Een van de meer verbijsterende problemen om op te lossen in SQL Server kunnen problemen zijn die verband houden met geheugentoekenningen. Sommige query's hebben meer geheugen nodig dan andere om uit te voeren, op basis van welke bewerkingen moeten worden uitgevoerd (bijvoorbeeld sorteren, hash). De optimalisatieprogramma van SQL Server schat hoeveel geheugen er nodig is en de query moet de geheugentoekenning verkrijgen om te beginnen met uitvoeren. Het houdt die toekenning vast voor de duur van de uitvoering van de query - wat betekent dat als de optimizer het geheugen overschat, u gelijktijdigheidsproblemen kunt tegenkomen. Als het geheugen onderschat, kun je verspillingen in tempdb zien. Geen van beide is ideaal, en als je simpelweg te veel vragen hebt die om meer geheugen vragen dan er beschikbaar is om toe te kennen, zie je dat RESOURCE_SEMAPHORE wacht. Er zijn meerdere manieren om dit probleem aan te pakken, en een van mijn nieuwe favoriete methoden is om Query Store te gebruiken.
Instellen
We zullen een kopie van WideWorldImporters gebruiken die ik heb opgeblazen met behulp van de opgeslagen procedure DataLoadSimulation.DailyProcessToCreateHistory. De tabel Sales.Orders heeft ongeveer 4,6 miljoen rijen en de tabel Sales.OrderLines heeft ongeveer 9,2 miljoen rijen. We zullen de back-up herstellen en Query Store inschakelen, en alle oude Query Store-gegevens wissen, zodat we de statistieken voor deze demo niet wijzigen.
Herinnering:voer ALTER DATABASE
USE [master]; GO RESTORE DATABASE [WideWorldImporters] FROM DISK = N'C:\Backups\WideWorldImporters.bak' WITH FILE = 1, MOVE N'WWI_Primary' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.mdf', MOVE N'WWI_UserData' TO N'C:\Databases\WideWorldImporters\WideWorldImporters_UserData.ndf', MOVE N'WWI_Log' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.ldf', NOUNLOAD, REPLACE, STATS = 5 GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, INTERVAL_LENGTH_MINUTES = 10 ); GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE CLEAR; GO
De opgeslagen procedure die we zullen gebruiken voor het testen van query's op de bovengenoemde Orders en OrderLines-tabellen op basis van een datumbereik:
USE [WideWorldImporters]; GO DROP PROCEDURE IF EXISTS [Sales].[usp_OrderInfo_OrderDate]; GO CREATE PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO
Testen
We zullen de opgeslagen procedure uitvoeren met drie verschillende sets invoerparameters:
EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
De eerste uitvoering retourneert 1958 rijen, de tweede retourneert 267.268 rijen en de laatste retourneert meer dan 2,2 miljoen rijen. Als je naar de datumbereiken kijkt, is dit niet verrassend:hoe groter het datumbereik, hoe meer gegevens worden geretourneerd.
Omdat dit een opgeslagen procedure is, bepalen de aanvankelijk gebruikte invoerparameters het plan, evenals het toe te kennen geheugen. Als we kijken naar het daadwerkelijke uitvoeringsplan voor de eerste uitvoering, zien we geneste lussen en een geheugentoekenning van 2656 KB.
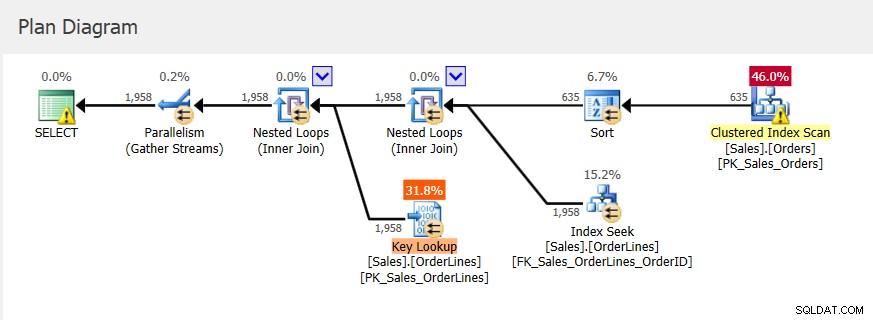
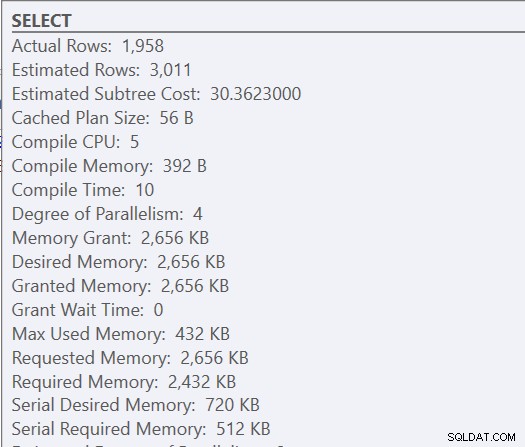
Daaropvolgende uitvoeringen hebben hetzelfde plan (want dat is in de cache opgeslagen) en dezelfde geheugentoekenning, maar we krijgen een idee dat het niet genoeg is omdat er een soortwaarschuwing is.
