In het vorige deel van dit artikel hebben we besproken hoe u CSV-bestanden naar SQL Server kunt importeren met behulp van de BULK INSERT-instructie. We hebben de belangrijkste methodologie van het bulkinvoegproces besproken en ook de details van BATCHSIZE- en MAXERRORS-opties in scenario's. In dit deel zullen we enkele andere opties (FIRE_TRIGGERS, CHECK_CONSTRAINTS en TABLOCK) van het bulkinvoegproces in verschillende scenario's doornemen.
Scenario 1:Kunnen we triggers inschakelen in de bestemmingstabel tijdens de bulk-invoegbewerking?
Standaard worden tijdens het bulk-invoegproces de invoegtriggers die zijn opgegeven in de doeltabel niet geactiveerd, maar in sommige situaties willen we deze triggers mogelijk inschakelen. Een oplossing voor dit probleem is om de optie FIRE_TRIGGERS te gebruiken in bulkinvoeginstructies. Ik wil een opmerking toevoegen dat deze optie de prestaties van de bulk-invoegbewerking kan beïnvloeden en verminderen, omdat trigger/triggers afzonderlijke bewerkingen in de database kunnen uitvoeren. In het volgende voorbeeld zullen we dit demonstreren. In eerste instantie zullen we de parameter FIRE_TRIGGERS niet instellen en het bulk-invoegproces zal de invoegtrigger niet activeren. In het volgende T-SQL-script definiëren we een invoegtrigger voor de tabel Verkoop.
DROP TABEL INDIEN BESTAAT Verkoop MAAK TABEL [dbo].[Sales]( [Regio] [varchar](50) , [Land] [varchar](50) , [ItemType] [varchar](50) NULL, [ SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float) DROP TABEL INDIEN BESTAAT SalesLogCREATE TABLE SalesLog (OrderIDLog bigint)GOCREATE TRIGGER OrderLogIns ON SalesFOR INSERTASBEGIN SET NOCOUNT ON INSERT INTO SalesLogSELECT OrderId from\ERTend150FBULK Verkooprecords.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n'); SELECT Count(*) UIT SalesLog
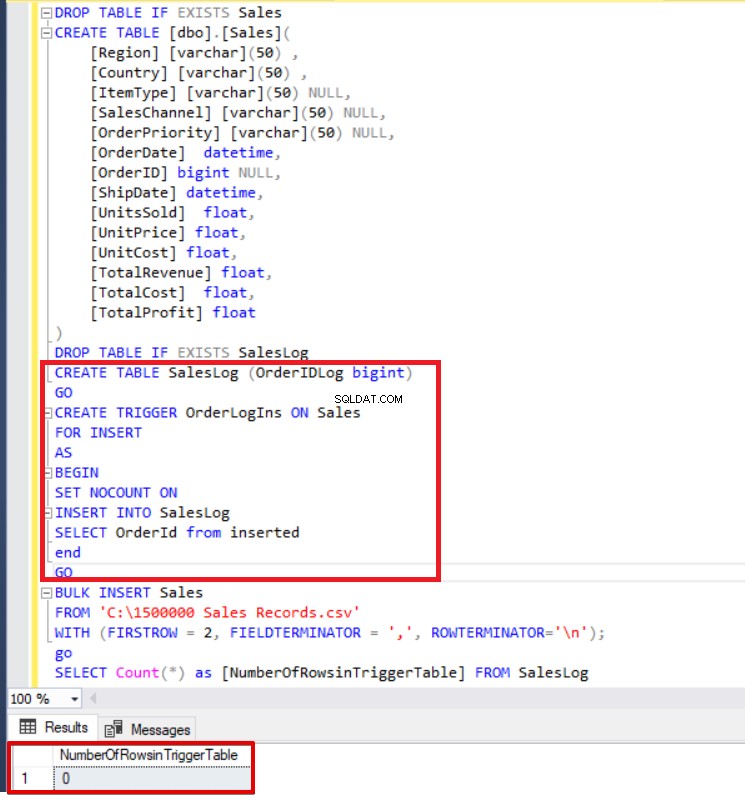
