Inleiding
In dit artikel bespreken we hoe verschillende typen indexen in voor geheugen geoptimaliseerde tabellen van SQL Server de prestaties beïnvloeden. We zullen voorbeelden onderzoeken van hoe verschillende indextypen de prestaties van voor geheugen geoptimaliseerde tabellen kunnen beïnvloeden.
Om de onderwerpdiscussie gemakkelijker te maken, zullen we een vrij groot voorbeeld gebruiken. Voor de eenvoud bevat dit voorbeeld verschillende replica's van een enkele tabel, waartegen we verschillende query's zullen uitvoeren. Deze replica's gebruiken verschillende indexen of helemaal geen indexen (behalve natuurlijk de primaire sleutels - PK's).
Houd er rekening mee dat het eigenlijke doel van dit artikel niet is om de prestaties tussen op schijf gebaseerde en voor geheugen geoptimaliseerde tabellen in SQL Server als zodanig te vergelijken. Het doel is om te onderzoeken hoe indexen de prestaties in voor geheugen geoptimaliseerde tabellen beïnvloeden. Om een volledig beeld van de experimenten te krijgen, worden echter ook timings gegeven voor de corresponderende schijfgebaseerde tabelquery's en worden de versnellingen berekend met de meest optimale configuratie van schijfgebaseerde tabellen als basislijnen.
Scenario
Voorbeeldgegevens voor ons scenario zijn gebaseerd op een enkele tabel die als volgt is gedefinieerd:
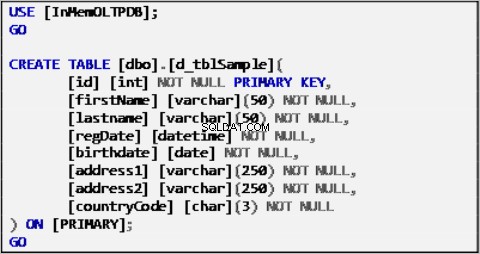
Lijst 1:voorbeeldgegevensbrontabel.
De bovenstaande tabel is gevuld met voorbeeldgegevens en zal fungeren als gegevensbron voor de rest van de tabellen.
Dus, op basis van de bovenstaande tabel, maken we de volgende 9 tabelvariaties en vullen ze met dezelfde voorbeeldgegevens:
- 3 op schijf gebaseerde tabellen:
- d_tblSample1
- Geclusterde index in de kolom "id" - primaire sleutel (PK)
- d_tblSample2
- Geclusterde index op de "id" kolom (PK)
- Niet-geclusterde index in de kolom 'countryCode'
- d_tblSample3
- Geclusterde index op de "id" kolom (PK)
- Niet-geclusterde indexen in de kolom 'regDate'
- Niet-geclusterde indexen in de kolom 'countryCode'
- d_tblSample1
- 3 voor geheugen geoptimaliseerde tabellen (set 1:Hash-indexen):
- m1_tblSample1
- Niet-geclusterde hash-index in de kolom "id" - primaire sleutel (PK)
- m1_tblSample2
- Niet-geclusterde hash-index in de "id"-kolom (PK)
- Hash-index in de kolom 'countryCode'
- m1_tblSample3
- Niet-geclusterde hash-index in de "id"-kolom (PK)
- Hash-index in de kolom "regDate"
- Hash-index in de kolom 'countryCode'
- 3 voor geheugen geoptimaliseerde tabellen (set 2:niet-geclusterde indexen):
- m2_tblSample1
- Niet-geclusterde index in de kolom "id" - primaire sleutel (PK)
- m2_tblSample2
- Niet-geclusterde index in de kolom "id" (PK)
- Niet-geclusterde index in de kolom 'countryCode'
- m2_tblSample3
- Niet-geclusterde index in de kolom "id" (PK)
- Niet-geclusterde index in de kolom 'regDate'
- Niet-geclusterde index in de kolom 'countryCode'
- m2_tblSample1
- m1_tblSample1
In de onderstaande lijsten vindt u de definities voor de bovenstaande tabellen.
De scenariologica is dat we verschillende databasebewerkingen uitvoeren tegen variaties van dezelfde tabel (maar met verschillende indexen) en kijken hoe de prestaties in elk geval worden beïnvloed.
