Wat betreft grafische uitvoeringsplannen is er slechts één pictogram voor een fysieke sortering in SQL Server:

Ditzelfde pictogram wordt gebruikt voor de drie logische sorteeroperatoren:Sorteren, Top N Sorteren en Distinct Sort:
Als we een niveau dieper gaan, zijn er vier verschillende implementaties van Sort in de uitvoeringsengine (batchsortering voor geoptimaliseerde lus-joins niet meegerekend, wat geen volledige sortering is en sowieso niet zichtbaar in plannen). Als u SQL Server 2014 gebruikt, neemt het aantal uitvoeringsengine Sort-implementaties toe tot zeven:
- CQScanSorterenNieuw
- CQScanTopSorterenNieuw
- CQScanIndexSorterenNieuw
- CQScanPartitionSortNew (alleen SQL Server 2014)
- CQScanInMemSortNieuw
- In-Memory OLTP (Hekaton) native gecompileerde procedure Top N Sort (alleen SQL Server 2014)
- In-Memory OLTP (Hekaton) native gecompileerde procedure General Sort (alleen SQL Server 2014)
In dit artikel wordt gekeken naar deze sorteerimplementaties en wanneer elk wordt gebruikt in SQL Server. Deel één behandelt de eerste vier items op de lijst.
1. CQScanSorterenNieuw
Dit is de meest algemene sorteerklasse, die wordt gebruikt wanneer geen van de andere beschikbare opties van toepassing is. Algemene sortering maakt gebruik van een werkruimtegeheugentoekenning die is gereserveerd net voordat de uitvoering van de query begint. Deze toekenning is evenredig met de kardinaliteitsschattingen en de gemiddelde rijgrootteverwachtingen, en kan niet worden verhoogd nadat de uitvoering van de query is begonnen.
De huidige implementatie lijkt gebruik te maken van een verscheidenheid aan interne merge sort (misschien binaire merge sort), overgang naar externe merge sort (met meerdere passen indien nodig) als het gereserveerde geheugen onvoldoende blijkt te zijn. Externe samenvoegsortering gebruikt fysieke tempdb ruimte voor sorteerruns die niet in het geheugen passen (algemeen bekend als sort spill). Algemene sortering kan ook worden geconfigureerd om onderscheid toe te passen tijdens het sorteren.
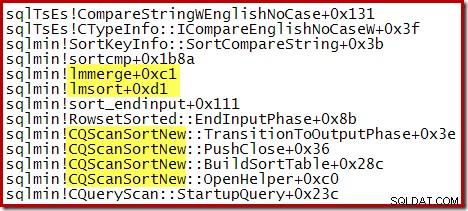
De volgende gedeeltelijke stacktracering toont een voorbeeld van de CQScanSortNew klassesorteertekenreeksen met behulp van een interne samenvoegsortering:
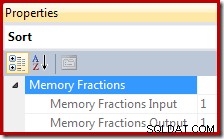
In uitvoeringsplannen biedt Sort informatie over de fractie van de totale geheugentoekenning van de querywerkruimte die beschikbaar is voor de Sort bij het lezen van records (de invoerfase), en de fractie die beschikbaar is wanneer gesorteerde uitvoer wordt verbruikt door bovenliggende planoperators (de uitvoerfase ).
De geheugentoekenningsfractie is een getal tussen 0 en 1 (waarbij 1 =100% van het toegekende geheugen) en is zichtbaar in SSMS door Sorteren te markeren en in het venster Eigenschappen te kijken. Het onderstaande voorbeeld is ontleend aan een query met slechts één sorteeroperator, zodat de volledige geheugentoekenning van de querywerkruimte beschikbaar is tijdens zowel de invoer- als de uitvoerfase:
De geheugenfracties weerspiegelen het feit dat Sort tijdens de invoerfase de algemene toekenning van het querygeheugen moet delen met gelijktijdig uitvoerende geheugenverbruikende operators eronder in het uitvoeringsplan. Evenzo moet Sort tijdens de uitvoerfase toegekend geheugen delen met gelijktijdig uitvoerende geheugenverbruikende operators erboven in het uitvoeringsplan.