Zoals je hierboven kunt zien, is de invoegtrigger niet geactiveerd omdat we de optie FIRE_TRIGGERS niet hebben ingesteld. Nu zullen we de FIRE_TRIGGERS-optie toevoegen aan de bulk insert-instructie, zodat deze optie het mogelijk maakt om een vuurtrigger in te voegen.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n',FIRE_TRIGGERS);GOSELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog
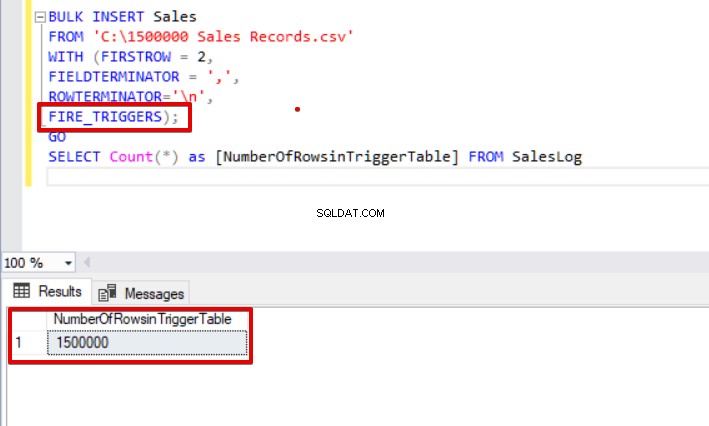
Scenario 2:Hoe kan een controlebeperking worden ingeschakeld tijdens het bulksgewijs invoegen?
Met controlebeperkingen kunnen we de gegevensintegriteit in SQL Server-tabellen afdwingen. Het doel van de beperking is om ingevoegde, bijgewerkte of verwijderde waarden te controleren op basis van hun syntaxisregelgeving. De beperking NOT NULL zorgt er bijvoorbeeld voor dat een opgegeven kolom niet kan worden gewijzigd door de NULL-waarde. Nu zullen we ons concentreren op beperkingen en interactie met bulk-inserts. Standaard worden tijdens het bulk-invoegproces alle controle- en refererende-sleutelbeperkingen genegeerd, maar deze optie heeft enkele uitzonderingen. Volgens de Microsoft-documentatie worden “UNIEKE en PRIMARY KEY-beperkingen altijd gehandhaafd. Bij het importeren in een tekenkolom waarvoor de beperking NOT NULL is gedefinieerd, voegt BULK INSERT een lege tekenreeks in als er geen waarde in het tekstbestand staat.' In het volgende T-SQL-script voegen we een controlebeperking toe aan de kolom OrderDate die de besteldatum bepaalt die groter is dan 01.01.2016.
DROP TABEL INDIEN BESTAAT Verkoop MAAK TABEL [dbo].[Sales]( [Regio] [varchar](50) , [Land] [varchar](50) , [ItemType] [varchar](50) NULL, [ SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float) WIJZIG TABEL [Sales] ADD CONSTRAINT OrderDate_CheckCHECK(OrderDate>'20160101')BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2 , FIELDTERMINATOR =',', ROWTERMINATOR='\n' );GOSELECT COUNT(*) AS [UnChekedData] FROM Sales WHERE OrderDate <'20160101'
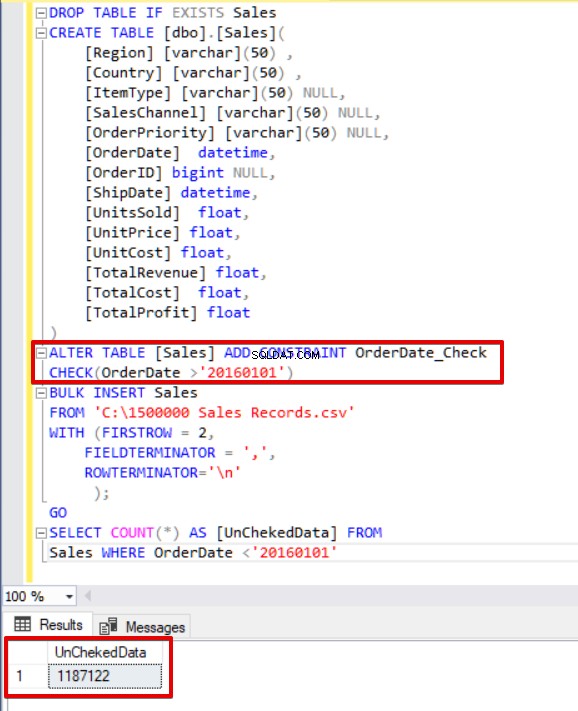
Zoals u in het bovenstaande voorbeeld kunt zien, slaat het bulk-invoegproces de controlebeperking over. SQL Server geeft echter de controlebeperking aan als niet-vertrouwd.