Definities
Op schijf gebaseerde tabellen
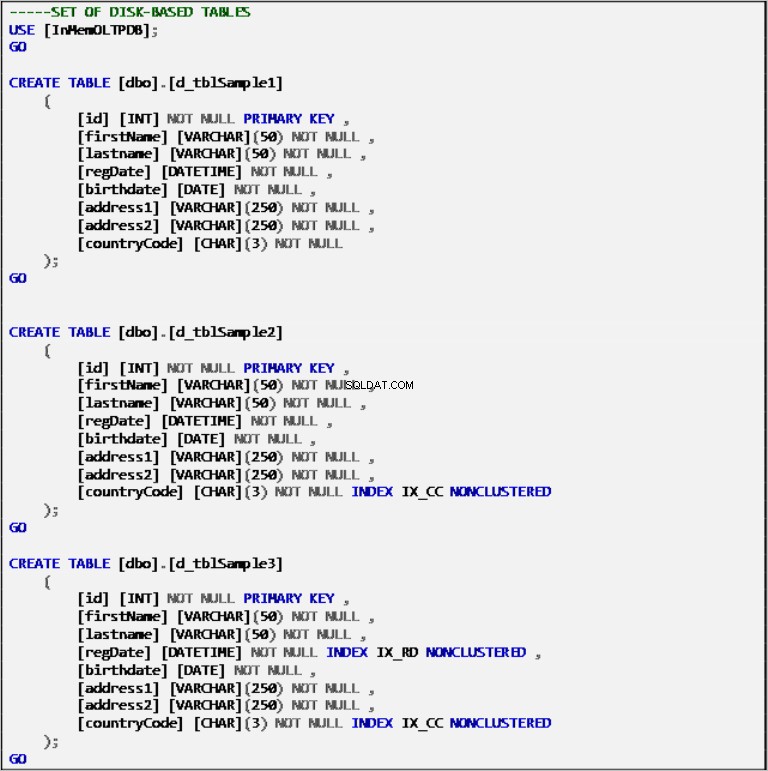
Lijst 2:Definitie van op schijf gebaseerde tabellen.
Voor geheugen geoptimaliseerde tabellen (set 1:hash-indexen)

Lijst 3:voor geheugen geoptimaliseerde tabellen - Set 1 (Hash-indexen).
Voor geheugen geoptimaliseerde tabellen (set 2:niet-geclusterde indexen)

Lijst 4:voor geheugen geoptimaliseerde tabellen - Set 2 (niet-geclusterde indexen).
Vervolgens vullen we alle bovenstaande tabellen met dezelfde voorbeeldgegevens, wat in totaal 5 miljoen records in elke tabel is.
Hier is de uitvoer van het telcommando voor elke set tabellen:
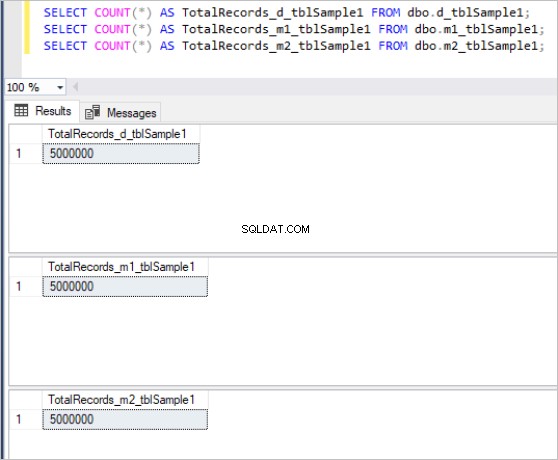
Figuur 1:Totaal aantal records voor de eerste set tabellen.
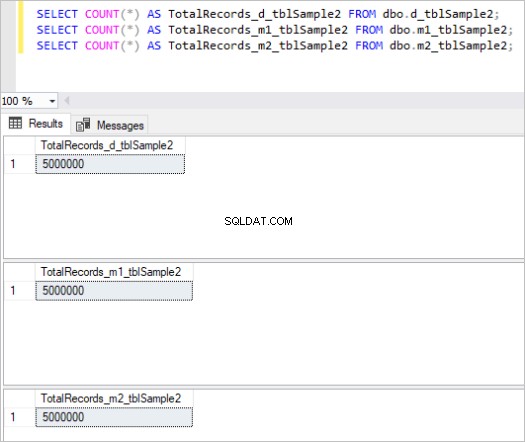
Figuur 2:Totaal aantal records voor de tweede set tabellen.
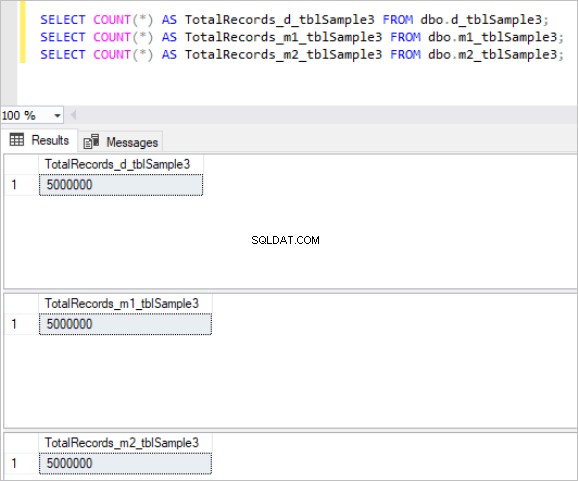
Figuur 3:Totaal aantal records voor de derde set tabellen.
Queries en scenario-uitvoeringen
Nu gaan we een reeks query's uitvoeren op de bovenstaande tabellen en kijken hoe elke tabel presteert.
