit van uw databaselaag voor de applicatie verbergen - het enige wat de applicatie doet is verbinding maken met de proxy en de proxy doet de rest. De proxy zal query's naar een database-instantie routeren, topologiewijzigingen afhandelen en indien nodig opnieuw routeren. Een proxy kan ook worden gebruikt om lees-schrijfsplitsing te implementeren, waardoor de toepassing van een complexere casus wordt ontlast. Dit creëert een nieuwe uitdaging - welke proxy moet ik gebruiken? Hoe het te configureren? Hoe het te monitoren? Hoe maak je het zeer beschikbaar, zodat het geen SPOF wordt?
ClusterControl kan hierbij helpen. Het kan worden gebruikt om verschillende proxy's in te zetten om een proxylaag te vormen:ProxySQL, HAProxy en MaxScale. Het configureert proxy's vooraf om ervoor te zorgen dat ze het verkeer correct afhandelen. Het maakt het ook gemakkelijk om configuratiewijzigingen door te voeren als u de proxyconfiguratie voor uw toepassing moet aanpassen. Splitsen van lezen en schrijven kan worden geconfigureerd met behulp van een van de proxy's die ClusterControl ondersteunt. ClusterControl bewaakt ook de proxy's en herstelt deze bij storingen. De proxylaag kan een single point of failure worden, omdat geautomatiseerd herstel misschien niet genoeg is - om dat aan te pakken, kan ClusterControl Keepalive inzetten en Virtual IP configureren om failover te automatiseren.
Back-ups
Zelfs als u geen hoge beschikbaarheid hoeft te implementeren, moet u waarschijnlijk toch om uw gegevens geven. Back-up is een must voor bijna elke productiedatabase. Niets anders dan een back-up kan je redden van een onbedoelde DROP TABLE of DROP SCHEMA (nou ja, misschien een vertraagde replicatieslave, maar slechts voor een bepaalde periode). MySQL biedt meerdere methoden voor het maken van back-ups - mysqldump, xtrabackup, verschillende soorten snapshots (sommige alleen beschikbaar bij bepaalde hardware of cloudprovider). Het is niet eenvoudig om de juiste back-upstrategie te ontwerpen, te beslissen welke tools te gebruiken en vervolgens het hele proces te scripten zodat het correct wordt uitgevoerd. Het is ook geen rocket science en vereist zorgvuldige planning en testen. Zodra een back-up is gemaakt, bent u nog niet klaar. Weet u zeker dat de back-up kan worden hersteld en dat de gegevens geen afval zijn? Het verifiëren van uw back-ups is tijdrovend en misschien niet het meest opwindende dat u op uw takenlijst zult hebben. Maar het is nog steeds belangrijk en moet regelmatig worden gedaan.
ClusterControl heeft uitgebreide back-up- en herstelfunctionaliteit. Het ondersteunt mysqldump voor logische back-up en Percona Xtrabackup voor fysieke back-up - deze tools kunnen in bijna elke omgeving worden gebruikt, zowel in de cloud als on-premises. Het is mogelijk om online een back-upstrategie te bouwen met een mix van logische en fysieke back-ups, incrementeel of volledig.