SELECT is_not_trusted ,* FROM sys.check_constraints waar name='OrderDate_Check'
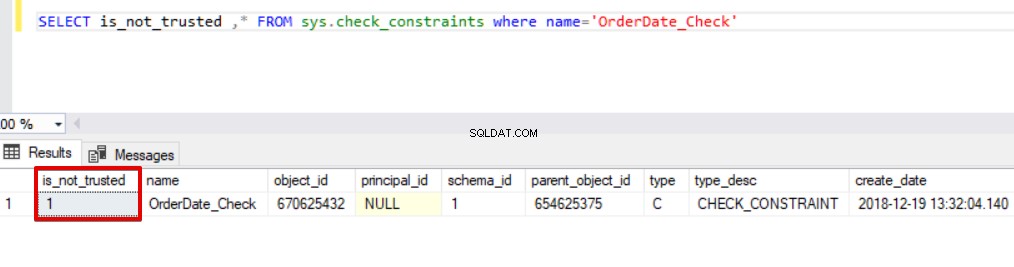
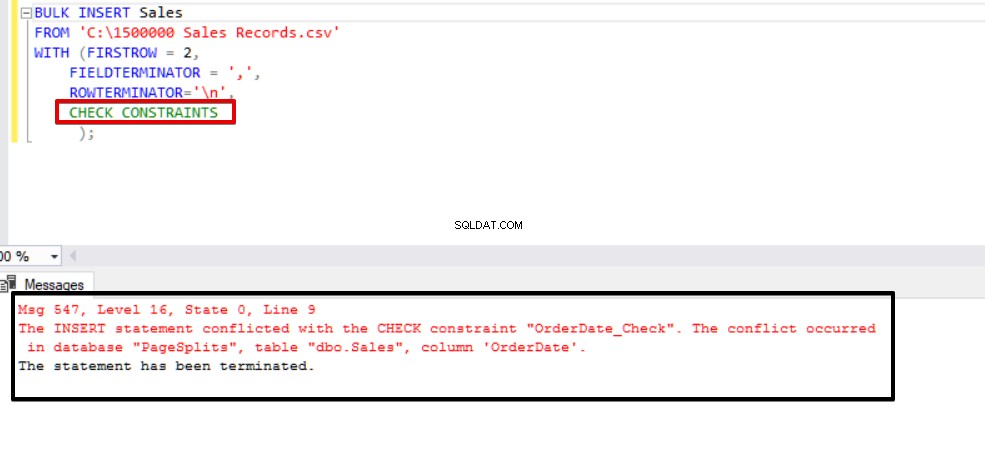
Deze waarde geeft aan dat iemand gegevens in deze kolom heeft ingevoegd of bijgewerkt door de controlebeperking over te slaan, terwijl deze kolom tegelijkertijd inconsistente gegevens kan bevatten met betrekking tot die beperking. Nu zullen we proberen de bulk insert-instructie uit te voeren met de optie CHECK_CONSTRAINTS. Het resultaat is heel eenvoudig, check constraint retourneert een fout vanwege onjuiste gegevens.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n');
Scenario 3:Hoe de prestaties van meerdere bulkinvoegingen in één bestemmingstabel verbeteren?