Deze zoekopdrachten voeren de volgende bewerkingen uit:
- Query 1:Aggregatie (GROUP BY)
- Query 2:Index zoeken op gelijkheidspredikaten
- Query 3:Index zoeken op gelijkheid en ongelijkheidspredikaten
Het plan is om de query's als volgt uit te voeren:
Query 1 – Uitvoering tegen de volgende tabellen:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (geen index op doelkolommen)
- m2_tblSample1 (geen index op doelkolommen)
Query 2 – Uitvoering tegen de volgende tabellen:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (geen index op doelkolommen)
- m2_tblSample1 (geen index op doelkolommen)
Query 3 – Uitvoering tegen de volgende tabellen:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (geen index op doelkolommen)
- m2_tblSample1 (geen index op doelkolommen)
Opmerking :Hoewel de definitie voor de d_tblSample1 schijfgebaseerde tabel is opgenomen in de bovenstaande tabeldefinities, wordt niet gebruikt in de query's in dit artikel. De reden is dat in elk scenario de meest optimaal mogelijke configuratie voor de schijfgebaseerde tabel wordt gebruikt, omdat we willen dat onze basislijn zo snel mogelijk is wanneer we deze vergelijken met de prestaties van voor geheugen geoptimaliseerde tabellen. Hiertoe is de d_tblSample1 tabel wordt alleen ter informatie gepresenteerd.
Hieronder vindt u de T-SQL-scripts voor de drie query's samen met de mechanismen voor het meten van de uitvoeringstijd.

Lijst 5:Zoekopdracht 1 – Aggregatie (met indexen).
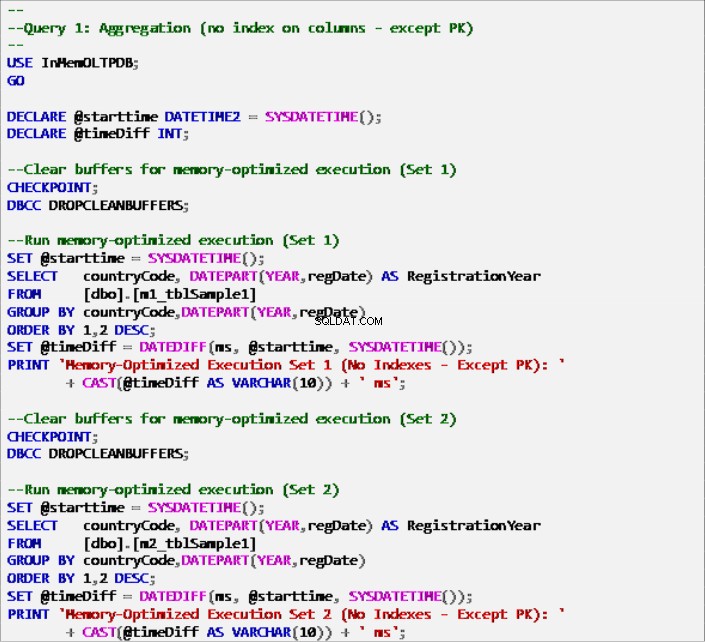
Lijst 6:Query 1 – Aggregatie (zonder indexen – Behalve primaire sleutel).
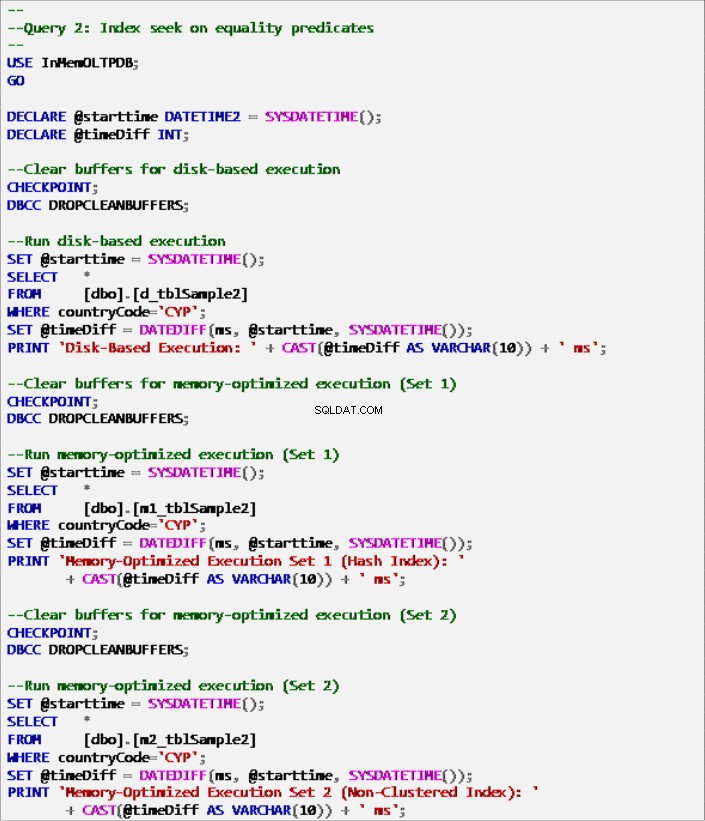
Lijst 7:Zoekopdracht 2 – Index zoeken op gelijkheidspredikaten (met indexen).

Lijst 8:Query 2 – Index zoeken op gelijkheidspredikaten (zonder indexen – behalve primaire sleutel).