De queryprocessor is slim genoeg om te weten dat sommige operators blokkeren (stop-and-go), waardoor ze effectief grenzen markeren waar de geheugentoekenning kan worden gerecycled en hergebruikt. In parallelle plannen wordt de geheugentoekenningsfractie die beschikbaar is voor een algemene sortering gelijkelijk verdeeld over threads, en kan tijdens runtime niet opnieuw worden gebalanceerd in geval van scheeftrekking (een veelvoorkomende oorzaak van morsen in parallelle sorteerplannen).
SQL Server 2012 en later bevat aanvullende informatie over de minimale werkruimtegeheugentoekenning die vereist is om geheugenverslindende planoperators te initialiseren, en de gewenste geheugentoekenning (de "ideale" hoeveelheid geheugen die naar schatting nodig is om de hele bewerking in het geheugen te voltooien). In een uitvoeringsplan na uitvoering ("actueel") is er ook nieuwe informatie over eventuele vertragingen bij het verkrijgen van de geheugentoekenning, de maximale hoeveelheid geheugen die daadwerkelijk wordt gebruikt en hoe de geheugenreservering is verdeeld over NUMA-knooppunten.
De volgende AdventureWorks-voorbeelden gebruiken allemaal een CQScanSortNew algemene sortering:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; De eerste query (een niet-onderscheiden sortering) levert het volgende uitvoeringsplan op:
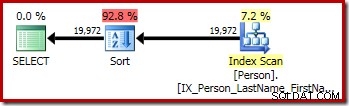
De tweede en derde (equivalente) query produceren dit plan:
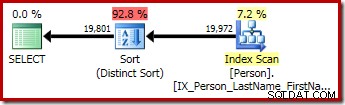
CQScanSorterenNieuw kan worden gebruikt voor zowel logische algemene sortering als logische afzonderlijke sortering.
2. CQScanTopSortNieuw
CQScanTopSortNieuw is een subklasse van CQScanSortNew gebruikt om een Top N Sort te implementeren (zoals de naam al doet vermoeden). CQScanTopSortNieuw delegeert veel van het kernwerk aan CQScanSortNew , maar wijzigt het gedetailleerde gedrag op verschillende manieren, afhankelijk van de waarde van N.
Voor N> 100, CQScanTopSortNew is in wezen gewoon een gewone CQScanSortNew sort dat automatisch stopt met het produceren van gesorteerde rijen na N rijen. Voor N <=100, CQScanTopSortNew behoudt alleen de huidige Top N-resultaten tijdens de sorteerbewerking en houdt de laagste sleutelwaarde bij die momenteel in aanmerking komt.
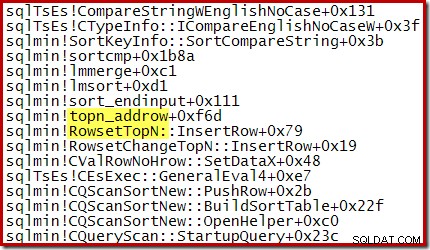
Tijdens een geoptimaliseerde Top N Sort (waarbij N <=100) bevat de call-stack bijvoorbeeld RowsetTopN terwijl we bij de algemene sortering in sectie 1 RowsetSorted . zagen :
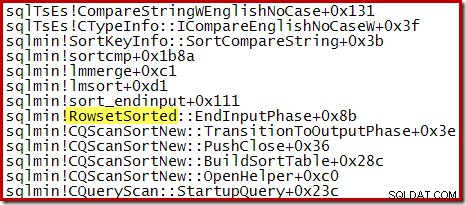
Voor een Top N Sort waarbij N> 100 is de call-stack in hetzelfde uitvoeringsstadium hetzelfde als de algemene sortering die eerder is gezien:
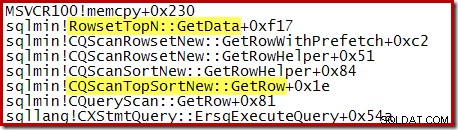
Merk op dat de CQScanTopSortNew klassenaam komt niet voor in een van die stacktraces. Dit komt simpelweg door de manier waarop subclassificatie werkt. Op andere momenten tijdens het uitvoeren van deze zoekopdrachten, CQScanTopSortNew methoden (bijv. Open, GetRow en CreateTopNTable) verschijnen expliciet op de call-stack. Als voorbeeld is het volgende genomen op een later moment tijdens het uitvoeren van de query en toont de CQScanTopSortNew klasnaam:
Top N Sort en de Query Optimizer
De query-optimizer weet niets over Top N Sort, dat alleen een operator voor de uitvoeringsengine is. Wanneer de optimizer een uitvoerstructuur produceert met een fysieke Top-operator direct boven een (niet-onderscheiden) fysieke Sort, kan een herschrijving na optimalisatie de twee fysieke bewerkingen samenvouwen tot één Top N Sort-operator. Zelfs in het geval van N> 100 vertegenwoordigt dit een besparing over het passeren van rijen, iteratief tussen een Sort-uitvoer en een Top-invoer.
