Load balancers zijn een essentieel onderdeel van hoge beschikbaarheid van databases; vooral bij het transparant maken van topologiewijzigingen voor applicaties en het implementeren van lees-schrijf-splitfunctionaliteit. ClusterControl biedt een scala aan functies om de toonaangevende open source load balancing-technologieën in de branche veilig te implementeren, bewaken en configureren.
In het afgelopen jaar hebben we ondersteuning toegevoegd voor ProxySQL en meerdere verbeteringen toegevoegd voor HAProxy en MariaDB's Maxscale. We zetten deze traditie voort met de nieuwste release van ClusterControl 1.5.
Op basis van feedback die we van onze gebruikers hebben ontvangen, hebben we de manier waarop ProxySQL wordt beheerd, verbeterd. We hebben ook ondersteuning toegevoegd voor HAProxy en Keepalive om bovenop PostgreSQL-clusters te draaien.
In deze blogpost bekijken we deze verbeteringen...
ProxySQL - Verbeteringen in gebruikersbeheer
Voorheen kon je met de gebruikersinterface alleen een nieuwe gebruiker maken of een bestaande toevoegen, één voor één. Een feedback die we van onze gebruikers kregen, was dat het vrij moeilijk is om een groot aantal gebruikers te beheren. We hebben geluisterd en in ClusterControl 1.5 is het nu mogelijk om grote groepen gebruikers te importeren. Laten we eens kijken hoe u dat kunt doen. Allereerst moet u uw ProxySQL hebben geïmplementeerd. Ga vervolgens naar het ProxySQL-knooppunt en op het tabblad Gebruikers zou u een knop "Gebruikers importeren" moeten zien.

Zodra u erop klikt, wordt een nieuw dialoogvenster geopend:

Hier kunt u alle gebruikers zien die ClusterControl op uw cluster heeft gedetecteerd. Je kunt er doorheen scrollen en degene kiezen die je wilt importeren. U kunt ook alle gebruikers in een huidige weergave selecteren of deselecteren.