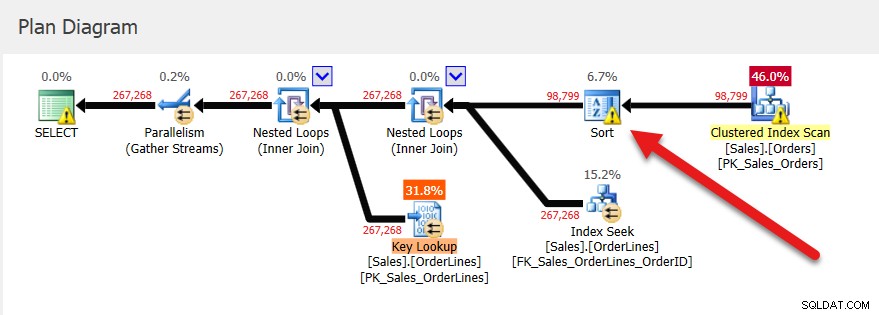
Als we in Query Store naar deze opgeslagen procedure kijken, zien we drie uitvoeringen en dezelfde waarden voor UsedKB-geheugen, of we nu kijken naar gemiddelde, minimum, maximum, laatste of standaarddeviatie. Opmerking:informatie over geheugentoekenning in Query Store wordt gerapporteerd als het aantal pagina's van 8 KB.
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], --memory grant (reported as the number of 8 KB pages) for the query plan within the aggregation interval [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE [qsq].[object_id] = OBJECT_ID(N'Sales.usp_OrderInfo_OrderDate');

Als we in dit scenario op zoek zijn naar problemen met geheugentoekenning, waarbij een plan in de cache wordt opgeslagen en opnieuw wordt gebruikt, zal Query Store ons niet helpen.
Maar wat als de specifieke query wordt gecompileerd bij uitvoering, hetzij vanwege een RECOMPILE-hint of omdat het ad-hoc is?
We kunnen de procedure wijzigen om de RECOMPILE-hint toe te voegen aan de instructie (die wordt aanbevolen boven het toevoegen van RECOMPILE op procedureniveau of het uitvoeren van de procedure MET RECOMPILE):
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate] OPTION (RECOMPILE); GO
Nu zullen we onze procedure opnieuw uitvoeren met dezelfde invoerparameters als voorheen, en de uitvoer controleren:

Merk op dat we een nieuwe query_id hebben - de querytekst is gewijzigd omdat we er OPTION (RECOMPILE) aan hebben toegevoegd - en we hebben ook twee nieuwe plan_id-waarden en we hebben verschillende geheugentoekenningsnummers voor een van onze plannen. Voor plan_id 5 is er slechts één uitvoering en de geheugentoekenningsnummers komen overeen met de initiële uitvoering - dus dat plan is voor het kleine datumbereik. De twee grotere datumbereiken genereerden hetzelfde plan, maar er is een aanzienlijke variabiliteit in de geheugentoekenningen:94.528 voor minimaal en 573.568 voor maximaal.
Als we kijken naar informatie over geheugentoekenning met behulp van de Query Store-rapporten, wordt deze variabiliteit iets anders weergegeven. Door het rapport Top Resource Consumers uit de database te openen en de metrische gegevens vervolgens te wijzigen in Memory Consumption (KB) en Avg, komt onze zoekopdracht met RECOMPILE bovenaan de lijst te staan.