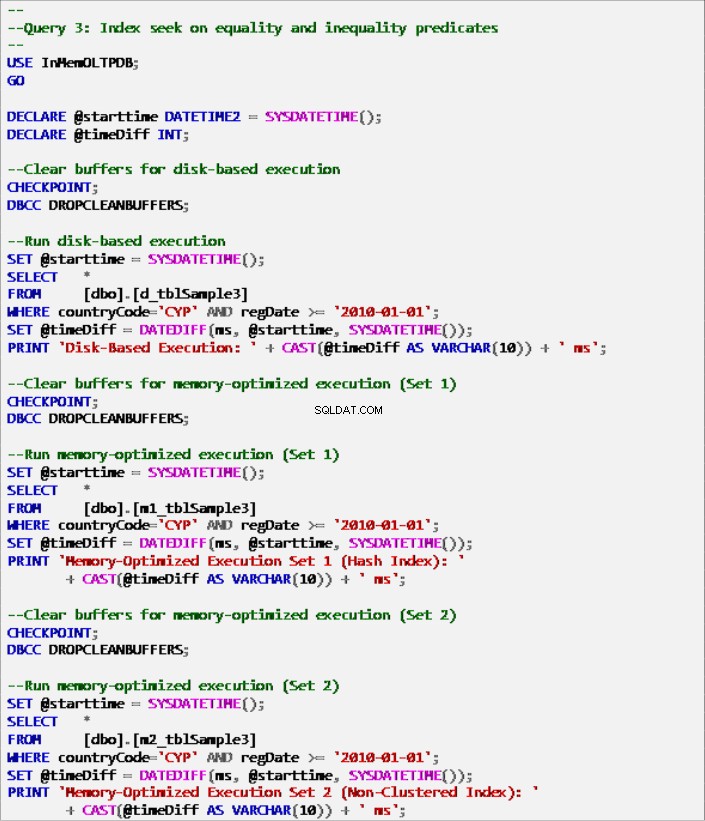
Lijst 9:Zoekopdracht 3 – Index zoeken op predikaten voor gelijkheid en ongelijkheid (met indexen).

Lijst 10:Query 3 – Index zoeken op gelijkheid en ongelijkheidspredikaten (zonder indexen – behalve primaire sleutel).
De onderstaande schermafbeeldingen tonen de uitvoer van elke uitvoering van de query:
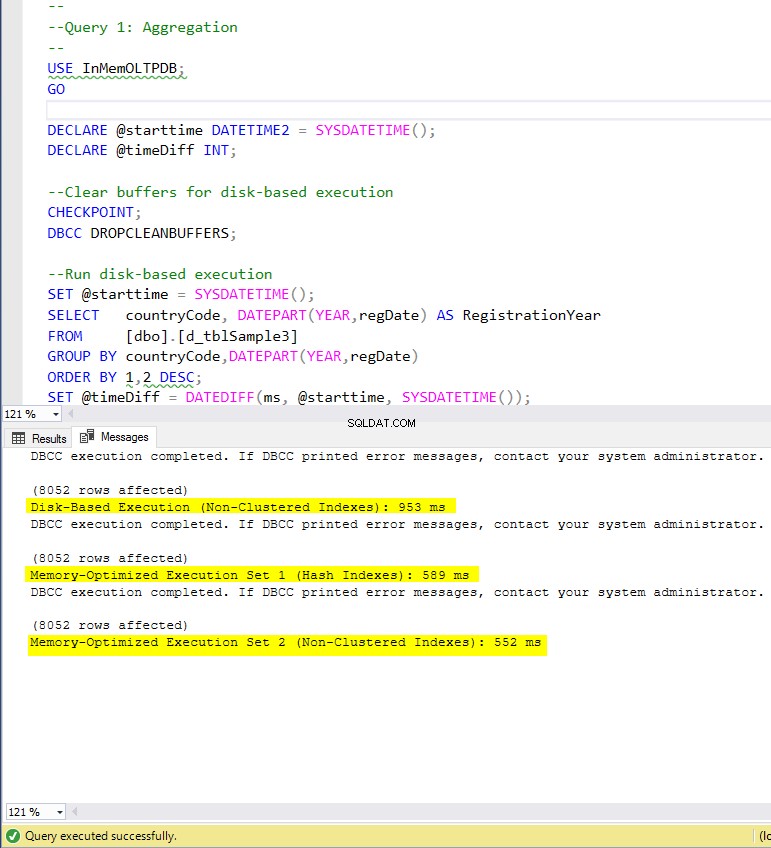
Figuur 4:Uitvoeringstijd query 1 (met indexen).