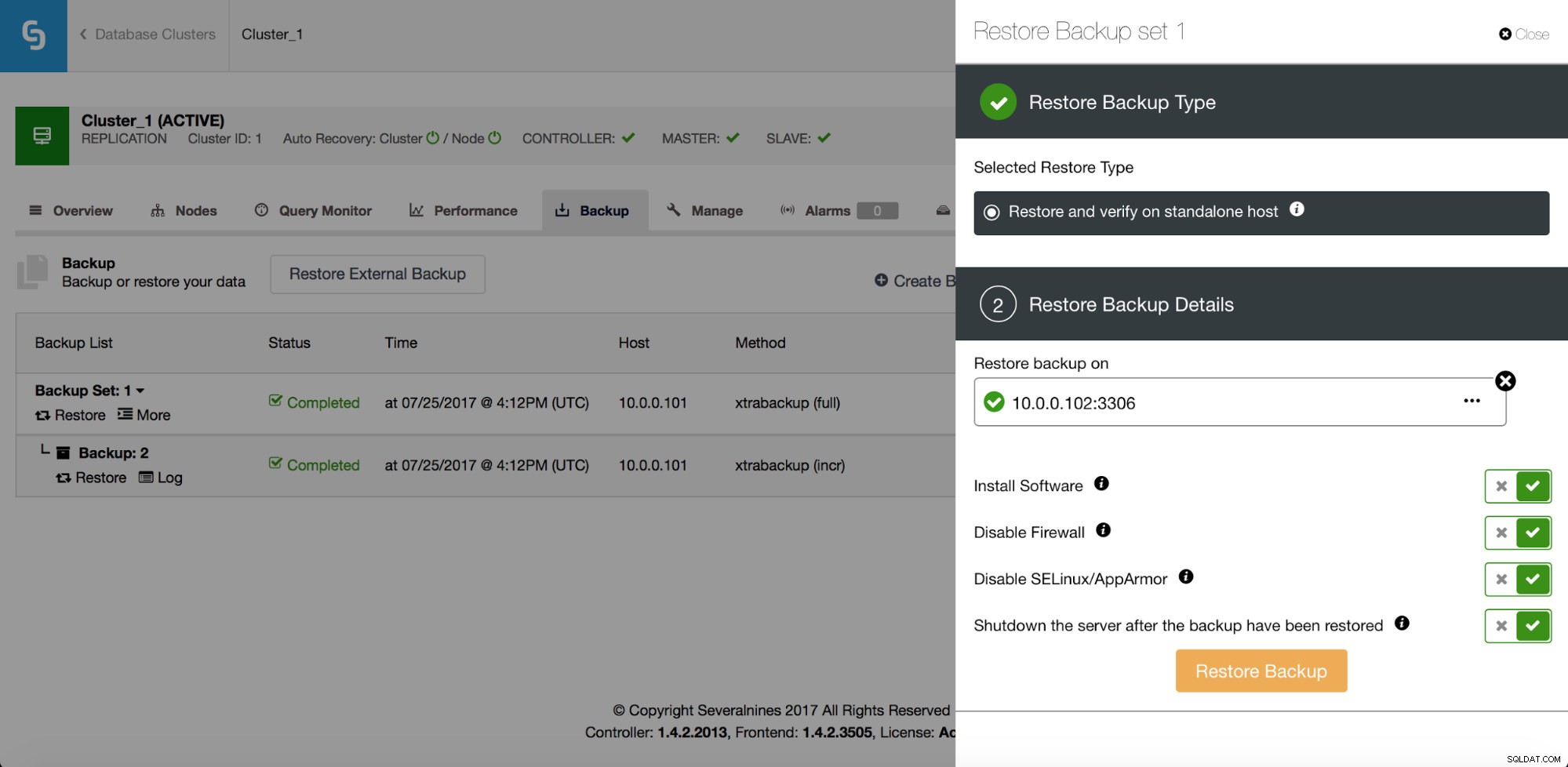
Afgezien van herstel, heeft het ook opties om een back-up te verifiëren - bijvoorbeeld het terugzetten op een aparte host om te controleren of het back-upproces goed werkt of niet.