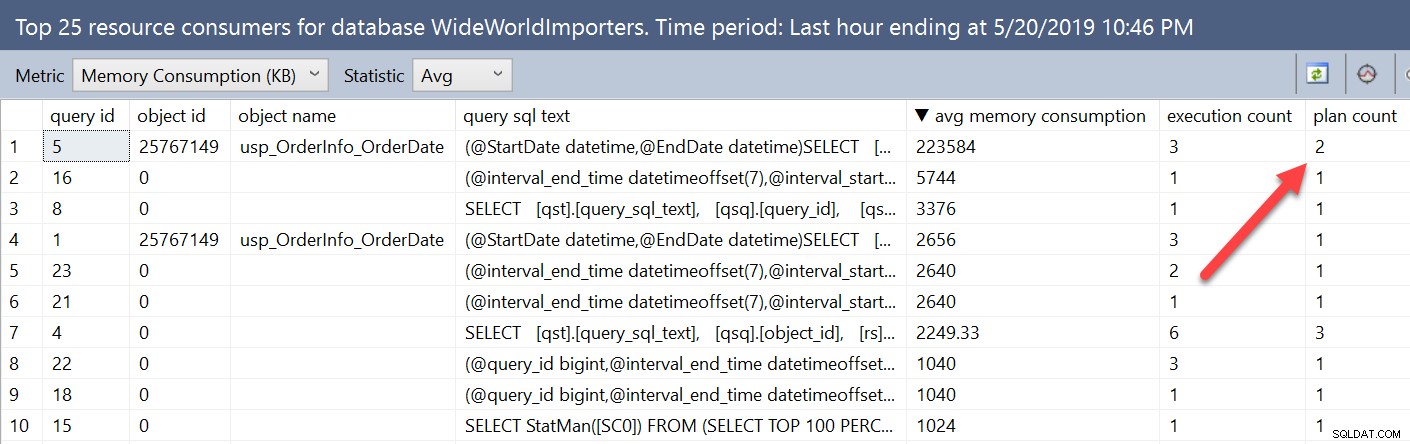
In dit venster worden statistieken geaggregeerd per query, niet per plan. De query die we rechtstreeks uitvoerden tegen de Query Store-weergaven vermeldde niet alleen de query_id maar ook de plan_id. Hier kunnen we zien dat de query twee plannen heeft, en we kunnen ze beide bekijken in het overzichtsvenster van het plan, maar de statistieken worden gecombineerd voor alle plannen in deze weergave.
De variabiliteit in geheugentoekenningen is duidelijk wanneer we rechtstreeks naar de weergaven kijken. We kunnen zoekopdrachten met variabiliteit vinden met behulp van de gebruikersinterface door de statistiek te wijzigen van Gem in StDev:
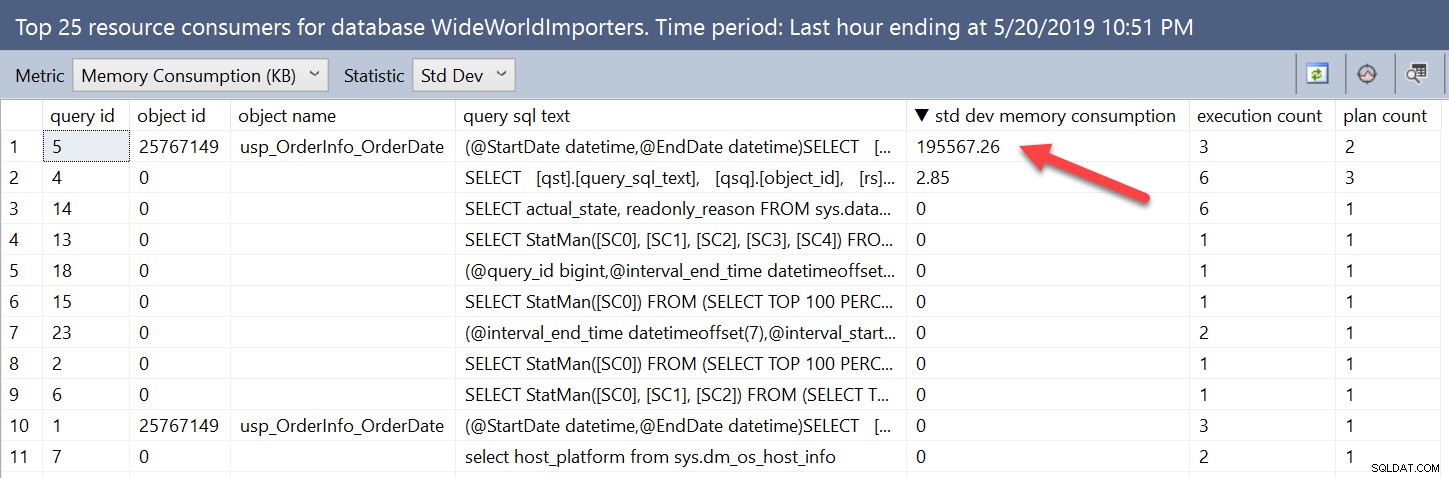
We kunnen dezelfde informatie vinden door de Query Store-weergaven op te vragen en te bestellen door stdev_query_max_used_memory aflopend. Maar we kunnen ook zoeken op basis van het verschil tussen de minimale en maximale geheugentoekenning, of een percentage van het verschil. Als we ons bijvoorbeeld zorgen zouden maken over gevallen waarin het verschil in de subsidies groter was dan 512 MB, zouden we het volgende kunnen doen:
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE ([rs].[max_query_max_used_memory]*8) - ([rs].[min_query_max_used_memory]*8) > 524288;
Degenen onder u die SQL Server 2017 uitvoeren met Columnstore-indexen, die het voordeel hebben van Memory Grant-feedback, kunnen deze informatie ook gebruiken in Query Store. We zullen eerst onze Orders-tabel wijzigen om een geclusterde Columnstore-index toe te voegen:
ALTER TABLE [Sales].[Invoices] DROP CONSTRAINT [FK_Sales_Invoices_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [FK_Sales_Orders_BackorderOrderID_Sales_Orders]; GO ALTER TABLE [Sales].[OrderLines] DROP CONSTRAINT [FK_Sales_OrderLines_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [PK_Sales_Orders] WITH ( ONLINE = OFF ); GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Orders ON [Sales].[Orders];