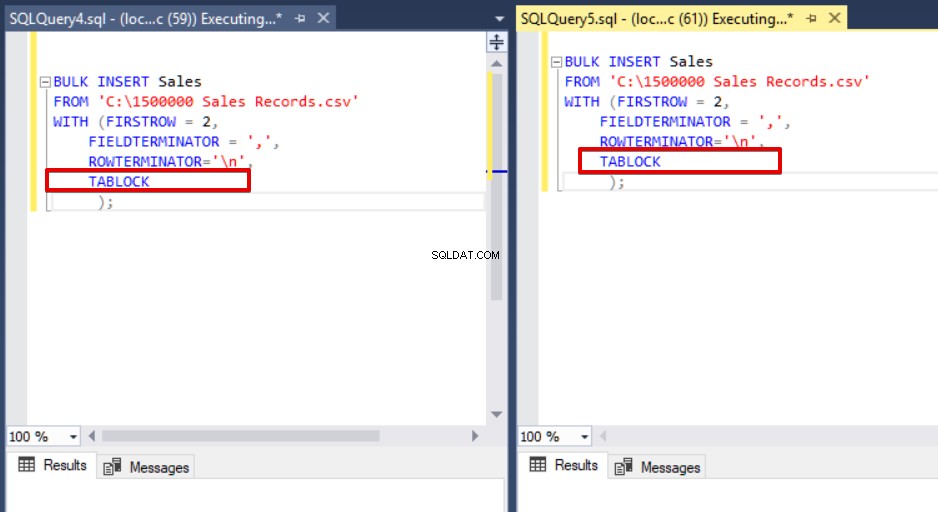
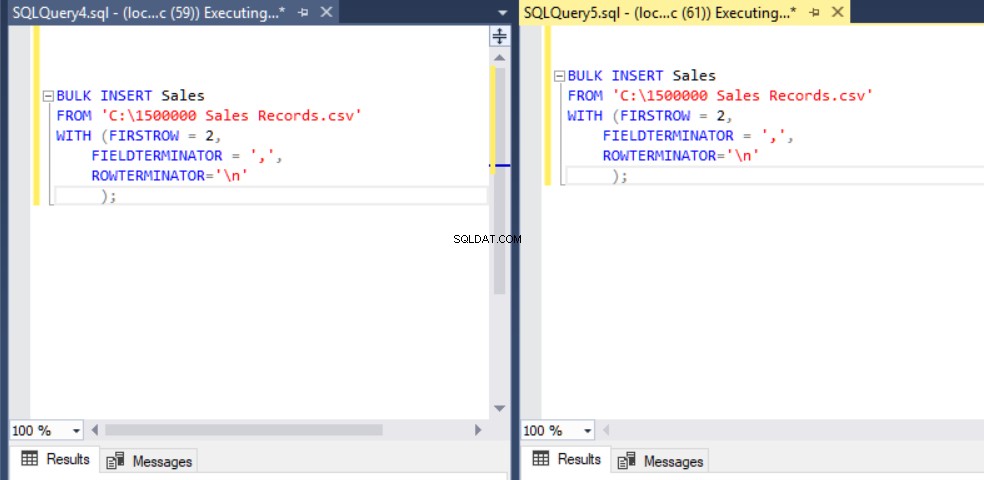
Het belangrijkste doel van het vergrendelingsmechanisme in SQL Server is het beschermen en waarborgen van de integriteit van gegevens. In het artikel Hoofdconcept van SQL Server-vergrendeling vindt u details over het vergrendelingsmechanisme. Nu zullen we ons concentreren op de vergrendelingsdetails van bulkinvoegprocessen. Als u de bulk insert-instructie uitvoert zonder de TABLELOCK-optie, wordt de vergrendeling van rijen of tabel verkregen volgens de vergrendelingshiërarchie. In sommige gevallen willen we misschien meerdere bulk-invoegprocessen uitvoeren tegen één bestemmingstabel, zodat we de bewerkingstijd van de bulk-insertie kunnen verkorten. Eerst zullen we twee bulkinsert-statements tegelijk uitvoeren en het gedrag van het vergrendelingsmechanisme analyseren. We openen twee queryvensters in SQL Server Management Studio en voeren de volgende bulkinvoeginstructies tegelijkertijd uit.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n');
Wanneer we de volgende dmv (Dynamic Management View)-query uitvoeren, die helpt om de status van het bulk-invoegproces te bewaken.