Zodra u begint te typen in het zoekvak, filtert ClusterControl niet-overeenkomende resultaten uit, waardoor de lijst alleen wordt beperkt tot gebruikers die relevant zijn voor uw zoekopdracht.
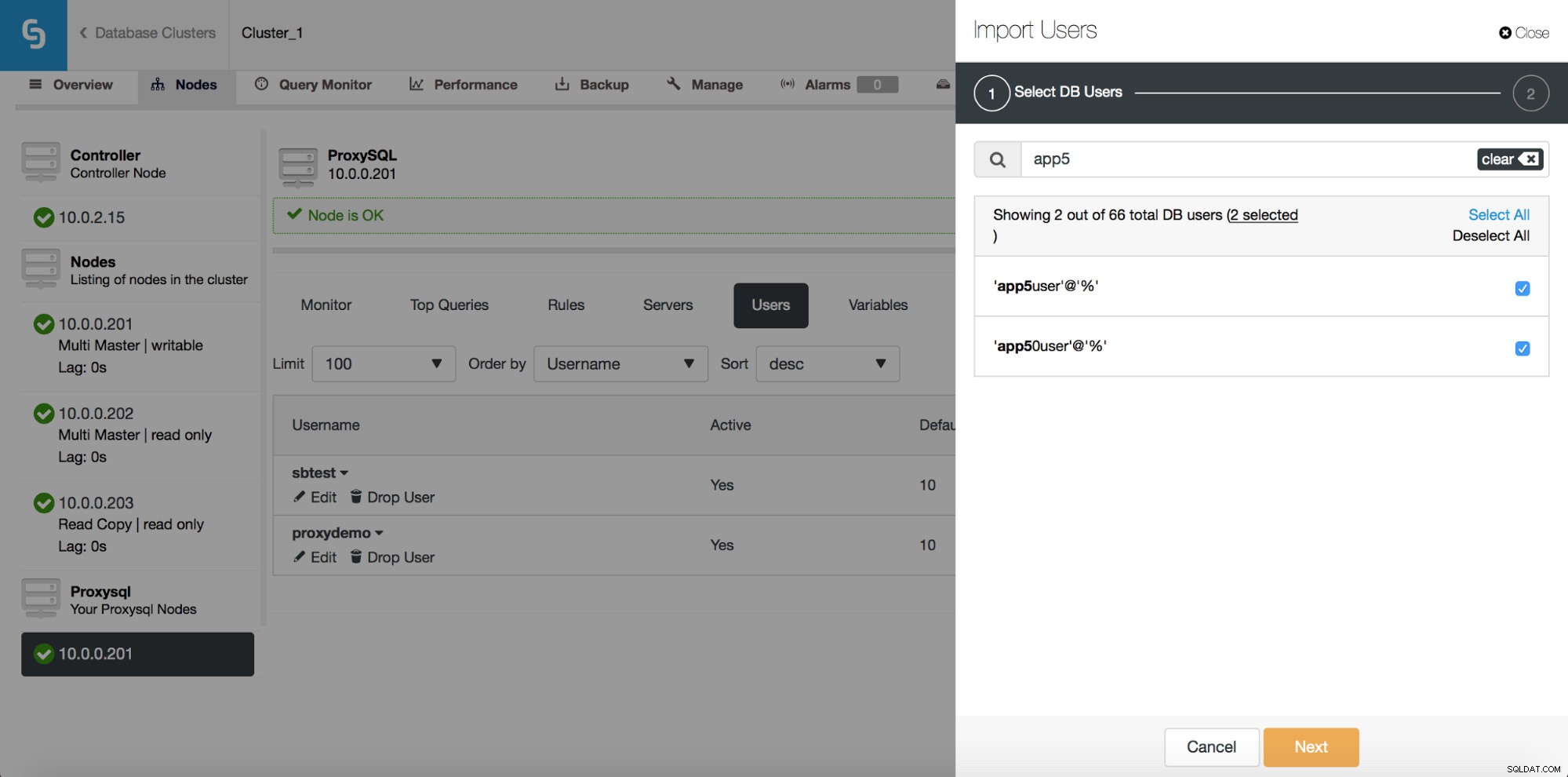
U kunt de knop "Alles selecteren" gebruiken om alle gebruikers te selecteren die overeenkomen met uw zoekopdracht. Nadat u gebruikers heeft geselecteerd die u wilt importeren, kunt u natuurlijk het zoekvak leegmaken en een nieuwe zoekopdracht starten:

Let op "(7 geselecteerd)" - het vertelt u hoeveel gebruikers in totaal (niet alleen van deze zoekopdracht), u hebt geselecteerd om te importeren. Je kunt er ook op klikken om alleen de gebruikers te zien die je hebt geselecteerd om te importeren.

Als u tevreden bent met uw keuze, kunt u op "Volgende" klikken om naar het volgende scherm te gaan.

Hier moet u beslissen wat de standaard hostgroep moet zijn voor elke gebruiker. U kunt dat per gebruiker of globaal doen, voor de hele set of een subset van gebruikers die het resultaat zijn van een zoekopdracht.

Zodra u op de knop "Gebruikers importeren" klikt, worden gebruikers geïmporteerd en verschijnen ze op het tabblad Gebruikers.
ProxySQL - Plannerbeheer
De planner van ProxySQL is een cron-achtige module waarmee ProxySQL met regelmatige tussenpozen externe scripts kan starten. Het schema kan behoorlijk gedetailleerd zijn - tot één uitvoering per milliseconde. Meestal wordt de planner gebruikt om Galera-controlescripts uit te voeren (zoals proxysql_galera_checker.sh), maar het kan ook worden gebruikt om elk ander script uit te voeren dat u leuk vindt. In het verleden gebruikte ClusterControl de planner om het Galera-controlescript te implementeren, maar dit was niet zichtbaar in de gebruikersinterface. Vanaf ClusterControl 1.5 heeft u nu volledige controle.