De volgende query gebruikt een aantal ongedocumenteerde traceervlaggen om de uitvoer van de optimalisatie en de herschrijving na de optimalisatie in actie te laten zien:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); De outputboom van de optimizer toont afzonderlijke fysieke Top- en Sort-operators:
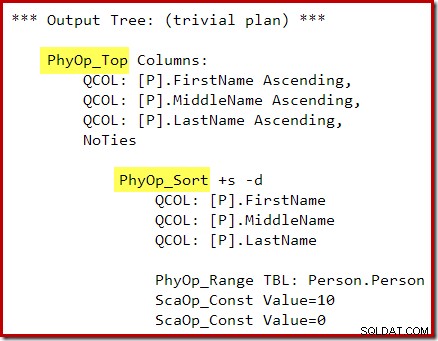
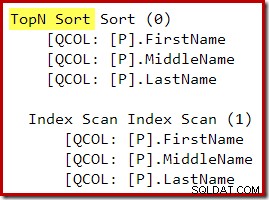
Na de herschrijving na de optimalisatie zijn de Top en Sort samengevouwen tot één Top N Sort:
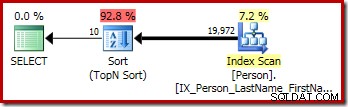
Het grafische uitvoeringsplan voor de T-SQL-query hierboven toont de enkele Top N Sort-operator:
Breaking the Top N Sort herschrijven
De herschrijving van Top N Sort na optimalisatie kan alleen een aangrenzende Top en niet-onderscheiden Sort samenvouwen tot een Top N Sort. Door DISTINCT (of de equivalente GROUP BY-clausule) aan de bovenstaande query toe te voegen, wordt de Top N Sort-herschrijving voorkomen:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Het uiteindelijke uitvoeringsplan voor deze query bevat afzonderlijke operators Top en Sort (Distinct Sort):
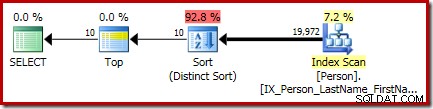
De sortering daar is de algemene CQScanSortNew klasse die in de verschillende modus wordt uitgevoerd, zoals eerder in sectie 1 is gezien.
Een tweede manier om het herschrijven naar een Top N Sort te voorkomen, is door een of meer extra operators tussen de Top en de Sort te introduceren. Bijvoorbeeld:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; De uitvoer van de query-optimizer heeft nu een bewerking tussen de Top en de Sort, dus een Top N Sort wordt niet gegenereerd tijdens de herschrijffase na de optimalisatie:
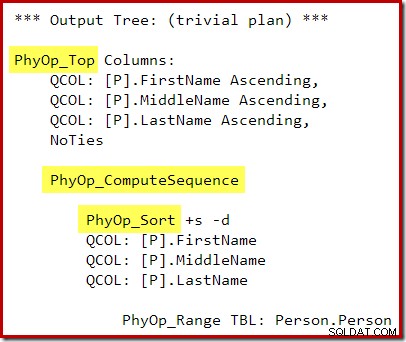
Het uitvoeringsplan is:

De rekenreeks (geïmplementeerd als twee segmenten en een reeksproject) tussen de Top en Sort voorkomt dat de Top en Sort samenvouwen tot een enkele Top N Sort-operator. Uiteraard worden met dit plan nog steeds de juiste resultaten behaald, maar de uitvoering kan iets minder efficiënt zijn dan met de gecombineerde Top N Sort-operator.