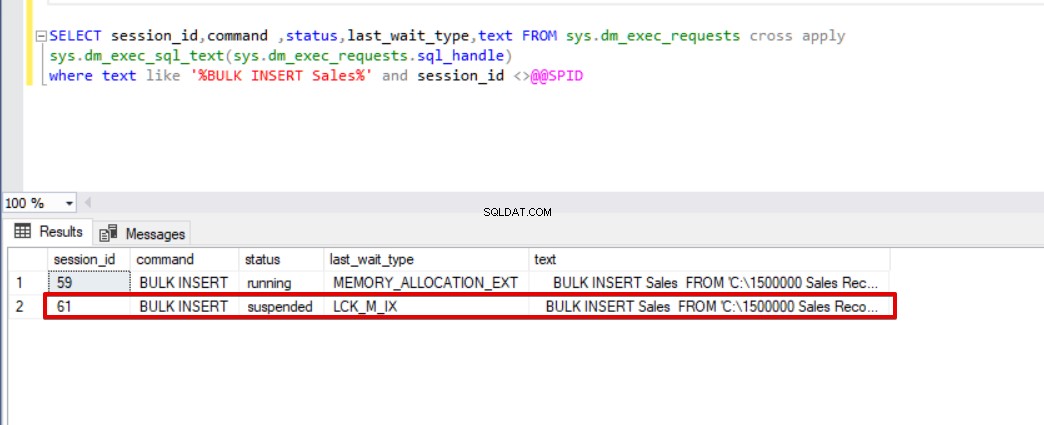
selecteer session_id, opdracht, status, last_wait_type, tekst van sys.dm_exec_requests cross toepassing sys.dm_exec_sql_text (sys.dm_exec_requests.sql_handle) waarbij tekst als '%bulk insert verkoop%' en session_id <> @@ spir
Zoals u kunt zien in de bovenstaande afbeelding, sessie 61, is de status van het bulk-invoegproces opgeschort vanwege vergrendeling. Als we het probleem verifiëren, vergrendelt sessie 59 de bestemmingstabel voor het invoegen van bulk en wacht sessie 61 op het vrijgeven van deze vergrendeling om het bulk-invoegproces voort te zetten. Nu zullen we de TABLOCK-optie toevoegen aan de bulkinvoeginstructies en de query's uitvoeren.
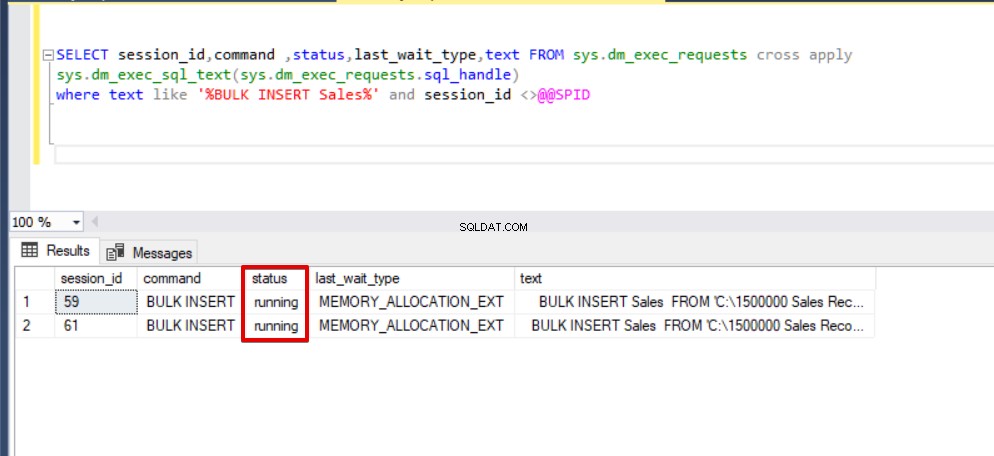
Wanneer we de dmv-controlequery opnieuw uitvoeren, kunnen we geen onderbroken bulk-invoegproces zien omdat SQL Server een speciaal vergrendelingstype gebruikt, genaamd bulk update lock (BU). Met dit slottype kunnen meerdere bulkinvoegbewerkingen tegelijkertijd tegen dezelfde tafel worden verwerkt en deze optie verkort ook de totale tijd van het bulkinvoegproces.
