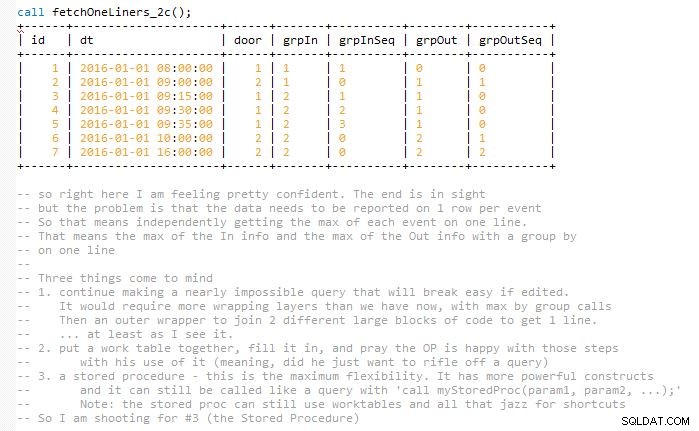
Dit streeft ernaar om de oplossing gemakkelijk onderhoudbaar te houden zonder de laatste vraag in één keer af te ronden, wat in mijn gedachten bijna verdubbeld zou zijn. Dit komt omdat de resultaten overeen moeten komen en op één rij moeten worden weergegeven met overeenkomende In- en Uit-gebeurtenissen. Dus uiteindelijk gebruik ik een paar werktafels. Het wordt geïmplementeerd in een opgeslagen procedure.
De opgeslagen procedure gebruikt verschillende variabelen die worden ingebracht met een cross join . Beschouw de cross join slechts als een mechanisme om variabelen te initialiseren. De variabelen worden veilig bewaard, dus ik geloof, in de geest van deze document
vaak verwezen in variabele queries. De belangrijke onderdelen van de referentie zijn de veilige behandeling van variabelen op een regel, waardoor ze worden ingesteld voordat andere kolommen ze gebruiken. Dit wordt bereikt door de greatest() en least() functies die een hogere prioriteit hebben dan variabelen die worden ingesteld zonder het gebruik van die functies. Merk ook op dat coalesce() wordt vaak voor hetzelfde doel gebruikt. Als het gebruik ervan vreemd lijkt, zoals het nemen van de grootste van een getal waarvan bekend is dat het groter is dan 0, of 0, dan is dat weloverwogen. Bewust bij het afdwingen van de prioriteitsvolgorde van variabelen die worden ingesteld.
De kolommen in de zoekopdracht hebben de naam dummy2 enz. zijn kolommen waarvan de uitvoer niet werd gebruikt, maar die werden gebruikt om variabelen in te stellen binnen, laten we zeggen, de greatest() of een ander. Dit werd hierboven vermeld. Uitvoer zoals 7777 was een tijdelijke aanduiding in het 3e slot, omdat er een waarde nodig was voor de if() dat werd gebruikt. Dus negeer dat allemaal.