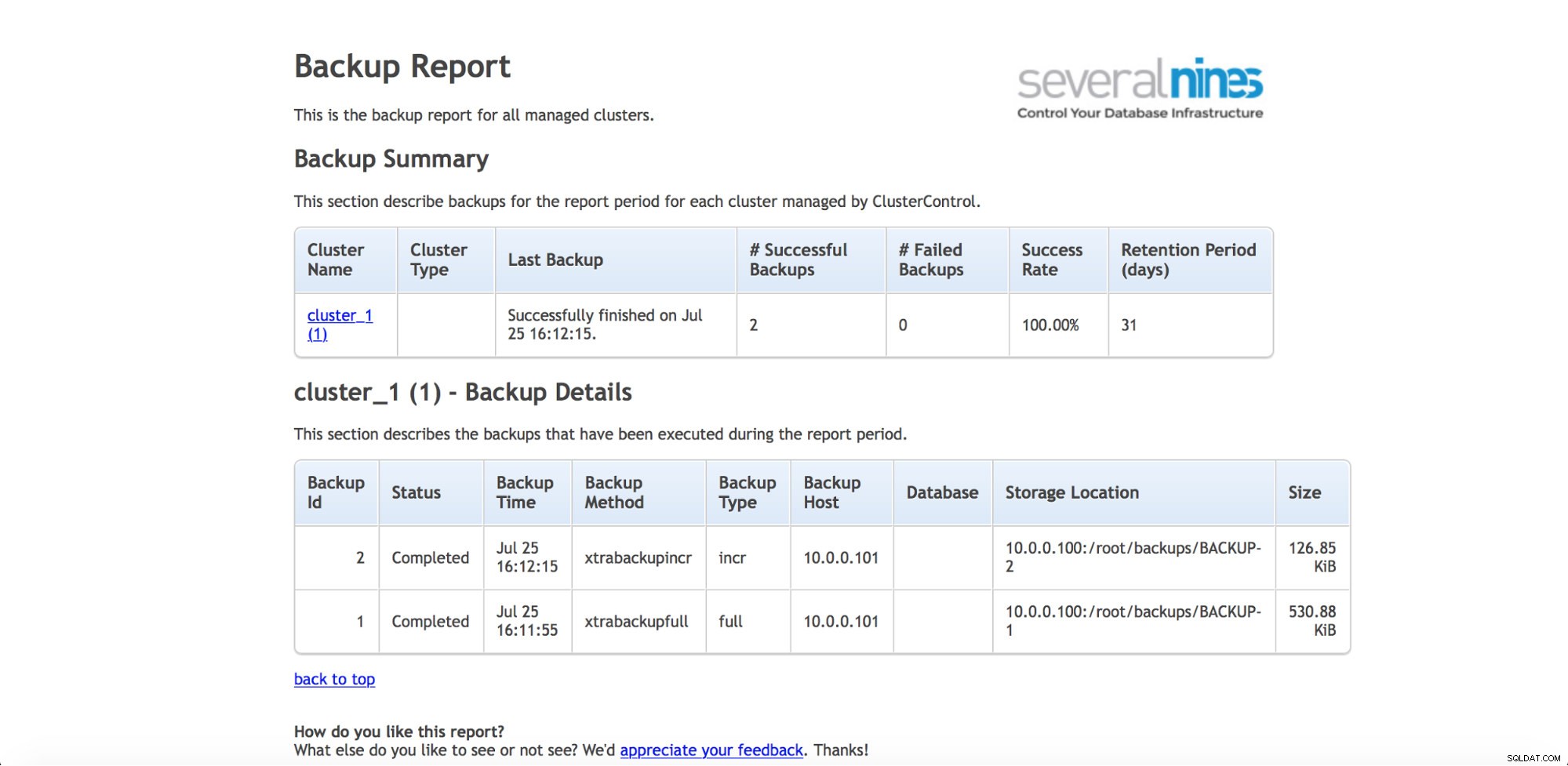
Als je regelmatig de back-ups in de gaten wilt houden (en dat zou je waarschijnlijk ook willen), dan heeft ClusterControl de mogelijkheid om operationele rapportages te genereren. Het back-uprapport helpt u bij het volgen van uitgevoerde back-ups en informeert of er problemen waren tijdens het maken ervan.