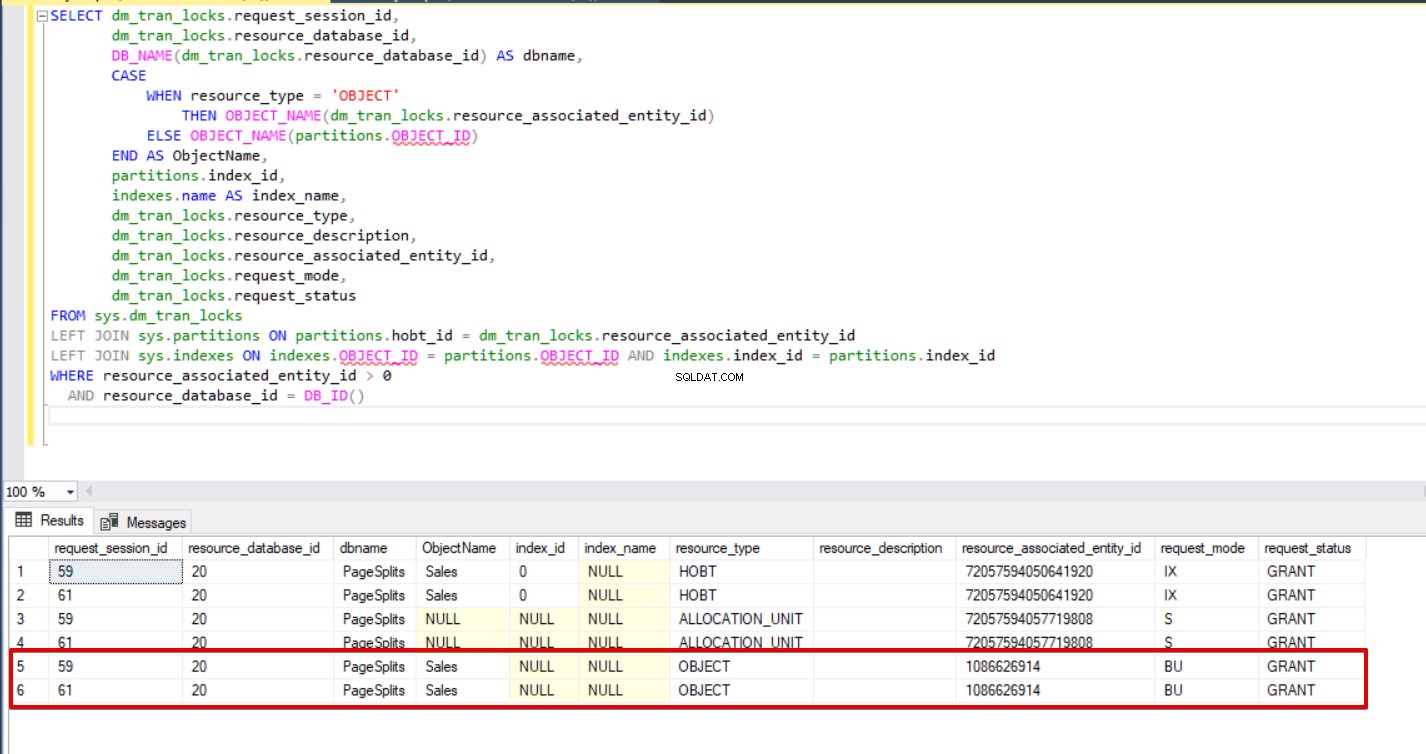
Wanneer we de volgende query uitvoeren tijdens het bulk-invoegproces, kunnen we de vergrendelingsdetails en vergrendelingstypes controleren.
SELECT dm_tran_locks.request_session_id, dm_tran_locks.resource_database_id, DB_NAME(dm_tran_locks.resource_database_id) AS dbname, CASE WHEN resource_type ='OBJECT' THEN OBJECT_sociaal_NAME(dm_tran_locks.resource_id) indexes.name AS index_name, dm_tran_locks.resource_type, dm_tran_locks.resource_description, dm_tran_locks.resource_associated_entity_id, dm_tran_locks.request_mode, dm_tran_locks.request_statusFROM sys.dm_tran_locksLEFT JOIN sys.partitions ON partitions.hobt_id =dm_tran_locks.resource_associated_entity_idLEFT JOIN sys.indexes ON indexes.OBJECT_ID =partitions .OBJECT_ID EN indexes.index_id =partitions.index_idWHERE resource_associated_entity_id> 0 AND resource_database_id =DB_ID()
Conclusie
In dit artikel hebben we alle details van bulk-invoegbewerking in SQL Server onderzocht. We noemden in het bijzonder de opdracht BULK INSERT en de instellingen en opties, en we analyseerden ook verschillende scenario's die dicht bij echte problemen liggen.
Referenties
BULK INSERT (Transact-SQL)
Vereisten voor minimaal inloggen bij bulkimport
Vergrendelingsgedrag voor bulkimport beheren
Verder lezen
Gegevens exporteren naar plat bestand met BCP Utility en gegevens importeren met Bulk Insert
Handig hulpmiddel:
dbForge Data Pump – een SSMS-invoegtoepassing voor het vullen van SQL-databases met externe brongegevens en het migreren van gegevens tussen systemen.