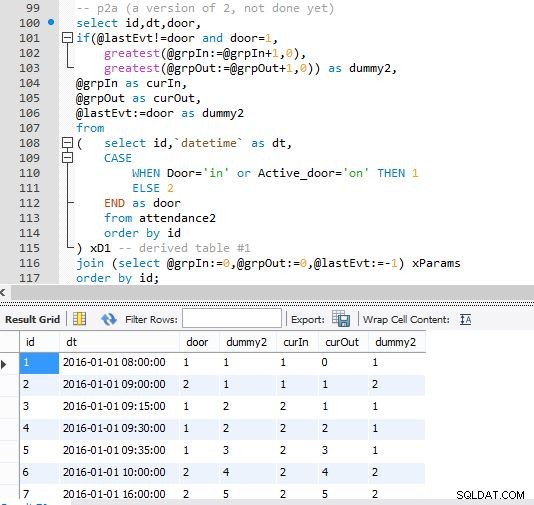
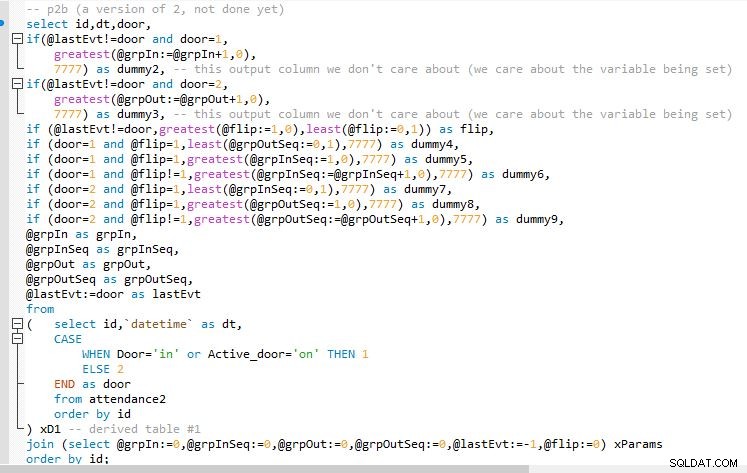
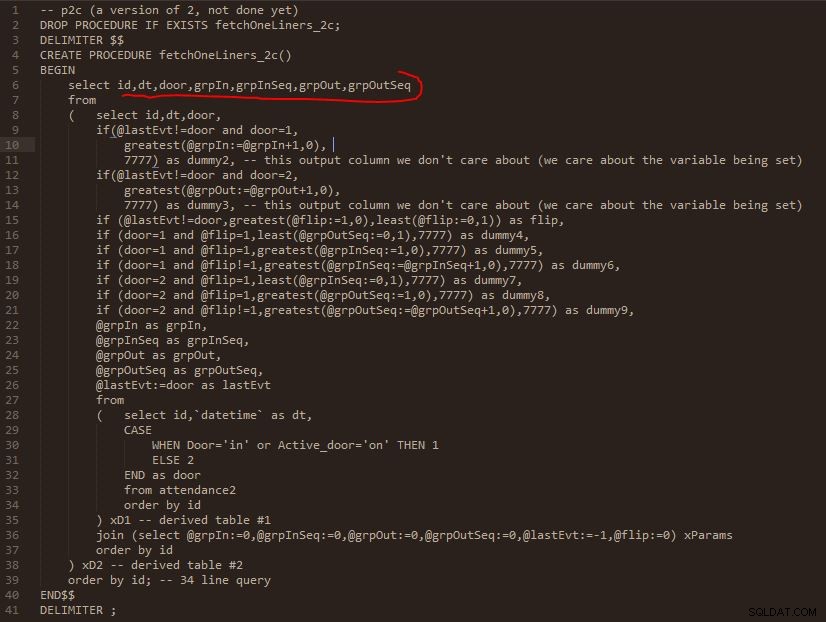
Ik heb verschillende schermafbeeldingen van de code toegevoegd terwijl deze laag voor laag vorderde om u te helpen de uitvoer te visualiseren. En hoe deze iteraties van ontwikkeling langzaam in de volgende fase worden gevouwen om uit te breiden op de vorige.
Ik weet zeker dat mijn collega's dit in één vraag zouden kunnen verbeteren. Ik had het zo kunnen afmaken. Maar ik denk dat het zou hebben geleid tot een verwarrende puinhoop die zou breken als je hem aanraakte.
Schema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Opgeslagen procedure:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Testen:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Dit is het einde van het antwoord. Het onderstaande is voor een visualisatie door een ontwikkelaar van de stappen die hebben geleid tot het voltooien van de opgeslagen procedure.
Ontwikkelingsversies die tot het einde leidden. Hopelijk helpt dit bij de visualisatie, in plaats van alleen maar een verwarrend stuk code van gemiddelde grootte te laten vallen.
Stap A
Stap B
Stap B-uitvoer

Stap C
Stap C uitvoer