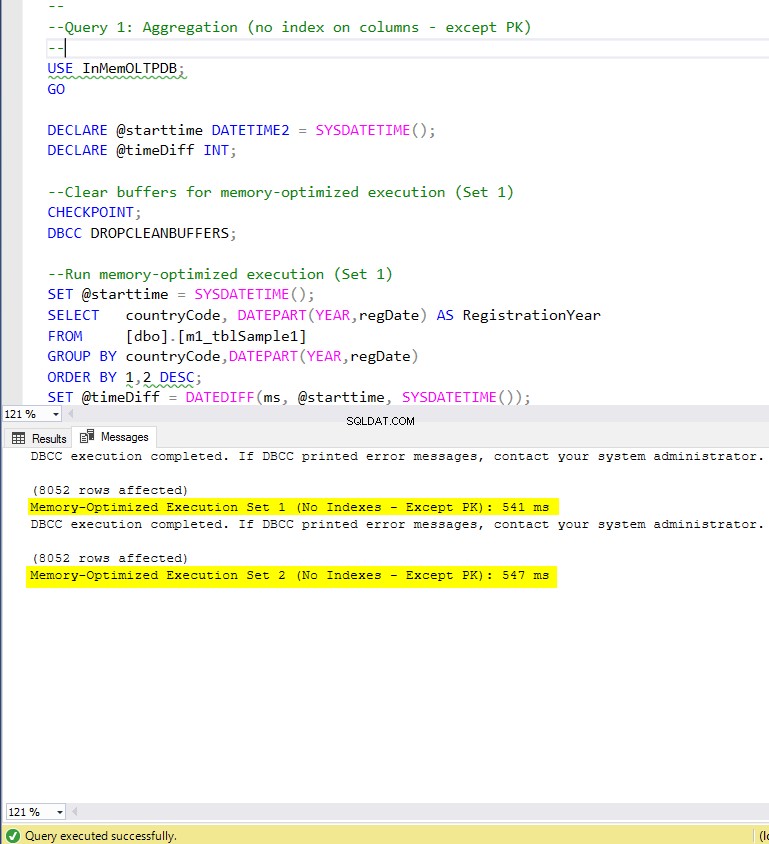
Figuur 5:Uitvoeringstijd van query 1 (zonder indexen – behalve PK).
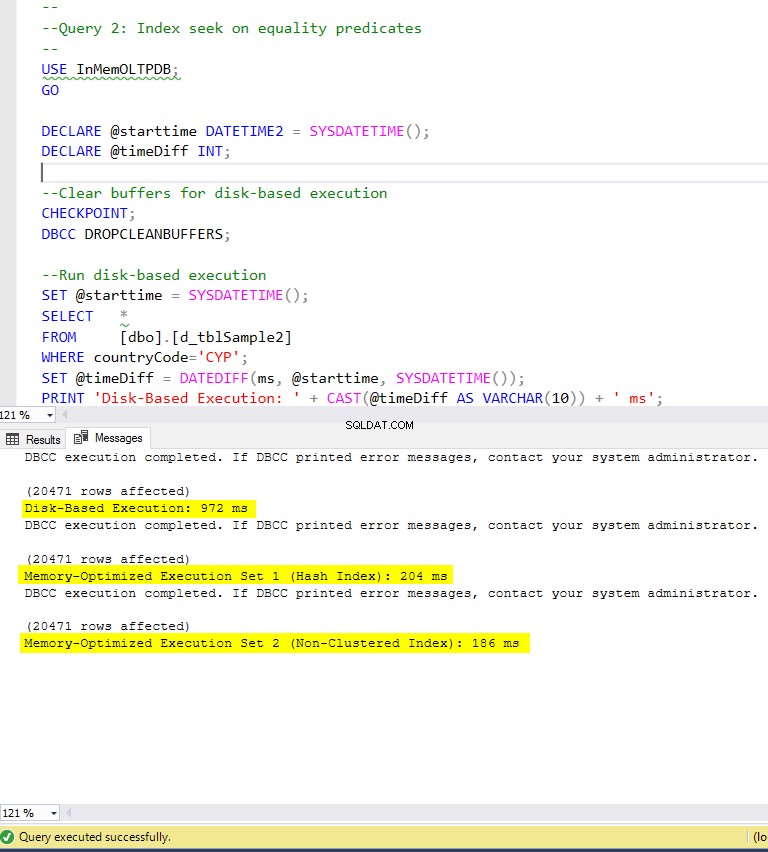
Figuur 6:Uitvoeringstijd query 2 (met indexen).
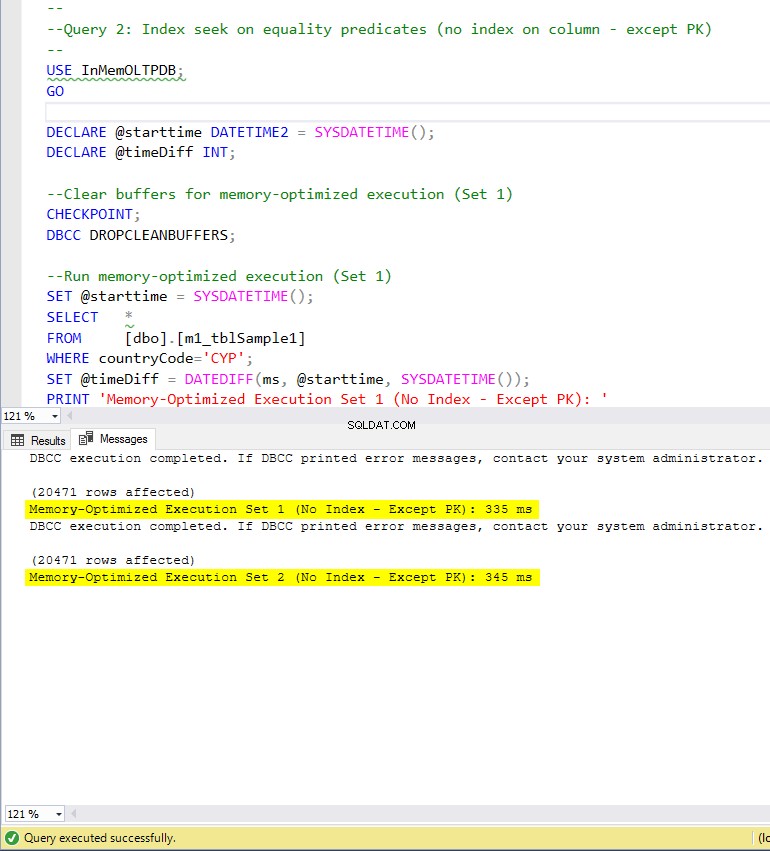
Figuur 7:Uitvoeringstijd van query 2 (zonder indexen – behalve PK).
