Wanneer u moet werken met een database waarmee u niet 100% vertrouwd bent, kunt u overweldigd worden door de honderden beschikbare statistieken. Welke zijn het belangrijkst? Waar moet ik op letten en waarom? Welke patronen in statistieken zouden alarmbellen moeten doen rinkelen? In deze blogpost zullen we proberen je kennis te laten maken met enkele van de belangrijkste statistieken die je in de gaten moet houden tijdens het draaien van MySQL of MariaDB in productie.
Com_* Statustellers
We beginnen met Com_*-tellers - die bepalen het aantal en de soorten query's die MySQL uitvoert. We hebben het hier over querytypes zoals SELECT, INSERT, UPDATE en nog veel meer. Het is heel belangrijk om deze in de gaten te houden, omdat plotselinge pieken of onverwachte dalingen erop kunnen wijzen dat er iets mis is gegaan in het systeem.
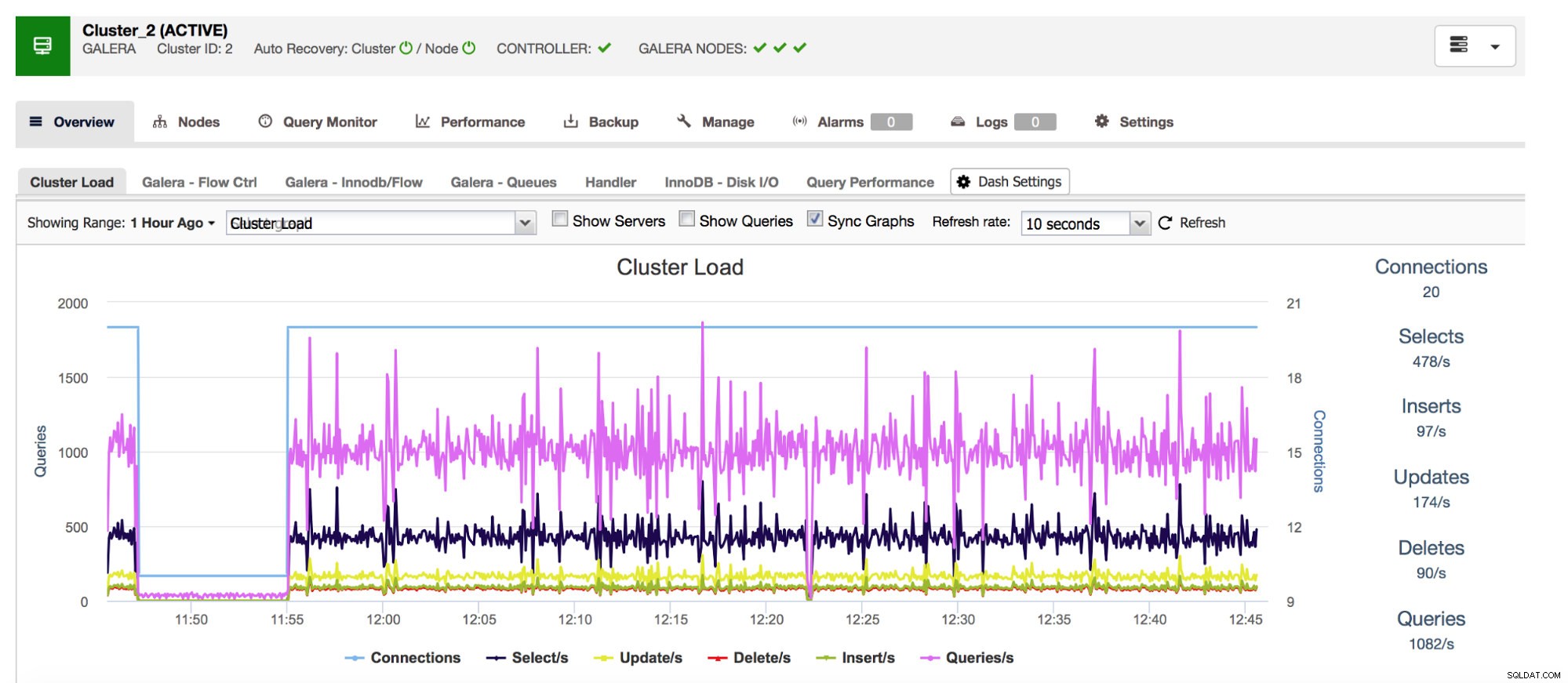
Ons all-inclusive databasebeheersysteem ClusterControl toont u deze gegevens met betrekking tot de meest voorkomende querytypen in het gedeelte "Overzicht".