Zoals u kunt zien, is een script gepland om elke 2 seconden (2000 milliseconden) te worden uitgevoerd - dit is de standaardconfiguratie voor Galera-cluster.

De bovenstaande schermafbeelding toont ons opties voor het bewerken van bestaande vermeldingen. Houd er rekening mee dat ProxySQL maximaal 5 argumenten ondersteunt voor de scripts die het via de planner zal uitvoeren.

Als u een nieuw script aan de planner wilt toevoegen, kunt u op de knop "Nieuw script toevoegen" klikken en krijgt u een scherm zoals hierboven te zien. U kunt ook een voorbeeld bekijken van hoe het volledige script eruit zal zien wanneer het wordt uitgevoerd. Nadat u alle "Argument"-velden hebt ingevuld en het interval hebt gedefinieerd, kunt u op de knop "Nieuw script toevoegen" klikken.

Als gevolg hiervan wordt een script toegevoegd aan de planner en zal het zichtbaar zijn in de lijst met geplande scripts.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperPostgreSQL - De stapel met hoge beschikbaarheid bouwen
Het instellen van replicatie met automatische failover is goed, maar toepassingen hebben een eenvoudige manier nodig om de beschrijfbare master te volgen. Daarom hebben we ondersteuning voor HAProxy en Keepalive toegevoegd bovenop de PostgreSQL-clusters. Hierdoor kunnen onze PostgreSQL-gebruikers een volledige stack met hoge beschikbaarheid implementeren met ClusterControl.

Vanaf het subtabblad Load Balancer kunt u nu HAProxy implementeren. Als u bekend bent met hoe ClusterControl MySQL-replicatie implementeert, is dit een zeer vergelijkbare configuratie. We installeren HAProxy op een bepaalde host, twee backends, leest op poort 3308 en schrijft op poort 3307. Het gebruikt tcp-check, in de verwachting dat een bepaalde string terugkeert. Om die string te produceren, worden de volgende stappen uitgevoerd op alle databaseknooppunten. Ten eerste is xinet.d geconfigureerd om een service uit te voeren op poort 9201 (om verwarring met MySQL-configuratie, die poort 9200 gebruikt) te voorkomen.
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDDe service voert het /usr/local/sbin/postgreschk-script uit, dat de status van PostgreSQL valideert en vertelt of een bepaalde host beschikbaar is en welk type host het is (master of slave). Als alles in orde is, wordt de door HAProxy verwachte string geretourneerd.
Net als bij MySQL zijn HAProxy-knooppunten in PostgreSQL-clusters zichtbaar in de gebruikersinterface en is de statuspagina toegankelijk:

Hier kunt u beide backends zien en controleren of alleen de master beschikbaar is voor de r/w-backend en dat alle knooppunten toegankelijk zijn via de alleen-lezen backend. U kunt ook enkele statistieken over verkeer en verbindingen krijgen.
HAProxy helpt de hoge beschikbaarheid te verbeteren, maar het kan een single point of failure worden. We moeten een stap verder gaan en redundantie configureren met behulp van Keepalive.

Onder Beheren -> Load balancer -> Keepalive, kies je de HAProxy-hosts die je wilt gebruiken en Keepalive zal er bovenop worden geïmplementeerd met een virtueel IP-adres dat is gekoppeld aan de interface van je keuze.
Vanaf nu moet alle connectiviteit naar de VIP gaan, die wordt gekoppeld aan een van de HAProxy-knooppunten. Als dat knooppunt uitvalt, haalt Keepalived de VIP naar dat knooppunt en brengt het naar een ander HAProxy-knooppunt.
Dat is het voor de functies voor taakverdeling die zijn geïntroduceerd in ClusterControl 1.5. Probeer ze en laat ons weten hoe je