DevOps-gids voor databasebeheer van verschillendenines Lees meer over wat u moet weten om uw open source-databases te automatiseren en beherenGratis downloadenBewaking en trending

Geen enkele implementatie is klaar voor productie zonder een goede monitoring van de services. U wilt er zeker van zijn dat u wordt gewaarschuwd als bepaalde services niet meer beschikbaar zijn, zodat u actie kunt ondernemen, onderzoek kunt doen of herstelprocedures kunt starten. Natuurlijk wilt u ook een trending-oplossing hebben. Het kan niet genoeg benadrukt worden hoe belangrijk het is om monitoringgegevens te hebben voor het beoordelen van de staat van de infrastructuur of voor elk onderzoek, post-mortem of realtime monitoring van de staat van diensten. Statistieken zijn niet even belangrijk - als u niet erg bekend bent met een bepaald databaseproduct, weet u waarschijnlijk niet welke de belangrijkste statistieken zijn om te verzamelen en te bekijken. Natuurlijk kun je misschien alles verzamelen, maar als het gaat om het beoordelen van gegevens, is het nauwelijks mogelijk om honderden statistieken per host te doorlopen - je moet weten op welke daarvan je je moet concentreren.
De open source-wereld zit vol met tools die zijn ontworpen om statistieken uit verschillende databases te bewaken en te verzamelen - voor de meeste zou je ze moeten integreren met je algehele monitoring-infrastructuur, chatops-platform of oncall-ondersteuningstools (zoals PagerDuty). Het kan ook nodig zijn om meerdere componenten te installeren en te integreren - opslag (een soort tijdreeksdatabase), presentatielaag en tools voor gegevensverzameling.
ClusterControl is een iets andere benadering, omdat het één enkel product is met realtime monitoring, trending en dashboards die de belangrijkste details tonen. Databaseadviseurs, die van alles kunnen zijn, van eenvoudig configuratieadvies, waarschuwingen voor drempels of complexere regels voor voorspellingen, zouden over het algemeen uitgebreide aanbevelingen doen.
Mogelijkheid om op te schalen

Databases hebben de neiging om in omvang te groeien, en het is niet onwaarschijnlijk dat dit zou groeien in termen van transactievolumes of aantal gebruikers. Het vermogen om uit of op te schalen kan van cruciaal belang zijn voor de productie. Zelfs als u aan het begin van de productlevenscyclus uitstekend werk verricht door uw hardwarevereisten in te schatten, zult u waarschijnlijk een groeifase moeten doormaken - zolang uw product succesvol is, tenminste (maar daar zijn we allemaal op van plan, toch ?). U moet over de middelen beschikken om uw infrastructuur eenvoudig op te schalen om de inkomende belasting aan te kunnen. Voor stateless services zoals webservers is dit vrij eenvoudig - u hoeft alleen maar meer instances in te richten met behulp van de nieuwste productie-image of code van uw versiebeheertool. Voor stateful services zoals databases is het lastiger. U moet nieuwe instances inrichten met uw huidige productiegegevens, replicatie of een vorm van clustering tussen de huidige en de nieuwe instances instellen. Dit kan een complex proces zijn en om het goed te doen, moet u meer diepgaande kennis hebben van het gekozen clustering- of replicatiemodel.
ClusterControl biedt, zoals de naam al doet vermoeden, uitgebreide ondersteuning voor het uitbouwen van geclusterde of gerepliceerde database-instellingen. De gebruikte methoden zijn in de strijd getest door duizenden implementaties. Het wordt geleverd met een Command Line Interface (CLI), zodat het eenvoudig kan worden geïntegreerd met configuratiebeheersystemen. Houd er echter rekening mee dat u misschien niet te vaak wijzigingen in uw pool van databases wilt aanbrengen - het inrichten van een nieuwe instantie kost tijd en voegt wat overhead toe aan bestaande databases. Daarom wil je misschien een beetje aan de "over-provisioned" kant blijven, zodat je wat tijd hebt om een nieuwe instantie op te starten voordat je cluster overbelast raakt.
Al met al zijn er een aantal stappen die u na de eerste implementatie nog moet nemen om ervoor te zorgen dat uw omgeving klaar is voor productie. Met de juiste tools is het veel gemakkelijker om daar te komen.