Handler_* Statustellers
Een categorie met statistieken die u in de gaten moet houden, zijn Handler_*-tellers in MySQL. Com_*-tellers vertellen u wat voor soort query's uw MySQL-instantie uitvoert, maar de ene SELECT kan totaal anders zijn dan de andere - SELECT kan een primaire sleutelzoekopdracht zijn, het kan ook een tabelscan zijn als een index niet kan worden gebruikt. Handlers vertellen u hoe MySQL toegang krijgt tot opgeslagen gegevens - dit is erg handig om de prestatieproblemen te onderzoeken en te beoordelen of er mogelijk winst is bij het beoordelen van zoekopdrachten en aanvullende indexering.
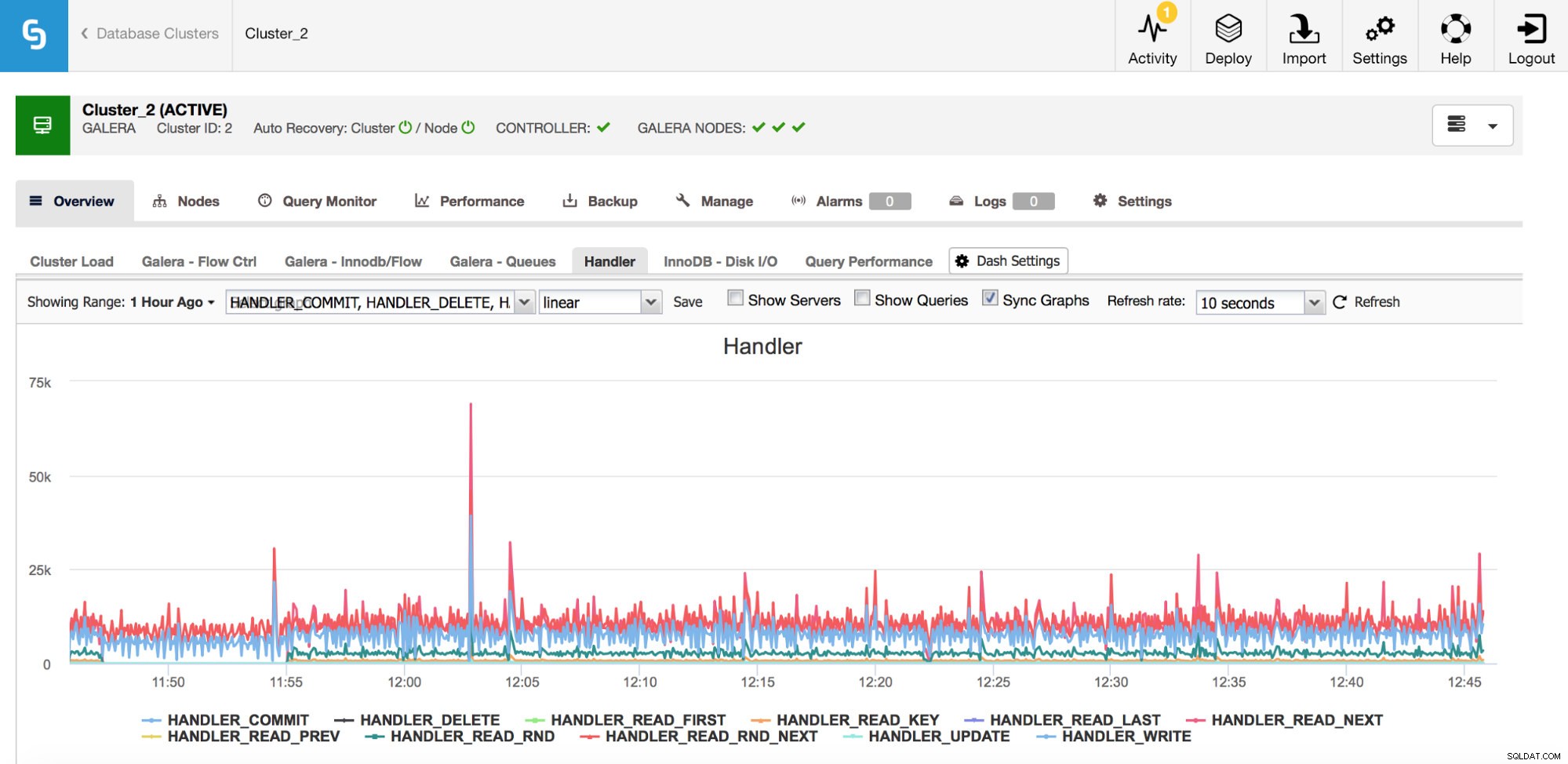
Zoals u in de bovenstaande grafiek kunt zien, zijn er veel statistieken om bij te houden (en ClusterControl geeft de belangrijkste grafieken weer) - we zullen ze hier niet allemaal behandelen (u kunt beschrijvingen vinden in de MySQL-documentatie), maar we willen graag de nadruk leggen op de belangrijkste.