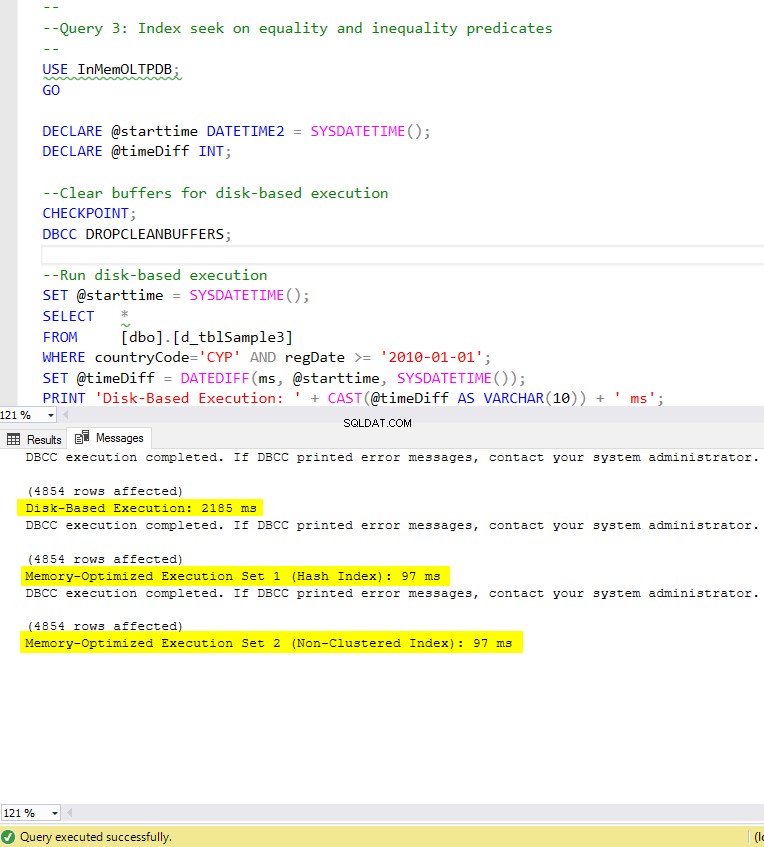
Figuur 8:Uitvoeringstijd van query 3 (met indexen).
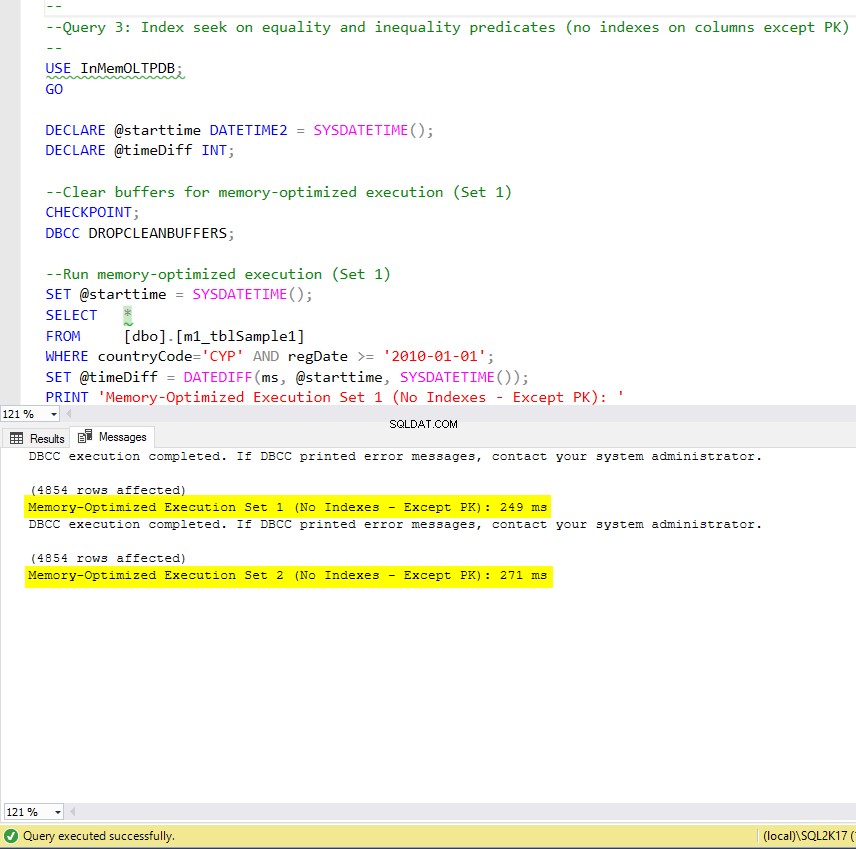
Figuur 9:Uitvoeringstijd van query 3 (zonder indexen – behalve PK).