3. CQScanIndexSorterenNieuw
CQScanIndexSorterenNieuw wordt alleen gebruikt voor het sorteren in bouwplannen voor de DDL-index. Het hergebruikt enkele van de algemene sorteerfaciliteiten die we al hebben gezien, maar voegt specifieke optimalisaties toe voor het invoegen van indexen. Het is ook de enige sorteerklasse die dynamisch meer geheugen kan opvragen nadat de uitvoering is begonnen.
Kardinaliteitsschatting is vaak nauwkeurig voor een indexbouwplan omdat het totale aantal rijen in de tabel meestal een bekende hoeveelheid is. Dat wil niet zeggen dat geheugentoekenningen voor het maken van plattegronden van indexen altijd nauwkeurig zullen zijn; het maakt het alleen iets minder gemakkelijk om te demonstreren. Het volgende voorbeeld gebruikt dus een ongedocumenteerde, maar redelijk bekende uitbreiding van het UPDATE STATISTICS-commando om de optimizer voor de gek te houden door te denken dat de tabel waarop we een index bouwen slechts één rij heeft:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Het uitvoeringsplan na de uitvoering ("werkelijke") voor de indexopbouw geeft geen waarschuwing weer voor een gemorste sortering (wanneer uitgevoerd op SQL Server 2012 of later) ondanks de schatting van 1 rij en de 19.972 rijen die daadwerkelijk zijn gesorteerd:
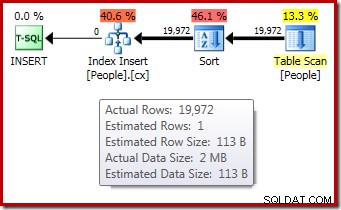
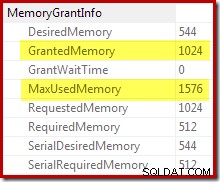
Bevestiging dat de initiële geheugentoekenning dynamisch werd uitgebreid, komt door te kijken naar de eigenschappen van de root-iterator. De query kreeg aanvankelijk 1024 KB geheugen, maar nam uiteindelijk 1576 KB in beslag:
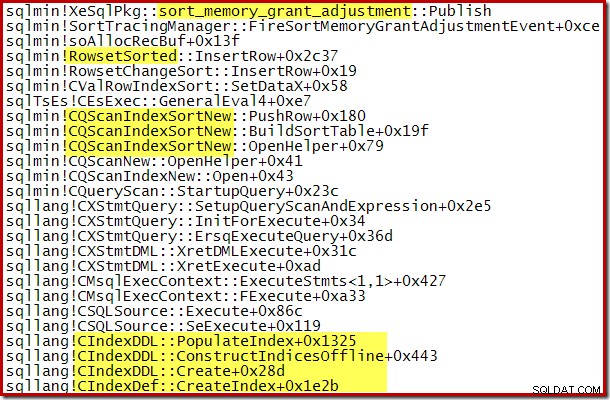
De dynamische toename van het toegekende geheugen kan ook worden gevolgd met behulp van het Debug-kanaal Extended Event sort_memory_grant_adjustment. Deze gebeurtenis wordt gegenereerd telkens wanneer de geheugentoewijzing dynamisch wordt verhoogd. Als deze gebeurtenis wordt gecontroleerd, kunnen we een stacktracering vastleggen wanneer deze wordt gepubliceerd, hetzij via Extended Events (met een onhandige configuratie en een traceringsvlag) of via een bijgevoegde debugger, zoals hieronder:
Dynamische geheugentoekenningsuitbreiding kan ook helpen bij parallelle indexopbouwplannen waarbij de verdeling van rijen over threads ongelijk is. De hoeveelheid geheugen die op deze manier kan worden verbruikt, is echter niet onbeperkt. SQL Server controleert elke keer dat een uitbreiding nodig is om te zien of het verzoek redelijk is gezien de middelen die op dat moment beschikbaar zijn.