Handler_read_rnd_next - wanneer MySQL een rij benadert zonder een index-lookup, in sequentiële volgorde, wordt deze teller verhoogd. Als in uw werkbelasting handler_read_rnd_next verantwoordelijk is voor een hoog percentage van het totale verkeer, betekent dit dat uw tabellen hoogstwaarschijnlijk wat extra indexen kunnen gebruiken omdat MySQL veel tabelscans uitvoert.
Handler_read_next en handler_read_prev - die twee tellers worden bijgewerkt wanneer MySQL een indexscan uitvoert - vooruit of achteruit. Handler_read_first en handler_read_last kunnen wat meer licht werpen op wat voor soort indexscans dat zijn - als we het hebben over volledige indexscan (vooruit of achteruit), worden die twee tellers bijgewerkt.
Handler_read_key - deze teller, aan de andere kant, als zijn waarde hoog is, vertelt u dat uw tabellen goed zijn geïndexeerd omdat veel van de rijen zijn benaderd via een indexzoekopdracht.
Replicatievertraging
Als u met MySQL-replicatie werkt, is replicatievertraging een statistiek die u zeker wilt controleren. Replicatievertraging is onvermijdelijk en je zult ermee moeten omgaan, maar om ermee om te gaan, moet je begrijpen waarom het gebeurt. Daarvoor is de eerste stap om te weten _when_ het verscheen.
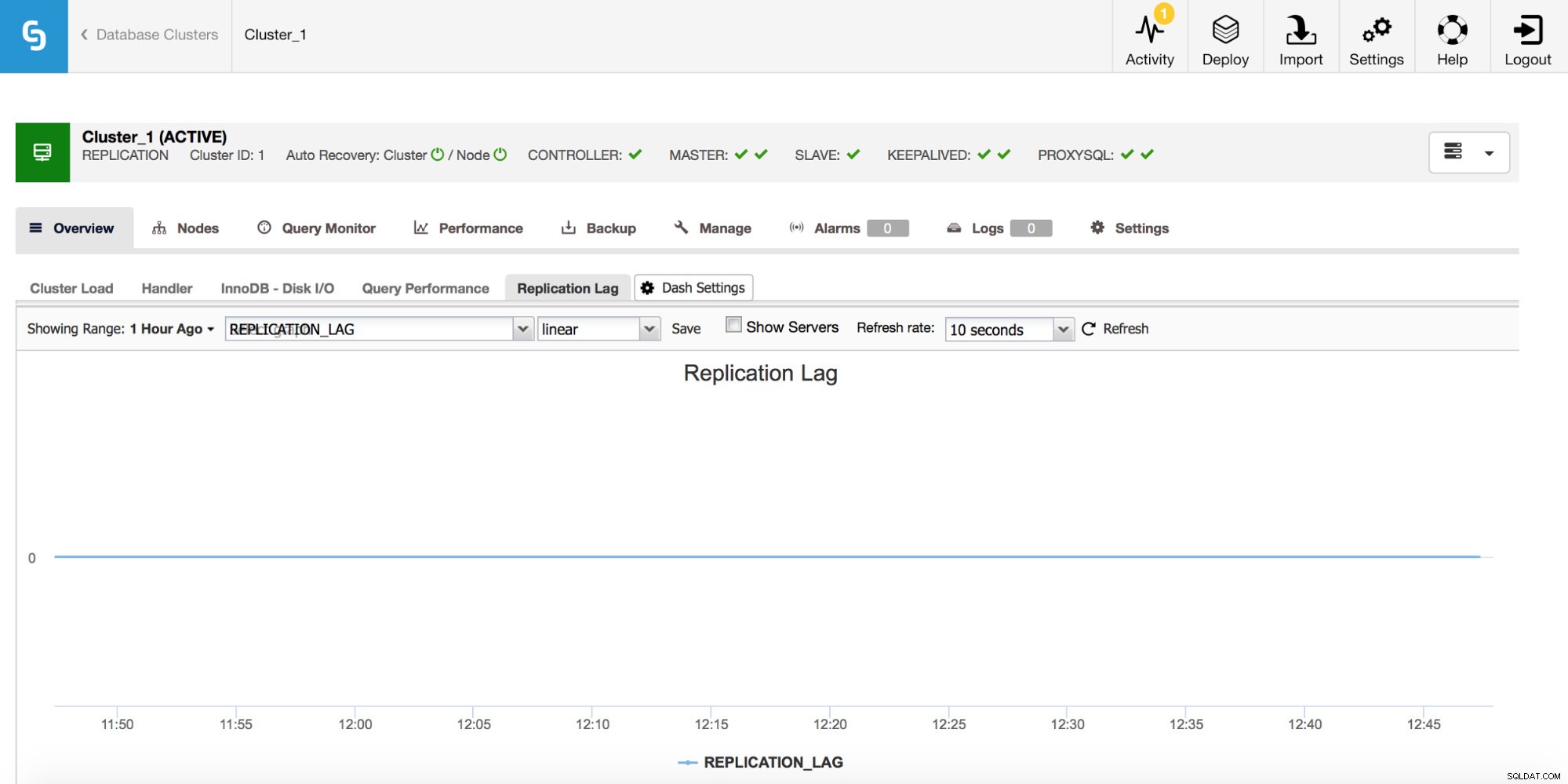
Telkens wanneer u een piek in de replicatievertraging ziet, wilt u andere grafieken bekijken om meer aanwijzingen te krijgen - waarom is dit gebeurd? Wat kan het hebben veroorzaakt? De redenen kunnen verschillen:lange, zware DML's, aanzienlijke toename van het aantal DML's dat in korte tijd wordt uitgevoerd, CPU- of I/O-beperkingen.
InnoDB I/O
Er zijn een aantal belangrijke meetwaarden om te controleren die gerelateerd zijn aan de I/O.
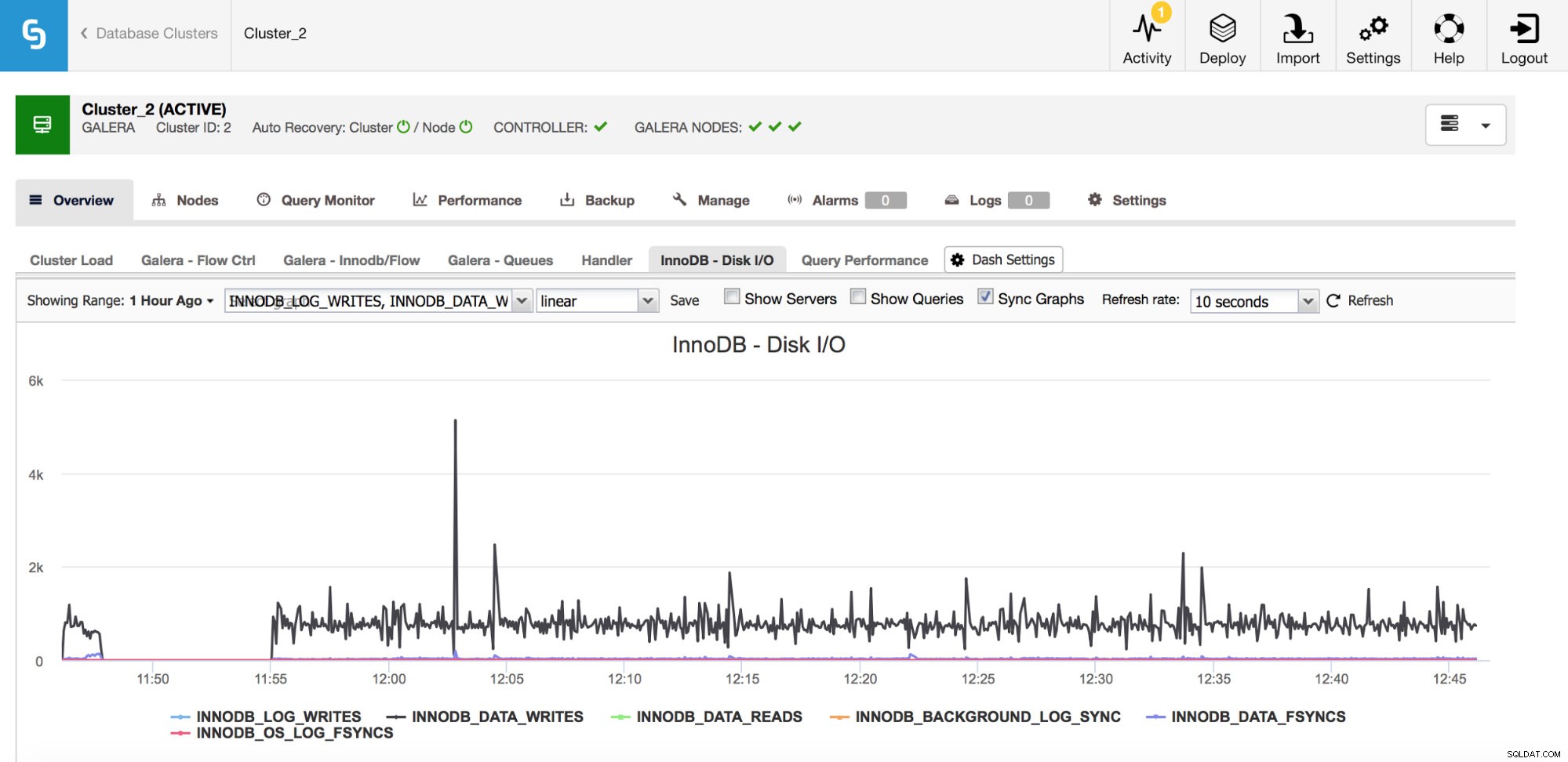
In de bovenstaande grafiek kun je een aantal statistieken zien die je vertellen wat voor soort I/O InnoDB doet - gegevens schrijven en lezen, log schrijven opnieuw doen, fsyncs. Die statistieken helpen u bijvoorbeeld te beslissen of de replicatievertraging werd veroorzaakt door een piek in I/O of misschien om een andere reden. Het is ook belangrijk om deze statistieken bij te houden en ze te vergelijken met uw hardwarebeperkingen - als u in de buurt komt van de hardwarelimieten van uw schijven, is het misschien tijd om dit te onderzoeken voordat het ernstigere gevolgen heeft voor uw databaseprestaties.
DevOps-gids voor databasebeheer van verschillendenines Lees meer over wat u moet weten om uw open source-databases te automatiseren en beherenGratis downloadenGalera-statistieken - stroomregeling en wachtrijen
Als je Galera Cluster gebruikt (ongeacht welke smaak je gebruikt), zijn er nog een paar statistieken die je nauwlettend in de gaten wilt houden, deze zijn enigszins met elkaar verbonden. De eerste zijn statistieken met betrekking tot flow control.