Laten we nu de hierboven verkregen resultaten samenvatten. De volgende tabel toont de gemeten uitvoeringstijden voor alle bovenstaande zoekopdrachten en tabel/index-combinaties.
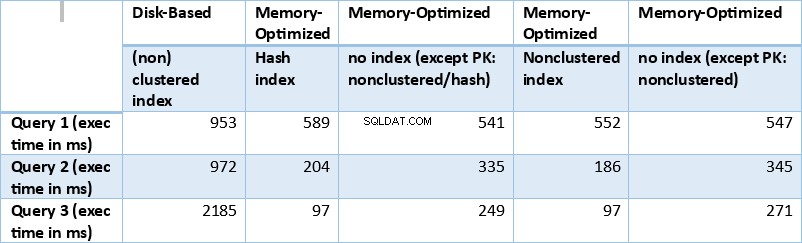
Tabel 1:Overzicht van uitvoeringstijden (ms) voor alle zoekopdrachten.
Discussie
Als we de uitvoeringsresultaten bekijken die in de bovenstaande tabel zijn samengevat, kunnen we tot bepaalde conclusies komen. Laten we elk zoekresultaat in een grafiek plotten. De onderstaande grafieken illustreren de uitvoeringstijden, evenals de snelheid van de voor geheugen geoptimaliseerde tabellen ten opzichte van de op schijf gebaseerde tabellen.
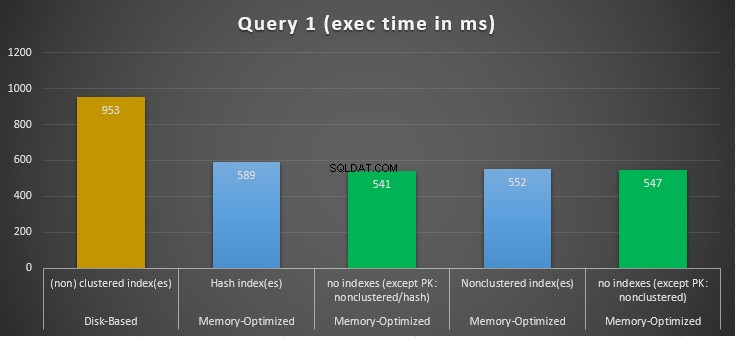
Figuur 10:Vergelijking van uitvoeringstijden van query 1.
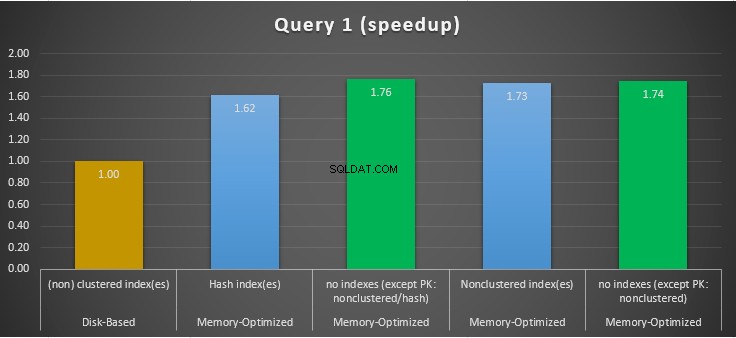
Figuur 11:Vergelijking Query 1 Speedup.
Met betrekking tot Query 1, die een GROUP BY-aggregatie was, kunnen we zien dat beide versies (indexen versus geen indexen) van voor geheugen geoptimaliseerde tabellen, bijna hetzelfde presteren met een versnelling over de schijfgebaseerde tabel (ingeschakeld met indexen) tussen
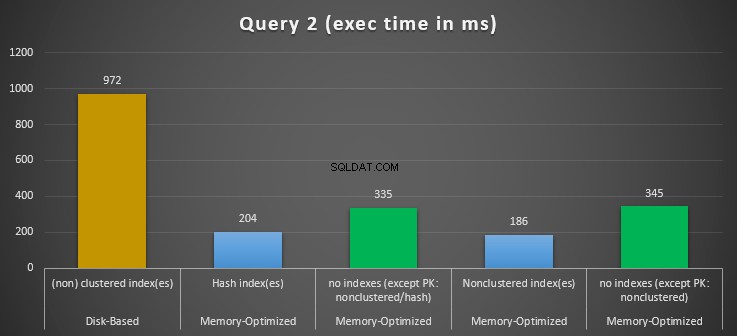
Figuur 12:Vergelijking van uitvoeringstijden van query 2.
Figuur 13:Vergelijking Query 2 Speedup.
