SQL Server 2014 CTP1 is nu een paar weken uit en je hebt waarschijnlijk nogal wat pers gezien over voor geheugen geoptimaliseerde tabellen en updatebare columnstore-indexen. Hoewel deze zeker de aandacht verdienen, wilde ik in dit bericht de nieuwe SELECT ... INTO-verbetering van het parallellisme onderzoeken. De verbetering is een van die kant-en-klare veranderingen die, zo te zien, geen significante codewijzigingen vereisen om ervan te profiteren. Mijn verkenningen zijn uitgevoerd met versie Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
Parallel SELECTEREN … IN
SQL Server 2014 introduceert parallel-enabled SELECT ... INTO voor databases en om deze functie te testen, gebruikte ik de AdventureWorksDW2012-database en een versie van de FactInternetSales-tabel met 61.847.552 rijen (ik was verantwoordelijk voor het toevoegen van die rijen; ze worden niet standaard met de database meegeleverd).
Omdat deze functie, vanaf CTP1, databasecompatibiliteitsniveau 110 vereist, heb ik voor testdoeleinden de database ingesteld op compatibiliteitsniveau 100 en de volgende query uitgevoerd voor mijn eerste test:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; De uitvoeringsduur van de query was 3 minuten en 19 seconden op mijn test-VM en het eigenlijke plan voor de uitvoering van de query was als volgt:

SQL Server gebruikte een serieel plan, zoals ik had verwacht. Merk ook op dat mijn tabel een niet-geclusterde columnstore-index had die werd gescand (ik heb deze niet-geclusterde columnstore-index gemaakt voor gebruik met andere tests, maar ik zal u later ook het uitvoeringsplan voor de geclusterde columnstore-indexquery laten zien). Het plan maakte geen gebruik van parallellisme en de Columnstore Index Scan gebruikte rijuitvoeringsmodus in plaats van batchuitvoeringsmodus.
Dus vervolgens heb ik het compatibiliteitsniveau van de database gewijzigd (en merk op dat er nog geen SQL Server 2014-compatibiliteitsniveau in CTP1 is):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Ik liet de FactInternetSales_V2-tabel vallen en voerde mijn oorspronkelijke SELECT ... INTO opnieuw uit operatie. Deze keer was de uitvoeringsduur van de query 1 minuut en 7 seconden en het werkelijke uitvoeringsplan voor de query was als volgt:
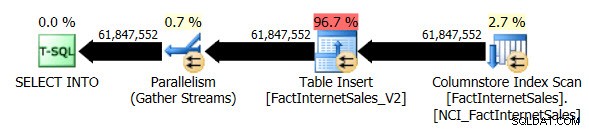
We hebben nu een parallel plan en de enige wijziging die ik moest aanbrengen was het compatibiliteitsniveau van de database voor AdventureWorksDW2012. Aan mijn test-VM zijn vier vCPU's toegewezen en het uitvoeringsplan voor query's verdeelde rijen over vier threads:

De niet-geclusterde Columnstore Index Scan, die parallellisme gebruikte, maakte geen gebruik van de batch-uitvoeringsmodus. In plaats daarvan gebruikte het de rij-uitvoeringsmodus.
Hier is een tabel met de testresultaten tot nu toe:
| Scantype | Compatibiliteitsniveau | Parallel SELECTEREN … IN | Uitvoeringsmodus | Duur |
|---|---|---|---|---|
| Niet-geclusterde Columnstore Index Scan | 100 | Nee | Rij | 3:19 |
| Niet-geclusterde Columnstore Index Scan | 110 | Ja | Rij | 1:07 |
Dus als volgende test liet ik de niet-geclusterde columnstore-index vallen en voerde de SELECT ... INTO opnieuw uit query met zowel databasecompatibiliteitsniveau 100 als 110.
De compatibiliteitsniveau 100-test duurde 5 minuten en 44 seconden en het volgende plan werd gegenereerd:
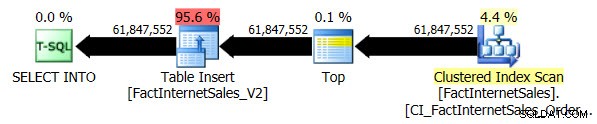
De seriële geclusterde indexscan duurde 2 minuten en 25 seconden langer dan de seriële niet-geclusterde Columnstore-indexscan.
Bij gebruik van compatibiliteitsniveau 110 duurde het uitvoeren van de query 1 minuut en 55 seconden en werd het volgende plan gegenereerd:

Net als bij de parallelle niet-geclusterde Columnstore Index Scan-test, verdeelde de parallelle Clustered Index Scan rijen over vier threads:
De volgende tabel vat deze twee bovengenoemde tests samen:
| Scantype | Compatibiliteitsniveau | Parallel SELECTEREN … IN | Uitvoeringsmodus | Duur |
|---|---|---|---|---|
| Geclusterde indexscan | 100 | Nee | Rij (N.v.t.) | 5:44 |
| Geclusterde indexscan | 110 | Ja | Rij (N.v.t.) | 1:55 |
Dus toen vroeg ik me af wat de prestaties waren van een geclusterde columnstore-index (nieuw in SQL Server 2014), dus liet ik de bestaande indexen vallen en maakte een geclusterde columnstore-index op de FactInternetSales-tabel. Ik moest ook de acht verschillende externe-sleutelbeperkingen die in de tabel waren gedefinieerd, laten vallen voordat ik de geclusterde columnstore-index kon maken.
De discussie wordt enigszins academisch, aangezien ik SELECT ... INTO . vergelijk prestaties op databasecompatibiliteitsniveaus die in de eerste plaats geen geclusterde columnstore-indexen boden - evenmin als de eerdere tests voor niet-geclusterde columnstore-indexen op databasecompatibiliteitsniveau 100 - en toch is het interessant om de algemene prestatiekenmerken te zien en te vergelijken.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Even terzijde, de operatie om de geclusterde columnstore-index op een 61.847.552 miljoen rijtabel te maken duurde 11 minuten en 25 seconden met vier beschikbare vCPU's (waarvan de operatie ze allemaal benutte), 4 GB RAM en virtuele gastopslag op OCZ Vertex SSD's. Gedurende die tijd waren de CPU's niet de hele tijd gekoppeld, maar vertoonden ze pieken en dalen (een steekproef van 60 seconden CPU-activiteit hieronder weergegeven):
Nadat de geclusterde columnstore-index was gemaakt, heb ik de twee SELECT ... INTO opnieuw uitgevoerd testen. De compatibiliteitsniveau 100-test duurde 3 minuten en 22 seconden om uit te voeren, en het plan was een serieel plan zoals verwacht (ik laat de SQL Server Management Studio-versie van het plan zien sinds de geclusterde Columnstore Index Scan, vanaf SQL Server 2014 CTP1 , wordt nog niet volledig herkend door Plan Explorer):

Vervolgens heb ik het compatibiliteitsniveau van de database gewijzigd in 110 en de test opnieuw uitgevoerd, waarbij de query deze keer 1 minuut en 11 seconden duurde en het volgende daadwerkelijke uitvoeringsplan had:

Het plan verdeelde rijen over vier threads, en net als de niet-geclusterde columnstore-index, was de uitvoeringsmodus van de geclusterde Columnstore Index Scan rij en niet batch.
De volgende tabel geeft een overzicht van alle tests in dit bericht (in volgorde van duur, laag naar hoog):
| Scantype | Compatibiliteitsniveau | Parallel SELECTEREN … IN | Uitvoeringsmodus | Duur |
|---|---|---|---|---|
| Niet-geclusterde Columnstore Index Scan | 110 | Ja | Rij | 1:07 |
| Geclusterde Columnstore Index Scan | 110 | Ja | Rij | 1:11 |
| Geclusterde indexscan | 110 | Ja | Rij (N.v.t.) | 1:55 |
| Niet-geclusterde Columnstore Index Scan | 100 | Nee | Rij | 3:19 |
| Geclusterde Columnstore Index Scan | 100 | Nee | Rij | 3:22 |
| Geclusterde indexscan | 100 | Nee | Rij (N.v.t.) | 5:44 |
Een paar opmerkingen:
- Ik weet niet zeker of het verschil tussen een parallelle
SELECT ... INTObewerking tegen een niet-geclusterde columnstore-index versus geclusterde columnstore-index is statistisch significant. Ik zou meer tests moeten doen, maar ik denk dat ik zou wachten om die uit te voeren tot RTM. - Ik kan gerust zeggen dat de parallelle
SELECT ... INTOpresteerde aanzienlijk beter dan de seriële equivalenten bij tests met geclusterde index, niet-geclusterde columnstore en geclusterde columnstore-index.
Het is vermeldenswaard dat deze resultaten voor een CTP-versie van het product zijn, en mijn tests moeten worden gezien als iets dat door RTM in gedrag zou kunnen veranderen - dus ik was minder geïnteresseerd in de op zichzelf staande duur versus hoe die duur vergeleken tussen serieel en parallel voorwaarden.
Sommige prestatiekenmerken vereisen aanzienlijke refactoring - maar voor de SELECT ... INTO verbetering, ik hoefde alleen maar het compatibiliteitsniveau van de database op te krikken om de voordelen te gaan zien, wat zeker iets is dat ik waardeer.