Vervolgens zullen we de database-combineerbaarheidsmodus instellen op 140, zodat we geheugentoekenningsfeedback kunnen gebruiken:
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140; GO
Ten slotte zullen we onze opgeslagen procedure wijzigen om OPTION (RECOMPILE) uit onze query te verwijderen en deze vervolgens een paar keer uit te voeren met de verschillende invoerwaarden:
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
Binnen Query Store zien we het volgende:

We hebben een nieuw plan voor query_id =1, dat andere waarden heeft voor de geheugentoekenningsstatistieken, en een iets lagere StDev dan we hadden met plan_id 6. Als we in het plan in Query Store kijken, zien we dat het toegang heeft tot de geclusterde Columnstore-index :
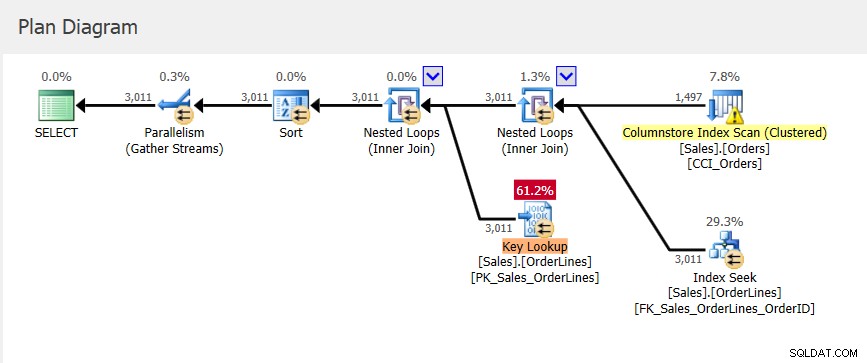
Onthoud dat het plan in Query Store het plan is dat is uitgevoerd, maar het bevat alleen schattingen. Hoewel het plan in de plancache informatie over geheugentoekenning heeft bijgewerkt wanneer geheugenfeedback optreedt, wordt deze informatie niet toegepast op het bestaande plan in Query Store.
Samenvatting
Dit is wat ik leuk vind aan het gebruik van Query Store om naar query's te kijken met variabele geheugentoekenningen:de gegevens worden automatisch verzameld. Als dit probleem zich onverwachts voordoet, hoeven we niets in te voeren om te proberen informatie te verzamelen, we hebben het al vastgelegd in Query Store. In het geval dat een query is geparametriseerd, kan het moeilijker zijn om geheugentoekenningsvariabiliteit te vinden vanwege het potentieel voor statische waarden vanwege plancaching. We kunnen echter ook ontdekken dat, als gevolg van hercompilatie, de query meerdere plannen heeft met extreem verschillende geheugentoekenningswaarden die we zouden kunnen gebruiken om het probleem op te sporen. Er zijn verschillende manieren om het probleem te onderzoeken met behulp van de gegevens die zijn vastgelegd in Query Store, en u kunt problemen zowel proactief als reactief bekijken.