Wat betreft Query 2, waarbij een index werd gezocht op gelijkheidspredikaten, kunnen we zien dat de voor geheugen geoptimaliseerde tabellen met indexen veel beter presteerden dan de voor geheugen geoptimaliseerde tabellen zonder indexen. Bovendien zien we dat de voor geheugen geoptimaliseerde tabel met niet-geclusterde index in de kolom die als predikaat wordt gebruikt, beter presteerde dan die met de hash-index.
Dus voor query 2 is de winnaar de voor geheugen geoptimaliseerde tabel met de niet-geclusterde index, met een algehele snelheid van 5,23 keer sneller dan op schijf gebaseerde uitvoering.
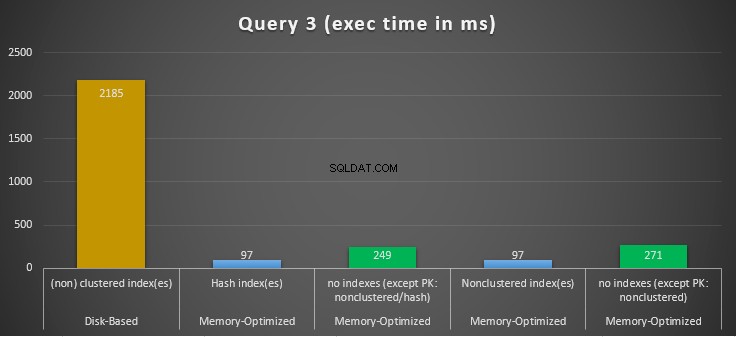
Figuur 14:Vergelijking van query 3 uitvoeringstijden.
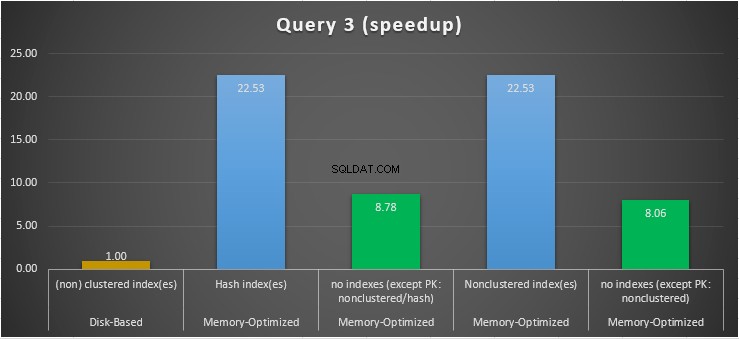
Figuur 15:Vergelijking Query 3 Speedup.
Wat betreft Query 3, waarbij een index werd gezocht op gelijkheid en ongelijkheidspredikaten gecombineerd, kunnen we zien dat de voor geheugen geoptimaliseerde tabellen met indexen veel beter presteerden dan de voor geheugen geoptimaliseerde tabellen zonder indexen. Bovendien zien we dat de voor geheugen geoptimaliseerde tabel met niet-geclusterde index in de kolom die als predikaat werd gebruikt hetzelfde presteerde als die met de hash-index.
Hiertoe kunnen we zien dat beide voor geheugen geoptimaliseerde tabellen die gebruik maken van indexen in de kolommen die als predikaten worden gebruikt, sneller presteerden dan de tabellen zonder indexen en een snelheidswinst behaalden van 22,53 keer sneller over op schijf gebaseerde uitvoering.
Conclusie
In dit artikel hebben we het gebruik van indexen in voor geheugen geoptimaliseerde tabellen in SQL Server onderzocht. We gebruikten als basislijn voor elke query de best mogelijke schijfgebaseerde tabelconfiguratie, en vervolgens vergeleken we de prestaties van drie query's met de schijfgebaseerde tabellen en vier varianten van voor geheugen geoptimaliseerde tabellen. Twee van de vier voor geheugen geoptimaliseerde tabellen gebruikten indexen (hash/niet-geclusterd) en de andere twee gebruikten geen indexen, behalve die voor de primaire sleutels.
De algemene conclusie is dat u altijd moet onderzoeken hoe indexen de prestaties beïnvloeden, niet alleen voor voor geheugen geoptimaliseerde tabellen, maar ook voor op schijf gebaseerde tabellen, en wanneer u vaststelt dat ze de prestaties verbeteren, om ze te gebruiken. De bevindingen van de voorbeelden van dit artikel laten zien dat als u gebruik maakt van de juiste indexen in voor geheugen geoptimaliseerde tabellen, u veel betere prestaties kunt bereiken voor query's die vergelijkbaar zijn met die in dit artikel in vergelijking met alleen voor geheugen geoptimaliseerde tabellen zonder indexen .
Referenties en verder lezen:
- Microsoft Docs:voor geheugen geoptimaliseerde tabellen
- Microsoft Docs:richtlijnen voor het gebruik van indexen op voor geheugen geoptimaliseerde tabellen
- Microsoft Docs:indexen op voor geheugen geoptimaliseerde tabellen
Handig hulpmiddel:
dbForge Index Manager – handige SSMS-invoegtoepassing voor het analyseren van de status van SQL-indexen en het oplossen van problemen met indexfragmentatie.