Op een testtafel ziet mijn oorspronkelijke plan er als volgt uit.
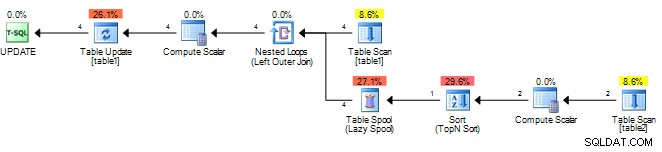
Het berekent het resultaat slechts één keer en slaat het op in een sppol en speelt dat resultaat vervolgens opnieuw af. U kunt het volgende proberen, zodat SQL Server de subquery als gecorreleerd ziet en voor elke buitenste rij opnieuw moet worden geëvalueerd.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
Voor mij geeft dat dit plan zonder de spoel.
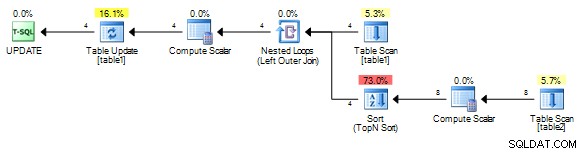
Het is belangrijk om te correleren op een uniek veld uit table1 zodat zelfs als een spoel wordt toegevoegd, deze altijd moet worden teruggekaatst in plaats van teruggespoeld (het laatste resultaat wordt opnieuw afgespeeld), omdat de correlatiewaarde voor elke rij anders zal zijn.
Als de tabellen groot zijn, zal dit traag zijn omdat het vereiste werk een product is van de twee tabelrijen (voor elke rij in table1 het moet een volledige scan uitvoeren van table2 )