Enig inzicht in dit proces kan worden verkregen door de niet-gedocumenteerde traceringsvlag 1504 in te schakelen, samen met 3604 (voor berichtuitvoer naar de console) of 3605 (uitvoer naar het SQL Server-foutlogboek). Als het indexopbouwplan parallel is, is alleen 3605 effectief omdat parallelle werknemers geen traceerberichten cross-thread naar de console kunnen sturen.
Het volgende gedeelte van de traceeruitvoer is vastgelegd tijdens het bouwen van een redelijk grote index op een SQL Server 2014-instantie met beperkt geheugen:
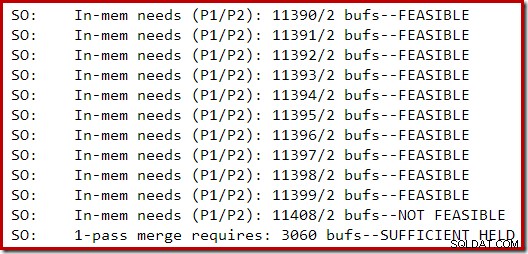
Geheugenuitbreiding voor de sortering ging door totdat het verzoek als onhaalbaar werd beschouwd, waarna werd vastgesteld dat er al voldoende geheugen was opgeslagen om een single-pass sortering te voltooien.
4. CQScanPartitionSorterenNieuw
Deze klassenaam zou kunnen suggereren dat dit type sortering wordt gebruikt voor gepartitioneerde tabelgegevens, of bij het bouwen van indexen op gepartitioneerde tabellen, maar geen van beide is het geval. Het sorteren van gepartitioneerde gegevens maakt gebruik van CQScanSortNew of CQScanTopSortNew zoals normaal; het sorteren van rijen voor invoeging in een gepartitioneerde index maakt doorgaans gebruik van CQScanIndexSortNew zoals te zien in sectie 3.
De CQScanPartitionSortNew sort class is alleen aanwezig in SQL Server 2014. Het wordt alleen gebruikt bij het sorteren van rijen op partitie-ID, voorafgaand aan het invoegen in een gepartitioneerde geclusterde columnstore-index . Merk op dat het alleen wordt gebruikt voor gepartitioneerde geclusterde columnstore; reguliere (niet-gepartitioneerde) geclusterde columnstore-invoegplannen profiteren niet van een sortering.
Invoegingen in een gepartitioneerde geclusterde columnstore-index hebben niet altijd een sortering. Het is een op kosten gebaseerde beslissing die afhangt van het geschatte aantal in te voegen rijen. Als de optimizer schat dat het de moeite waard is om de invoegingen op partitie te sorteren om I/O te optimaliseren, heeft de invoegoperator van de columnstore de DMLRequestSort eigenschap ingesteld op true, en een CQScanPartitionSortNew sort kan voorkomen in het uitvoeringsplan.
De demo in deze sectie gebruikt een permanente tabel met opeenvolgende nummers. Als je er geen hebt, kan het volgende script worden gebruikt om er een te maken:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); De demo zelf omvat het maken van een gepartitioneerde geclusterde columnstore-geïndexeerde tabel en het invoegen van voldoende rijen (uit de Numbers-tabel hierboven) om de optimizer te overtuigen een pre-insert partitiesortering te gebruiken:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Het uitvoeringsplan voor de invoeging toont de sortering die wordt gebruikt om ervoor te zorgen dat rijen aankomen bij de geclusterde columnstore-invoegiterator in partitie-id-volgorde:

Een call-stack vastgelegd terwijl de CQScanPartitionSortNew sortering bezig was, wordt hieronder weergegeven:
Er is nog iets interessants aan deze soort klasse. Sorteringen verbruiken normaal gesproken hun volledige invoer in hun Open-methodeaanroep. Na het sorteren geven ze de controle terug aan hun bovenliggende operator. Later begint de sortering gesorteerde uitvoerrijen één voor één te produceren op de gebruikelijke manier via GetRow-aanroepen. CQScanPartitionSortNew is anders, zoals je kunt zien in de oproepstack hierboven:het verbruikt zijn invoer niet tijdens de Open-methode - het wacht tot GetRow voor de eerste keer wordt aangeroepen door zijn ouder.