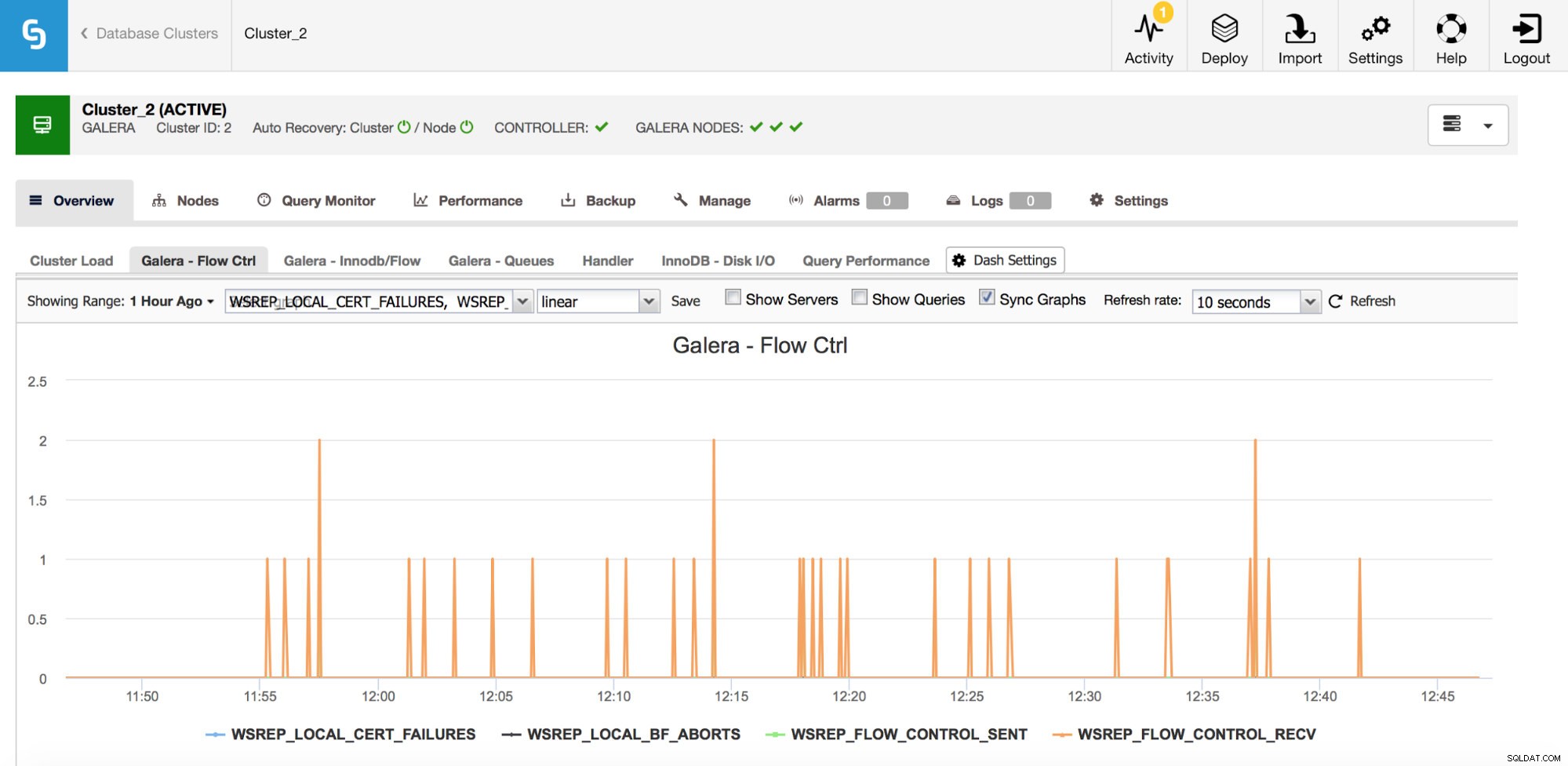
Flow control, in Galera, is een middel om het cluster synchroon te houden. Telkens wanneer een knooppunt vastloopt en de rest van het cluster niet bij kan houden, begint het stroomcontroleberichten te verzenden waarin de resterende clusterknooppunten worden gevraagd te vertragen. Hierdoor kan het inhalen. Dit vermindert de prestaties van het cluster, dus het is belangrijk om te kunnen zien welk knooppunt en wanneer het is begonnen met het verzenden van flow control-berichten. Dit kan een aantal van de vertragingen verklaren die gebruikers ervaren of het tijdvenster en de host beperken om te gebruiken voor verder onderzoek.
De tweede reeks meetwaarden die moet worden gecontroleerd, zijn die met betrekking tot wachtrijen voor verzenden en ontvangen in Galera.
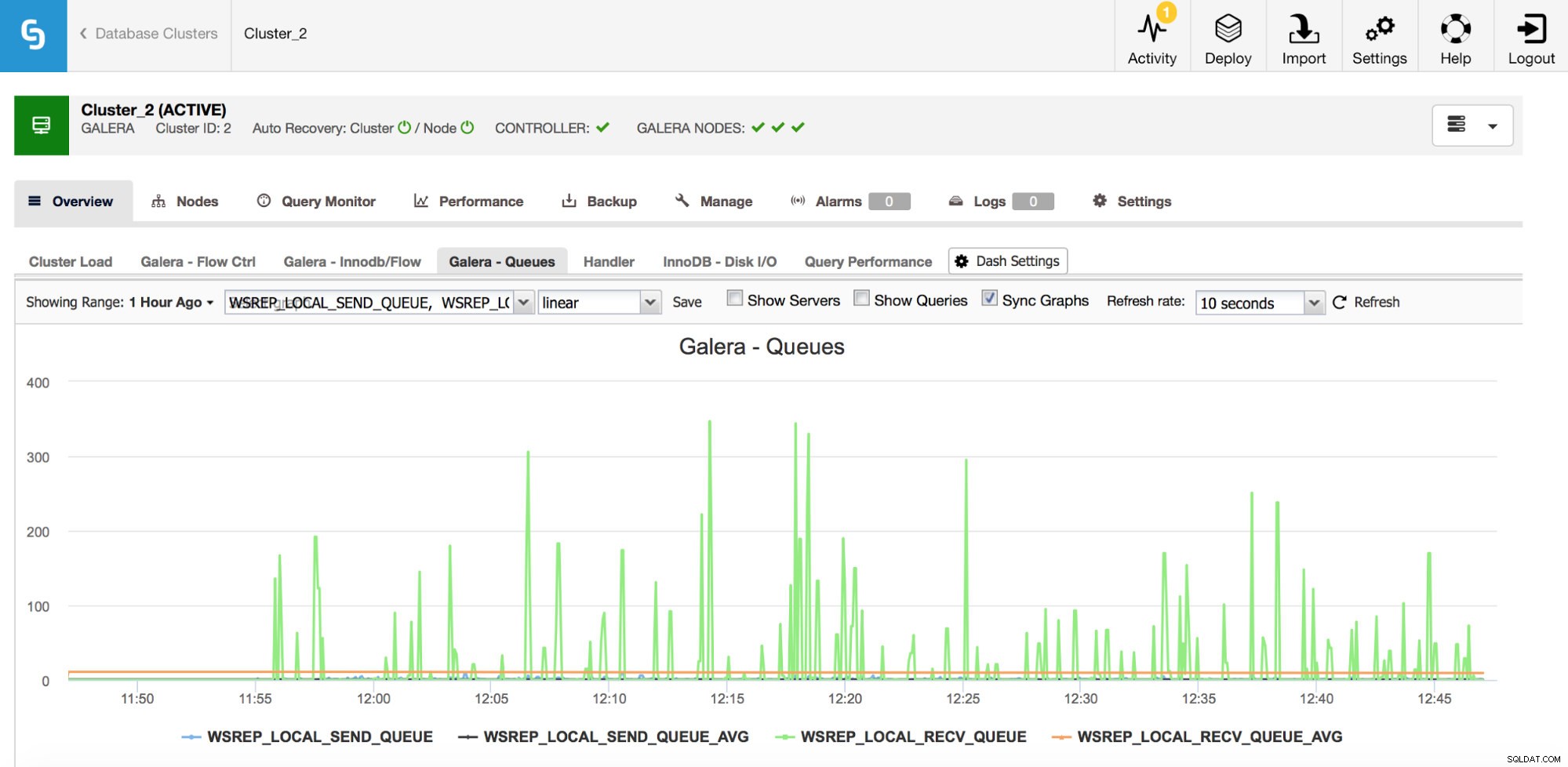
Galera-knooppunten kunnen schrijfsets (transacties) cachen als ze ze niet allemaal onmiddellijk kunnen toepassen. Indien nodig kunnen ze ook schrijfsets cachen die op het punt staan naar andere knooppunten te worden verzonden (als een bepaald knooppunt schrijfbewerkingen ontvangt van de toepassing). Beide gevallen zijn symptomen van een vertraging die hoogstwaarschijnlijk zal resulteren in het verzenden van berichten over de stroomregeling, en waarvoor enig onderzoek nodig is - waarom gebeurde het, op welk knooppunt, op welk tijdstip?
Dit is natuurlijk nog maar het topje van de ijsberg als we kijken naar alle statistieken die MySQL beschikbaar stelt - toch kun je niet fout gaan als je begint te kijken naar de statistieken die we hier hebben behandeld, naast de reguliere OS/hardware-statistieken zoals CPU , geheugen, schijfgebruik en status van de services.