Niet elke sortering op partitie-ID die voorkomt in een uitvoeringsplan waarbij rijen worden ingevoegd in een gepartitioneerde geclusterde columnstore-index, is een CQScanPartitionSortNew soort. Als de sortering direct rechts van de columnstore index insert-operator verschijnt, is de kans groot dat het een CQScanPartitionSortNew is sorteren.
Ten slotte CQScanPartitionSortNew is een van de slechts twee sorteerklassen die de eigenschap Soft Sort zichtbaar maakt wanneer de eigenschappen van het uitvoeringsplan van de sorteeroperator worden gegenereerd met ongedocumenteerde traceringsvlag 8666 ingeschakeld:
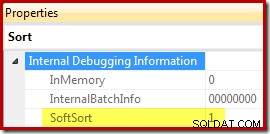
De betekenis van "zachte soort" in deze context is onduidelijk. Het wordt bijgehouden als een eigenschap in het raamwerk van de query-optimizer en lijkt waarschijnlijk gerelateerd te zijn aan geoptimaliseerde gepartitioneerde gegevensinvoegingen, maar om precies te bepalen wat het betekent, moet verder onderzoek worden gedaan. In de tussentijd kan deze eigenschap worden gebruikt om af te leiden dat een sortering is geïmplementeerd met CQScanPartitionSortNew zonder een debugger toe te voegen. De betekenis van de InMemory-eigenschapsvlag die hierboven wordt getoond, wordt behandeld in deel 2. Het doet niet geeft aan of een normale sortering in het geheugen is uitgevoerd of niet.
Samenvatting van deel één
- CQScanSorterenNieuw is de algemene sorteerklasse die wordt gebruikt als er geen andere optie van toepassing is. Het lijkt erop dat het een verscheidenheid aan interne samenvoegsortering in het geheugen gebruikt, overgaand naar externe samenvoegsortering met behulp van tempdb indien toegekend blijkt werkruimte onvoldoende te zijn. Deze klasse kan worden gebruikt voor algemene sortering en afzonderlijke sortering.
- CQScanTopSortNieuw werktuigen Top N Sort. Waar N <=100, wordt een interne merge-sortering in het geheugen uitgevoerd en wordt deze nooit gemorst naar tempdb . Alleen de huidige top n items worden tijdens het sorteren in het geheugen bewaard. Voor N> 100 CQScanTopSortNew is gelijk aan een CQScanSortNew sortering die automatisch stopt nadat N rijen zijn uitgevoerd. Een N> 100 sortering kan overlopen naar tempdb indien nodig.
- De Top N Sort die wordt gezien in uitvoeringsplannen is een herschrijving na de query-optimalisatie. Als de query-optimizer een uitvoerstructuur produceert met een aangrenzende Top en niet-onderscheiden Sort, kan deze herschrijving de twee fysieke operators samenvouwen tot één Top N Sort-operator.
- CQScanIndexSorterenNieuw wordt alleen gebruikt in DDL-plannen voor het maken van indexen. Het is de enige standaard sorteerklasse die dynamisch meer geheugen kan verwerven tijdens de uitvoering. Sorteren van indexopbouw kan in sommige omstandigheden nog steeds op schijf terechtkomen, ook wanneer SQL Server besluit dat een gevraagde geheugenuitbreiding niet compatibel is met de huidige werkbelasting.
- CQScanPartitionSortNew is alleen aanwezig in SQL Server 2014 en wordt alleen gebruikt om invoegingen in een gepartitioneerde geclusterde columnstore-index te optimaliseren. Het levert een "zachte sortering".
Het tweede deel van dit artikel gaat over CQScanInMemSortNew , en de twee In-Memory OLTP native gecompileerde opgeslagen procedure-sorteringen.